

34. Решения с поддержкой nvidia cuda.
Все видеокарты, обладающие поддержкой CUDA, могут помочь в ускорении большинства требовательных задач, начиная от аудио- и видеообработки, и заканчивая медициной и научными исследованиями. Единственное реальное ограничение состоит в том, что многие CUDA программы требуют минимум 256 мегабайт видеопамяти, и это — одна из важнейших технических характеристик для CUDA-приложений.
Актуальный список поддерживающих CUDA продуктов можно получить на вебсайте NVIDIA. На момент написания статьи расчёты CUDA поддерживали все продукты серий GeForce 600, GeForce 500, GeForce 400, GeForce 200, GeForce 9 и GeForce 8, в том числе и мобильные продукты, начиная с GeForce 8400M, а также и чипсеты GeForce 8100, 8200 и 8300. Также поддержкой CUDA обладают современные продукты Quadro и все Tesla: S1070, C1060, C870, D870 и S870.


Особо отметим, что вместе с новыми видеокартами GeForce GTX 260 и 280, были анонсированы и соответствующие решения для высокопроизводительных вычислений: Tesla C1060 и S1070 (представленные на фото выше), которые будут доступны для приобретения осенью этого года. GPU в них применён тот же — GT200, в C1060 он один, в S1070 — четыре. Зато, в отличие от игровых решений, в них используется по четыре гигабайта памяти на каждый чип. Из минусов разве что меньшая частота памяти и ПСП, чем у игровых карт, обеспечивающая по 102 гигабайт/с на чип.
35. Состав nvidia cuda.
CUDA включает два API: высокого уровня (CUDA Runtime API) и низкого (CUDA Driver API), хотя в одной программе одновременное использование обоих невозможно, нужно использовать или один или другой. Высокоуровневый работает «сверху» низкоуровневого, все вызовы runtime транслируются в простые инструкции, обрабатываемые низкоуровневым Driver API. Но даже «высокоуровневый» API предполагает знания об устройстве и работе видеочипов NVIDIA, слишком высокого уровня абстракции там нет.

Есть и ещё один уровень, даже более высокий — две библиотеки:
CUBLAS — CUDA вариант BLAS (Basic Linear Algebra Subprograms), предназначенный для вычислений задач линейной алгебры и использующий прямой доступ к ресурсам GPU;
CUFFT — CUDA вариант библиотеки Fast Fourier Transform для расчёта быстрого преобразования Фурье, широко используемого при обработке сигналов. Поддерживаются следующие типы преобразований: complex-complex (C2C), real-complex (R2C) и complex-real (C2R).
Рассмотрим эти библиотеки подробнее. CUBLAS — это переведённые на язык CUDA стандартные алгоритмы линейной алгебры, на данный момент поддерживается только определённый набор основных функций CUBLAS. Библиотеку очень легко использовать: нужно создать матрицу и векторные объекты в памяти видеокарты, заполнить их данными, вызвать требуемые функции CUBLAS, и загрузить результаты из видеопамяти обратно в системную. CUBLAS содержит специальные функции для создания и уничтожения объектов в памяти GPU, а также для чтения и записи данных в эту память. Поддерживаемые функции BLAS: уровни 1, 2 и 3 для действительных чисел, уровень 1 CGEMM для комплексных. Уровень 1 — это векторно-векторные операции, уровень 2 — векторно-матричные операции, уровень 3 — матрично-матричные операции.
CUFFT — CUDA вариант функции быстрого преобразования Фурье — широко используемой и очень важной при анализе сигналов, фильтрации и т.п. CUFFT предоставляет простой интерфейс для эффективного вычисления FFT на видеочипах производства NVIDIA без необходимости в разработке собственного варианта FFT для GPU. CUDA вариант FFT поддерживает 1D, 2D, и 3D преобразования комплексных и действительных данных, пакетное исполнение для нескольких 1D трансформаций в параллели, размеры 2D и 3D трансформаций могут быть в пределах [2, 16384], для 1D поддерживается размер до 8 миллионов элементов.
