

Средства синхронизации в qnx
В QNX Neutrino реализовано несколько способов синхронизации потоков. Причем только два из них (mutex и condvar) реализованы непосредственно в микроядре, остальные надстройки над этими двумя [17]:
Взаимоисключающая блокировка (mutual exclusion lock- mutex, «мютекс (мутекс)»)- это механизм обеспечивает исключительный доступ потоков к разделенным данным. Только один поток в один момент времени может владеть мютексом. Если другие потоки попытаются захватить мютекс, они становятся мютекс-заблокированными.
Если в состоянии мютекс-блокировки находится поток с приоритетом выше, чем у потока-владельца блокировки, то значение эффективного приоритета этого потока автоматически повышается до уровня высокоприоритетного заблокированного потока;
Условная переменная (condition variable, или condvar ) -предназначена для блокировки потока до тех пор, пока соблюдается некоторое условие. Это условие может быть сложным. Условные переменные всегда используются с мутекс-блокировкой для определения момента снятия мутекс-блокировки;
Барьер ‑ устанавливает точку для нескольких взаимодействующих потоков, на которой они должны остановиться и дождаться «отставших» потоков. Как только все потоки из контролируемой группы достигли барьера, они одновременно разблокируются и могут продолжить исполнение;
Ждущая блокировка – упрощенная форма совместного использования условной переменной с мутексом. В отличие от прямого применения mutex+ condvar имеет некоторые ограничения;
Блокировка чтения /записи (rwlock)-простая и удобная в использовании ‘надстройка’ над условными переменными и мутексами;
Семафор – это, можно (условно) сказать, мутекс со счетчиком. Вернее, мутекс является семафором со счетчиком, равным единице.
Большинство этих механизмов работает в пределах одного процесса, но это ограничение преодолевается путем использования механизма разделяемой памяти.
Кроме перечисленных способов синхронизацию можно осуществлять с помощью FIFO-диспетчеризации, ”родных” QNX-сообщений и атомарных операций.
Рассмотрим синхронизацию потоков на барьерах и одновременно выясним эффективности однопоточное и многопоточное выполнение приложений на примере программы t1.cc [17]:
//Однопотосчное и много поточное приложение T1.cc
#include <stdlib.h>
#include <stdio.h>
#include <iostream.h>
#include <unistd.h>
#include <limits.h>
#include <pthread.h>
#include <inttypes.h>
#include <sys/neutrino.h>
#include <sys/syspage.h>
#include <errno.h>
#include <math.h>
// преобразование процессорных циклов в милисекунды:
static double cycle2milisec ( uint64_t ccl ) {
const static double s2m = 1.E+3;
const static uint64_t cps = SYSPAGE_ENTRY( qtime )->cycles_per_sec; // частота процессора:
return (double)ccl * s2m / (double)cps;
};
static int nsingl = 1;
// рабочая функция
void workproc( int how ) {
const int msingl = 30000;
for( int j = 0; j < how; j++ ) // ... якобы вычисления
for( uint64_t i = 0; i < msingl * nsingl; i++ ) i = ( i + 1 ) - 1;
};
static pthread_barrier_t bstart, bfinish;
struct interv { uint64_t s, f; };
interv *trtime;
void* threadfunc ( void* data ) {
// заблокироваться на барьере, чтоб соскочить с него одновременно
pthread_barrier_wait( &bstart );
int id = pthread_self() - 2;
trtime[ id ].s = ClockCycles();
workproc( (int)data );
trtime[ id ].f = ClockCycles();
pthread_barrier_wait( &bfinish );
return NULL;
};
int main( int argc, char *argv[] ) {
int opt, val, nthr = 1, nall = SHRT_MAX;
while ( ( opt = getopt( argc, argv, "t:n:p:a:" ) ) != -1 ) {
switch( opt ) {
case 't' :
if( sscanf( optarg, "%i", &val ) != 1 ) perror( "parse command line failed" ), exit( EXIT_FAILURE );
if( val > 0 && val <= SHRT_MAX ) nthr = val;
break;
case 'p' :
