

Модель с блокировками для чтения и записи.
Если элемент блокирован для записи, то на его значение воздействует функция . Если для чтения – значение элемента не изменяется.
Метод проверки сериализуемости расписания:
Строится граф предшествования. Узлы – транзакции. Дуги определяются следующим образом:
Транзакция устанавливает блокировку для чтения элемента А, транзакция , следующая за , устанавливает блокировку для записи А. Строится дуга из в .
Транзакция устанавливает блокировку для записи А, а транзакция , следующая за ней (если она существует) устанавливает блокировку так же для записи. Тогда строим дугу из в . Пусть далее,
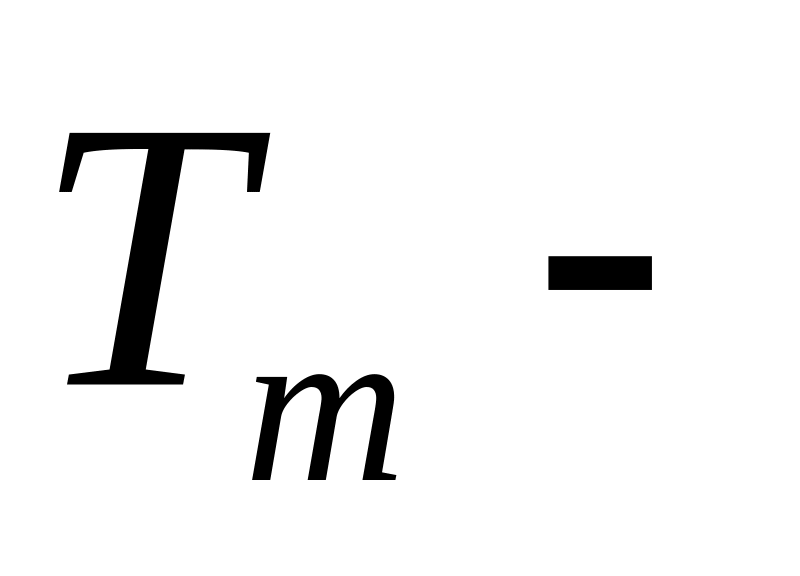 блокирует А для чтения после того,
как
снимет свою блокировку для записи, но
перед тем, как
установит свою блокировку для записи.
Если
не существует, то
любая транзакция, которая блокирует А
для чтения после того, как
разблокирует его. Тогда строим дугу
из
в
блокирует А для чтения после того,
как
снимет свою блокировку для записи, но
перед тем, как
установит свою блокировку для записи.
Если
не существует, то
любая транзакция, которая блокирует А
для чтения после того, как
разблокирует его. Тогда строим дугу
из
в
 .
.Если граф имеет циклы, то расписание не сериализуемо.
Параллельный доступ к иерархически структурированным элементам.
Во многих случаях совокупность элементов, к которым транзакция осуществляет доступ, может рассматриваться как дерево:
элементы являются узлами В-дерева;
логическая БД структурирована согласно иерархической модели;
РБД может иметь элементы на 4-х уровнях:
а) БД в целом;
б) каждое отношение;
в) каждый блок, в котором хранится файл, соответствующий отношению;
г) каждый кортеж.
При блокировке элементов можно придерживаться 2-х разных стратегий:
Блокировка элемента может предполагать и блокировку всех элементов, являющихся его потомками. Такая стратегия экономит время, т.к. она исключает блокировку более мелких элементов.
Блокировать элемент без блокировки его потомков.
Будем говорить, что транзакция подчиняется протоколу для дерева, если за исключением первого заблокированного элемента нельзя заблокировать никакой другой элемент, пока не будет разблокирован родительский узел.
Терема: Любое расписание транзакций, подчиняющееся протоколу для дерева, сериализуемо.
Пример: : LOCK A
: LOCK B
LOCK D
UNLOCK B
LOCK B
LOCK C
: LOCK E
UNLOCK D
LOCK F
UNLOCK A
LOCK G
UNLOCK C
UNLOCK E
LOCK E
UNLOCK F
UNLOCK B
UNLOCK G
UNLOCK E
o
 A
A

 B o o C
B o o C
D o o E
F o o G
FIRST( ) – первый из элементов, блокируемых транзакцией .
FIRST( ) = A FIRST( ) = B FIRST( ) = E
Обе транзакции
и
блокируют В, причём первой это делает
.
Строим
.
и
блокируют Е, первой это делает
:
![]() .
Отсюда существуют две последовательности
расписаний:
,
,
и
,
,
.
.
Отсюда существуют две последовательности
расписаний:
,
,
и
,
,
.
Алгоритм проверки сериализуемости расписания.
Алгоритм построения последовательности транзакций начинается с создания узла в графе для каждой транзакции.
Пусть
и
– транзакции, которые блокируют один
и тот же элемент (в разное время). Пусть
FIRST(
)
– первый из элементов, блокируемых
транзакцией
.
При независимости FIRST(
)
и FIRST(
)
(ни один не является потомком другого),
протокол для дерева гарантирует, что
и
не блокируют общего узла и
![]() и
и
![]() .
.
Если FIRST(
)
является предком FIRST(
),
то: если
блокирует FIRST(
)
перед тем как это делает
,
строим
;
в противном случае
![]() .
.
Пример: {продолжение}