Основы создания программ на CUDA
Для понимания дальнейшего текста следует разбираться в базовых архитектурных особенностях видеочипов NVIDIA. GPU состоит из нескольких кластеров текстурных блоков (Texture Processing Cluster). Каждый кластер состоит из укрупнённого блока текстурных выборок и двух-трех потоковых мультипроцессоров, каждый из которых состоит из восьми вычислительных устройств и двух суперфункциональных блоков. Все инструкции выполняются по принципу SIMD, когда одна инструкция применяется ко всем потокам в warp (термин из текстильной промышленности, в CUDA это группа из 32 потоков — минимальный объём данных, обрабатываемых мультипроцессорами). Этот способ выполнения назвали SIMT (single instruction multiple threads — одна инструкция и много потоков).
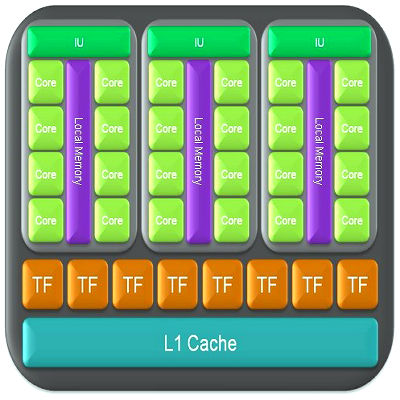
Каждый из мультипроцессоров имеет определённые ресурсы. Так, есть специальная разделяемая память объемом 16 килобайт на мультипроцессор. Но это не кэш, так как программист может использовать её для любых нужд, подобно Local Store в SPU процессоров Cell. Эта разделяемая память позволяет обмениваться информацией между потоками одного блока. Важно, что все потоки одного блока всегда выполняются одним и тем же мультипроцессором. А потоки из разных блоков обмениваться данными не могут, и нужно помнить это ограничение. Разделяемая память часто бывает полезной, кроме тех случаев, когда несколько потоков обращаются к одному банку памяти. Мультипроцессоры могут обращаться и к видеопамяти, но с большими задержками и худшей пропускной способностью. Для ускорения доступа и снижения частоты обращения к видеопамяти, у мультипроцессоров есть по 8 килобайт кэша на константы и текстурные данные.
Мультипроцессор использует 8192-16384 (для G8x/G9x и GT2xx, соответственно) регистра, общие для всех потоков всех блоков, выполняемых на нём. Максимальное число блоков на один мультипроцессор для G8x/G9x равно восьми, а число warp — 24 (768 потоков на один мультипроцессор). Всего топовые видеокарты серий GeForce 8 и 9 могут обрабатывать до 12288 потоков единовременно. GeForce GTX 280 на основе GT200 предлагает до 1024 потоков на мультипроцессор, в нём есть 10 кластеров по три мультипроцессора, обрабатывающих до 30720 потоков. Знание этих ограничений позволяет оптимизировать алгоритмы под доступные ресурсы.
Первым шагом при переносе существующего приложения на CUDA является его профилирование и определение участков кода, являющихся «бутылочным горлышком», тормозящим работу. Если среди таких участков есть подходящие для быстрого параллельного исполнения, эти функции переносятся на Cи расширения CUDA для выполнения на GPU. Программа компилируется при помощи поставляемого NVIDIA компилятора, который генерирует код и для CPU, и для GPU. При исполнении программы, центральный процессор выполняет свои порции кода, а GPU выполняет CUDA код с наиболее тяжелыми параллельными вычислениями. Эта часть, предназначенная для GPU, называется ядром (kernel). В ядре определяются операции, которые будут исполнены над данными.
Видеочип получает ядро и создает копии для каждого элемента данных. Эти копии называются потоками (thread). Поток содержит счётчик, регистры и состояние. Для больших объёмов данных, таких как обработка изображений, запускаются миллионы потоков. Потоки выполняются группами по 32 штуки, называемыми warp'ы. Warp'ам назначается исполнение на определенных потоковых мультипроцессорах. Каждый мультипроцессор состоит из восьми ядер — потоковых процессоров, которые выполняют одну инструкцию MAD за один такт. Для исполнения одного 32-поточного warp'а требуется четыре такта работы мультипроцессора (речь о частоте shader domain, которая равна 1.5 ГГц и выше).
Мультипроцессор не является традиционным многоядерным процессором, он отлично приспособлен для многопоточности, поддерживая до 32 warp'ов единовременно. Каждый такт аппаратное обеспечение выбирает, какой из warp'ов исполнять, и переключается от одного к другому без потерь в тактах. Если проводить аналогию с центральным процессором, это похоже на одновременное исполнение 32 программ и переключение между ними каждый такт без потерь на переключение контекста. Реально ядра CPU поддерживают единовременное выполнение одной программы и переключаются на другие с задержкой в сотни тактов.
