

Алгоритм внутренней сортировки. Алгоритм пирамиды(Метод Уильямса-Флойда)
Основан на специальном представлении массива в форме бинарного дерева, обладающего специальными свойствами и называющийся «пирамидой»
свойства пирамиды :
1. Любой элемент пирамиды содержит значения, которые не меньше значений потомков этого элемента пирамиды:
A[i]>=A[2i]иA[i]>=A[2i+1] 2. Любая последовательность элементов вида A[n/2+1] A[2n/2+1]… A[n] также является пирамидой, т.е для нее выполняются эти два свойства.
Суть алгоритма
1.Приводим массив к виду «пирамида» т.е должно выполняться 1 свойство. При этом максимальный элемент должен оказаться в вершине пирамиды.
2.Производим обмен максимального элемента с последним элементом массива.
Последний элемент в дальнейшем не рассматриваем. Для оставшейся части массива повторяем все действия. Она может уже не являться «пирамидой», по этому приводим ее к виду «пирамида». Так до тех пор, пока в рассмотренной части массива не останется один элемент.Метод сортировки пирамидой имеет сложность ~O(n*log n) и не использует дополнительной памяти.
j -кол-во
отсортированных Эл-ов массива.
-кол-во
отсортированных Эл-ов массива.
i-рассматриваемая часть массива.
Алгоритм внутренней сортировки.Сортировка посредством подсчета сравнений.
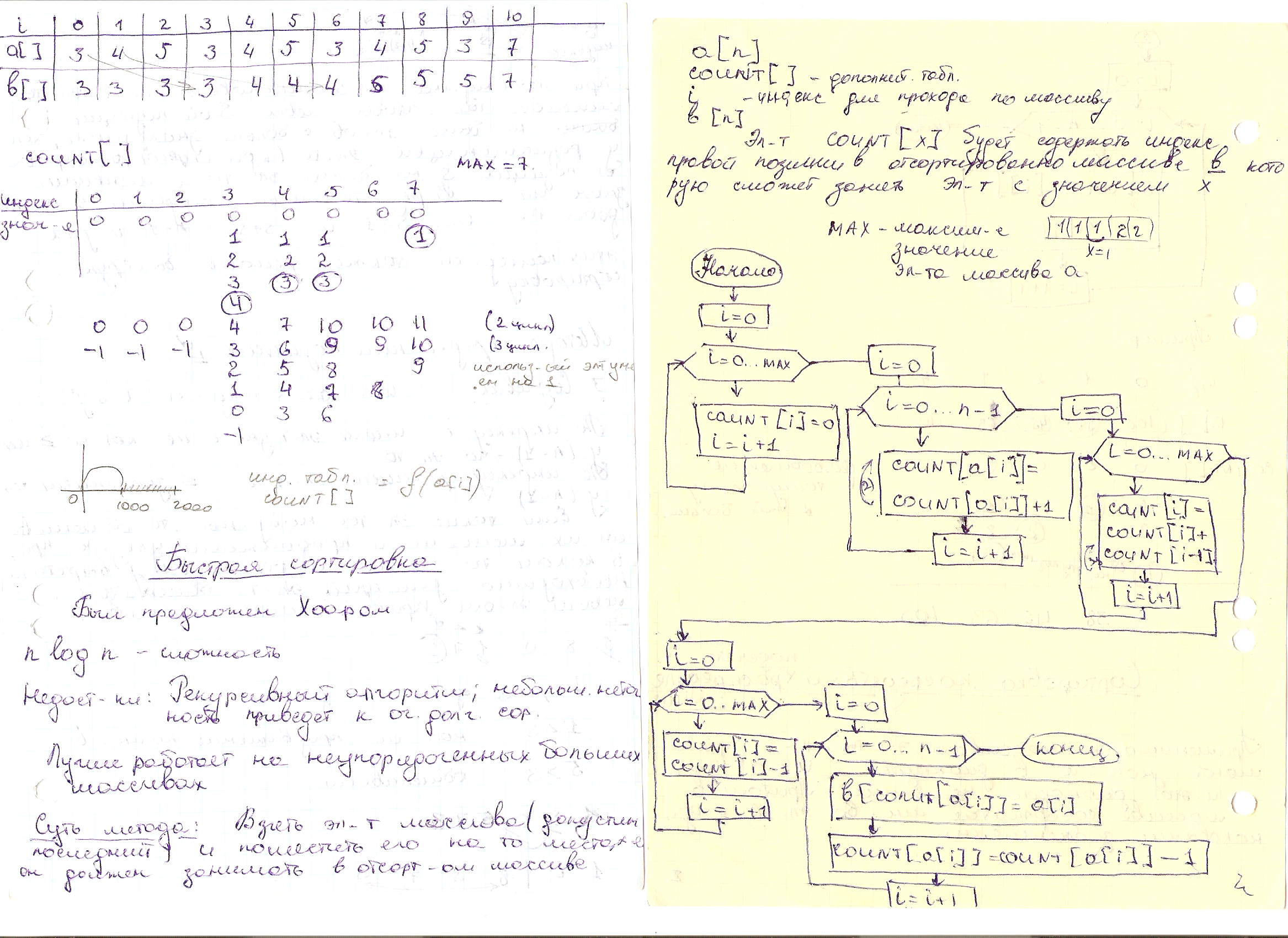
Если элемент массива Х превышает по значению j элементов, то после сортировки он должен занять j+1 место, т.е позицию с индексом j .По этому для сортировки необходимо сравнивать попарно элементы массива и подсчитывать для каждого из них количество меньших элементов. При сортировке строится вспомогательная таблица COUNT[n], которая будет содержать количество меньших элементов, т.е индекс окончательной позиции данного элемента.
a[n]исходный,b[n]отсортированный массив, COUNT[n],i,j.


