

20. Как отделить исконные слова от заимствований в близкородственных языках
При отделении заимствованных слов от исконных особую трудность представляют заимствования из близко родственных языков: они, как и исконные слова, восходят к словам того же самого праязыка. Определить их заимствованный характер можно на основании того, что звуковые изменения, происшедшие в этих словах, отличаются от тех, что происходили в исконных. Например (см. [Пизани 2001, 63]), итальянские слова gioia `радость' и mangiare `есть, кушать', хотя и могут быть выведены из лат. gaudia `радость' и manducare `жрать', не являются в итальянском языке исконными: палатализация заднеязычных перед a свидетельствует об их французском происхождении (из joie и manger соответственно). В итальянском языке, в отличие от французского, заднеязычные перед a не палатализовались. Таким образом, можно видеть, что процесс заимствования из близкородственного языка приводит к возникновению двух различных систем регулярных фонетических соответствий: соответствия, устанавливаемые на множестве исконно родственных слов, будут в ряде случаев отличаться от соответствий, устанавливаемых на множестве заимствований.
Наличие в языке нескольких моделей преобразования одних и тех же звуков в одной и той же позиции может свидетельствовать о том, что соответствующие слова появились в языке неодновременно. Рассмотрим португальские слова, происходящие из латинских, а также ранние и поздние заимствования (пример принадлежит В.А. Терентьеву, см. задачу № 13):
1. chegar < plicare
2. ch{a~}o < planum
3. cheio < plenum
4. praino < plaine
5. prancha < planche
6. pl{a/}tano < platanum
7. plebe < plebem
Здесь видны три системы соответствий: pl = ch, pl = pr и pl = pl. Слова, происходящие из латинских (соответственно, наиболее долго "прожившие" в португальском языке), подверглись наибольшему количеству изменений, самые поздние заимствования изменились в наименьшей степени. Таким образом, по системам регулярных фонетических соответствий можно не только отделить исконные слова от заимствованных, но и разновременные заимствования друг от друга.
32. Какой фрагмент языка наиболее удобен для языковой дивергенции и почему?
На предположении о постоянной скорости изменений в базисной лексике построил свою теорию глоттохронологии, иногда называемой также лексикостатистикой, американский ученый Морис Сводеш. Эта теория базируется на следующих пяти постулатах:
"1. В словаре каждого языка можно выделить специальный фрагмент, который мы будем называть дальше основной, или стабильной частью.
2. Можно указать список значений, которые в любом языке обязательно выражаются словами из основной части... Будем говорить, что эти слова образуют основной список (ОС). Через N{0} обозначим число слов в ОС.
3. Доля p слов из ОС, которые сохранятся (не будут заменены другими словами) на протяжении интервала времени {Dд} t... постоянна (то есть зависит только от величины выбранного промежутка, но не от того, как он выбран или какие слова какого языка рассматриваются).
4. Все слова, составляющие ОС, имеют одинаковые шансы сохраниться (соответственно, не сохраниться, "распасться") на протяжении этого интервала времени.
5. Вероятность для слова из ОС праязыка сохраниться в ОС одного языка-потомка не зависит от его вероятности сохраниться в аналогичном списке другого языка-потомка."
Из совокупности приведенных постулатов выводится основная математическая зависимость глоттохронологии:
N(t)= N{0}e-{l}t
где время, прошедшее от начала момента развития до некоторого последующего момента обозначается как t (и измеряется в тысячелетиях); N{0} есть исходный ОС; {l} есть "скорость выпадения" слов из N{0}; и N(t) есть доля слов исходного ОС, сохранившихся к моменту t. Зная коэффициент {l} и долю слов, сохранившихся в данном языке из списка ОС, мы можем вычислить длину прошедшего промежутка времени:
t=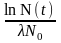
Доля слов из ОС, сохранившихся в двух языках, будет составлять соответственно:
N{2}(t)=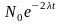 ,
,
а время, разделяющее их, будет вычисляться как:
t=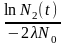
Несмотря на простоту и элегантность данного математического аппарата, уже давно было замечено, что он не очень хорошо работает. Так, К. Бергсланд и Х. Фогт, рассматривая материал скандинавских языков, показали, что скорость распадения лексики в исландском языке за последнюю тысячу лет равнялась всего {=~} 0,04, а в литературном норвежском (риксмоле) — {=~} 0,2 (и это при том, что М. Сводеш в качестве константы {l} предлагал величину 0,14!). Соответственно, получались вполне нелепые результаты: для исландского языка около 100-150 лет, а для риксмола — около 1400 лет развития — при том, что оба языка возникли из одного источника и развивались независимо в течение около 1000 лет. В большинстве случаев применение теории Сводеша давало явно "умоложенные" даты по сравнению с теми, которые можно было предположить на основании реальной истории языков. Все это заставило большинство исследователей поставить под сомнение всю глоттохронологическую методику.
Несмотря на это, глоттохронология продолжает существовать. Дело в том, что есть непреложный эмпирический факт, с которым приходится считаться: чем ближе друг к другу языки, тем больше между ними совпадений в области базисной лексики. Так, все индоевропейские языки (из разных подгрупп: немецкий и русский, хинди и польский, болгарский и румынский) имеют между собой около 30% совпадений; все балто-славянские языки (литовский и русский, латышский и чешский) имеют между собой примерно 45-50% совпадений; все славянские языки (русский и польский, чешский и болгарский), а также все германские языки (немецкий и шведский, голландский и исландский) имеют между собой примерно 75-85% совпадений. Налицо, таким образом, явная корреляция между степенью родства и количеством совпадений в базисной лексике. Глоттохронологию, по-видимому, нельзя сбрасывать со счетов, хотя нужен пересмотр некоторых ее постулатов.