if( sscanf( optarg, "%i", &val ) != 1 ) perror( "parse command line failed" ), exit( EXIT_FAILURE );
if( val != getprio( 0 ) )
if( setprio( 0, val ) == -1 ) perror( "priority isn't a valid" ), exit( EXIT_FAILURE );
break;
case 'n' :
if( sscanf( optarg, "%i", &val ) != 1 ) perror( "parse command line failed" ), exit( EXIT_FAILURE );
if( val > 0 ) nsingl *= val;
break;
case 'a' :
if( sscanf( optarg, "%i", &val ) != 1 ) perror( "parse command line failed" ), exit( EXIT_FAILURE );
if( val > 0 ) nall = val;
break;
default :
perror( "parse command line failed" ), exit( EXIT_FAILURE );
break;
}
};
if( nthr > 1 ) cout << "Multi-thread evaluation, thread number = " << nthr;
else cout << "Single-thread evaluation";
cout << " , priority level: " << getprio( 0 ) << endl;
_clockperiod clcout;
ClockPeriod( CLOCK_REALTIME, NULL, &clcout, 0 );
cout << "rescheduling = \t" << clcout.nsec * 4. / 1000000. << endl;
// калибровка единичного выполнения
const int NCALIBR = 512;
uint64_t tmin = 0, tmax = 0;
tmin = ClockCycles();
workproc( NCALIBR );
tmax = ClockCycles();
cout << "calculating = \t" << cycle2milisec ( tmax - tmin ) / NCALIBR << endl;
// многопотоковое выполнение
if( pthread_barrier_init( &bstart, NULL, nthr ) != EOK ) perror( "barrier init" ), exit( EXIT_FAILURE );
if( pthread_barrier_init( &bfinish, NULL, nthr + 1 ) != EOK ) perror( "barrier init" ), exit( EXIT_FAILURE );
trtime = new interv [ nthr ];
int cur = 0, prev = 0;
for( int i = 0; i < nthr; i++ ) {
cur = (int)floor( (double)nall / (double)nthr * ( i + 1 ) + .5 );
prev = (int)floor( (double)nall / (double)nthr * i + .5 );
if( pthread_create( NULL, NULL, threadfunc, (void*)( cur - prev ) ) != EOK )
perror( "thread create" ), exit( EXIT_FAILURE );
};
pthread_barrier_wait( &bfinish );
for( int i = 0; i < nthr; i++ ) {
tmin = ( i == 0 ) ? trtime[ 0 ].s : __min( tmin, trtime[ i ].s );
tmax = ( i == 0 ) ? trtime[ 0 ].f : __max( tmax, trtime[ i ].f );
};
cout << "evaluation = \t" << cycle2milisec ( tmax - tmin ) / nall << endl;
pthread_barrier_destroy( &bstart );
pthread_barrier_destroy( &bfinish );
delete trtime;
exit( EXIT_SUCCESS );
};
Логика этого приложения крайне проста: есть некоторая продолжительная по времени рабочая функция (workproc), выполняющая многогратно. Число выполнений определяется ключом запуска а. А время ее единичного выполнения задается ключом n. В примере установлена диспетчеризация по умолчанию - круговая, или карусельная). Весь объем этой работы делится поровну (или почти поровну) между несколькими (ключ t) потоками. На рис.53 показано выполнение программы t1.cc в перспективе System Profiler.
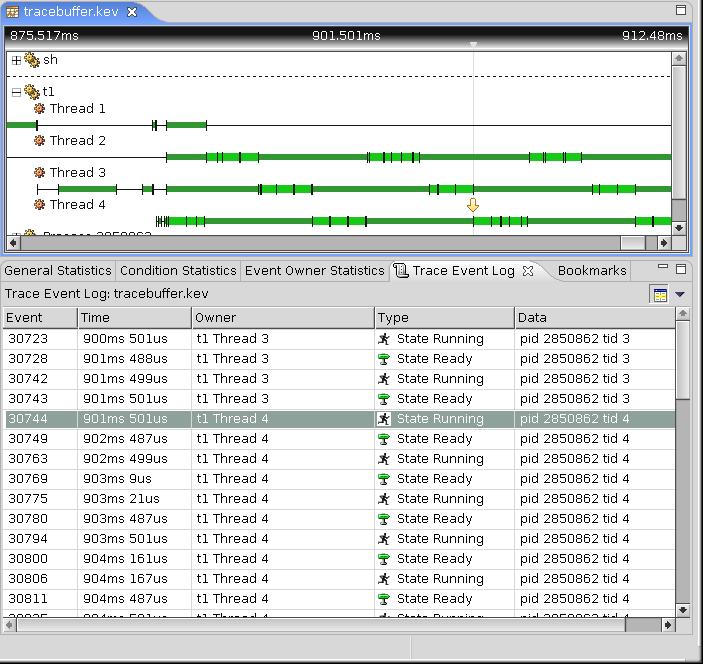
Рис.53. Выполнение программы t1.cc
Сравниваем усредненное время единичного выполнения рабочей функции для разного числа выполняющих потоков (в выводе "calculating" - это время эталонного вычисления в одном главном потоке, a "evaluation" - время того же вычисления, но во многих потоках). Для того чтобы иметь еще большую гибкость, предоставляется возможность переопределять приоритет, под которым в системе все это происходит (ключ р).
Краткий итог этого теста может звучать так: при достаточно высоком уровне приоритета (выше 12-13, когда на его выполнение не влияют процессы обслуживания клавиатуры, мыши и др.) время выполнения в «классическом» последовательном коде и в многопоточном коде (где несколько тысяч потоков!) практически не различаются. Различия не более 8%, причем в обе стороны.
В отличие от создаваемых параллельных процессов, рассмотренных ранее, все потоки, создаваемые в рамках одного процесса, разделяют единое адресное пространство процесса, и поэтому все переменные процесса, находящиеся в области видимости любого потока, доступны этому потоку.