Алгоритм внутренней сортировки. Сортировка посредством подсчета распределений.
Применима к массивам, элементы которых принимают значения в диапазоне u<a[i]<v и этот диапазон не велик. При том в массиве содержится множество элементов с одинаковыми значениями.
a[n]
COUNT[]дополнительная таблица
I индекс для прохода по массиву
b[n]
MAX максимальное значение элемента массива
Элемент COUNT[х] будет
содержать индекс правой позиции в
отсортированном массиве b,
которую сможет заменять элемент с
значением х

Алгоритм внутренней сортировки. Быстрая сортировка.
Был предложен Хаором. nlogn-сложность. Недостатки- рекурсивный алгоритм, небольшая неточность приведет к очень долгой сортировке.
Лучше работает на неупорядоченных больших массивах.
Суть метода: взять элемент массива(допустим последний) и поместить его на то место ,Ю которое он должен занимать в отсортированном массиве. При этом нужно перекомпоновать остальные элементы массива так, чтоб левее S-ой позиции не было элементов с большим значением, чем у размещающего элемента(«делящего»), а справа от позиции S не было элемента с меньшим значением. В результате мы получим 2 последовательности 0….S-1 и S+S….n-1 и для этих последовательностей также делаем быструю сортировку.
Методы определения позиции S:
Используется 2 индекса i и j.По индексу i ищем элемент, значение которого больше или равно чем y(n-1)-го элемента. По индексу j ищем элемент, значение которого меньше или равно чем y(n-1)-го элемента. Если такие элементы найдены, то обмениваем их местами и продолжаем указанную процедуру. В каком то месте индексы i и j встретятся. Необходимо делящий элемент обменять с левым элементом правой части массива.
QUICK Sort (l,r)
i-индекс для определения «делителя»
l-индекс левого элемента рассматриваемого массива
r -правого
эл-та.
-правого
эл-та.
Part(l,r)
i ,j,a[]
,j,a[]
Способы улучшения быстрой сорт.:1.Использовать более простые методы для сортировки для небольших последовательностей.Если верно условие r-l<25, то лучше использовать другую сортировку.(сокращение времени до 20%)
2.Использование лучшего значения делящего элемента.Для того чтоб исключить бесполезный просмотр выбирают 3 элемента массива с начала, середины и конца, среди них выбирают элемент со средним значением-этот элемент обменивается с последним элементом рассматриваемой части массива.
3.Не рекурсивная реализация при использовании стека.