Модель программирования CUDA
Повторимся, что CUDA использует параллельную модель вычислений, когда каждый из SIMD процессоров выполняет ту же инструкцию над разными элементами данных параллельно. GPU является вычислительным устройством, сопроцессором (device) для центрального процессора (host), обладающим собственной памятью и обрабатывающим параллельно большое количество потоков. Ядром (kernel) называется функция для GPU, исполняемая потоками (аналогия из 3D графики — шейдер).
Мы говорили выше, что видеочип отличается от CPU тем, что может обрабатывать одновременно десятки тысяч потоков, что обычно для графики, которая хорошо распараллеливается. Каждый поток скалярен, не требует упаковки данных в 4-компонентные векторы, что удобнее для большинства задач. Количество логических потоков и блоков потоков превосходит количество физических исполнительных устройств, что даёт хорошую масштабируемость для всего модельного ряда решений компании.
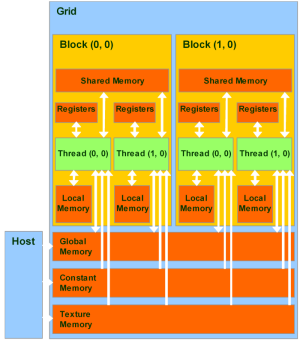
Модель программирования в CUDA предполагает группирование потоков. Потоки объединяются в блоки потоков (thread block) — одномерные или двумерные сетки потоков, взаимодействующих между собой при помощи разделяемой памяти и точек синхронизации. Программа (ядро, kernel) исполняется над сеткой (grid) блоков потоков (thread blocks), см. рисунок ниже. Одновременно исполняется одна сетка. Каждый блок может быть одно-, двух- или трехмерным по форме, и может состоять из 512 потоков на текущем аппаратном обеспечении.

Блоки потоков выполняются в виде небольших групп, называемых варп (warp), размер которых — 32 потока. Это минимальный объём данных, которые могут обрабатываться в мультипроцессорах. И так как это не всегда удобно, CUDA позволяет работать и с блоками, содержащими от 64 до 512 потоков.
Группировка блоков в сетки позволяет уйти от ограничений и применить ядро к большему числу потоков за один вызов. Это помогает и при масштабировании. Если у GPU недостаточно ресурсов, он будет выполнять блоки последовательно. В обратном случае, блоки могут выполняться параллельно, что важно для оптимального распределения работы на видеочипах разного уровня, начиная от мобильных и интегрированных.
Модель памяти CUDA
Модель памяти в CUDA отличается возможностью побайтной адресации, поддержкой как gather, так и scatter. Доступно довольно большое количество регистров на каждый потоковый процессор, до 1024 штук. Доступ к ним очень быстрый, хранить в них можно 32-битные целые или числа с плавающей точкой.
Каждый поток имеет доступ к следующим типам памяти:
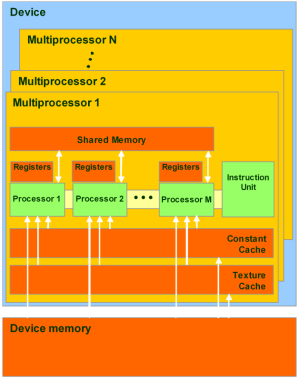
Глобальная память — самый большой объём памяти, доступный для всех мультипроцессоров на видеочипе, размер составляет от 256 мегабайт до 1.5 гигабайт на текущих решениях (и до 4 Гбайт на Tesla). Обладает высокой пропускной способностью, более 100 гигабайт/с для топовых решений NVIDIA, но очень большими задержками в несколько сот тактов. Не кэшируется, поддерживает обобщённые инструкции load и store, и обычные указатели на память.
Локальная память — это небольшой объём памяти, к которому имеет доступ только один потоковый процессор. Она относительно медленная — такая же, как и глобальная.
Разделяемая память — это 16-килобайтный (в видеочипах нынешней архитектуры) блок памяти с общим доступом для всех потоковых процессоров в мультипроцессоре. Эта память весьма быстрая, такая же, как регистры. Она обеспечивает взаимодействие потоков, управляется разработчиком напрямую и имеет низкие задержки. Преимущества разделяемой памяти: использование в виде управляемого программистом кэша первого уровня, снижение задержек при доступе исполнительных блоков (ALU) к данным, сокращение количества обращений к глобальной памяти.
Память констант — область памяти объемом 64 килобайта (то же — для нынешних GPU), доступная только для чтения всеми мультипроцессорами. Она кэшируется по 8 килобайт на каждый мультипроцессор. Довольно медленная — задержка в несколько сот тактов при отсутствии нужных данных в кэше.
Текстурная память — блок памяти, доступный для чтения всеми мультипроцессорами. Выборка данных осуществляется при помощи текстурных блоков видеочипа, поэтому предоставляются возможности линейной интерполяции данных без дополнительных затрат. Кэшируется по 8 килобайт на каждый мультипроцессор. Медленная, как глобальная — сотни тактов задержки при отсутствии данных в кэше.
Естественно, что глобальная, локальная, текстурная и память констант — это физически одна и та же память, известная как локальная видеопамять видеокарты. Их отличия в различных алгоритмах кэширования и моделях доступа. Центральный процессор может обновлять и запрашивать только внешнюю память: глобальную, константную и текстурную.
Из написанного выше понятно, что CUDA предполагает специальный подход к разработке, не совсем такой, как принят в программах для CPU. Нужно помнить о разных типах памяти, о том, что локальная и глобальная память не кэшируется и задержки при доступе к ней гораздо выше, чем у регистровой памяти, так как она физически находится в отдельных микросхемах.
Типичный, но не обязательный шаблон решения задач:
задача разбивается на подзадачи;
входные данные делятся на блоки, которые вмещаются в разделяемую память;
каждый блок обрабатывается блоком потоков;
подблок подгружается в разделяемую память из глобальной;
над данными в разделяемой памяти проводятся соответствующие вычисления;
результаты копируются из разделяемой памяти обратно в глобальную.
Среда программирования
В состав CUDA входят runtime библиотеки:
общая часть, предоставляющая встроенные векторные типы и подмножества вызовов RTL, поддерживаемые на CPU и GPU;
CPU-компонента, для управления одним или несколькими GPU;
GPU-компонента, предоставляющая специфические функции для GPU.
Основной процесс приложения CUDA работает на универсальном процессоре (host), он запускает несколько копий процессов kernel на видеокарте. Код для CPU делает следующее: инициализирует GPU, распределяет память на видеокарте и системе, копирует константы в память видеокарты, запускает несколько копий процессов kernel на видеокарте, копирует полученный результат из видеопамяти, освобождает память и завершает работу.
В качестве примера для понимания приведем CPU код для сложения векторов, представленный в CUDA:

Функции, исполняемые видеочипом, имеют следующие ограничения: отсутствует рекурсия, нет статических переменных внутри функций и переменного числа аргументов. Поддерживается два вида управления памятью: линейная память с доступом по 32-битным указателям, и CUDA-массивы с доступом только через функции текстурной выборки.
Программы на CUDA могут взаимодействовать с графическими API: для рендеринга данных, сгенерированных в программе, для считывания результатов рендеринга и их обработки средствами CUDA (например, при реализации фильтров постобработки). Для этого ресурсы графических API могут быть отображены (с получением адреса ресурса) в пространство глобальной памяти CUDA. Поддерживаются следующие типы ресурсов графических API: Buffer Objects (PBO / VBO) в OpenGL, вершинные буферы и текстуры (2D, 3D и кубические карты) Direct3D9.
Стадии компиляции CUDA-приложения:
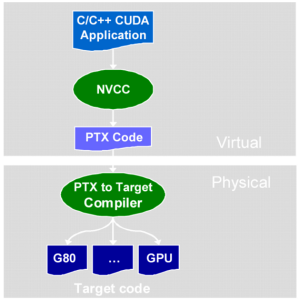
Файлы исходного кода на CUDA C компилируются при помощи программы NVCC, которая является оболочкой над другими инструментами, и вызывает их: cudacc, g++, cl и др. NVCC генерирует: код для центрального процессора, который компилируется вместе с остальными частями приложения, написанными на чистом Си, и объектный код PTX для видеочипа. Исполнимые файлы с кодом на CUDA в обязательном порядке требуют наличия библиотек CUDA runtime library (cudart) и CUDA core library (cuda).