Шпоры по компьютерной графике1
.doc|
1. История развития компьютерной графики. 1950 год – появляются компьютеры. Они используются для решения научных и производственных задач, результатом которых были числовые данные. К 60-тым годам появление более мощных компьютеров, на которых появляется возможность обработки графических данных в режиме символьной печати. Затем появляются специальные устройства для вывода на бумагу, так называемые графопостроители, или перьевые плоттеры. Для управления работой графопостроителей стали создавать спец. ПО. Следующий важный шаг произошёл с появлением графических дисплеев. Графический дисплей формирует рисунок из множества точек, выстроенных в ровные ряды или строки, образующие растр. Плата компьютера, обеспечивающего формирование видеосигнала и тем самым определяющая изображение называются видеоадаптером, видеоплатой и т.д. Основные части видеоадаптера – видеопамять и дисплейный процессор. Выводимое изображение формируется в видеопамяти. Дисплейный процессор читает содержимое видеопамяти и управляет работой монитора. К видеопамяти имеет доступ 2 процессора – центральный и дисплейный. Центральный записывает видеоинформацию, а дисплейный читает её и передаёт на монитор. В видеопамяти хранится последовательность кодов, определяющих цвет каждой точки. Видеоадаптеры могут работать в различных режимах: текстовом и графическом. В текстовом режиме экран монитора условно разбивается на отдельные участки, т.е. знакоместа. Каждое знакоместо может быть выведено 250 символами по таблице ASCII кодов. В графическом режиме информация отображается в виде прямоугольной сетки точек, цвет каждой из которых задаётся программой. Существенное различие имеется при заполнении видеопамяти в текстовом и графическом режимах. В графическом режиме кол-во элементов видеопамяти соответствует количеству точек на экране, в текстовом – количеству символов на экране. В текстовом режиме для каждой позиции на экране запоминается код символа, который в нее выводится и атрибуты изображения этого символа. Первый компьютер JBM PC – 1981 году был оснащен видеоадаптером MDA. Видеосистема была предназначена для работы только в текстовом режиме. Через год появляются видеоадаптер Hercules, который поддерживал уже графический черно-белый видеорежим, с размером 720×348 пикселей. Следующим шагом был видеоадаптер CGA – 1983. Это была первая цветная модель для IBM PC. Он позволил работать в цветном текстовом и графическом режимах.(320×200 – цветной, 640×200– черно-белый, в цветном может обрабатывать 4 цвета)
|
В 1984 году появился видеоадаптер EGA. У него был 16-цветный режим, размером 640×350 пикселей (он имеет недостаток – пиксели не квадратные). В 1987 появились адаптеры MCGA(Multicolor) и VGA(Video) (256-цветные видеорежимы). На VGA стало возможно черно-белое фото. Появляются видеоадаптеры, обеспечивающие видеорежимы при 16 цветах – 800×600, 640×480, 1024×768- Super VGA. 1995год–Targa 24-16 000000 цветов, т.е. 24 бита/пиксель. Apple, Macintosh стали сдавать позиции. На данный момент на компьютеры IBM PC с процессором Pentium используется огромное количество видеокарт с глубиной цвета 32 бита/пиксель при размерах растра 1600×1200. Параметры отображения обуславливаются не только моделями видеоадаптера, но и объемом видеопамяти. Видеопамять хранит растровое изображение, которое полностью соответствует текущему состоянию монитора. Необходимый объем видеопамяти вычисляется как периметр растра экрана на количество бит на пиксель. В видеопамяти могут хранится несколько кадров изображения. Это используется в анимации, для их сохранения используются отдельные страницы видеопамяти с одинаковой логической организацией, но разной адресацией. Обмен данными по системной шине для видеосистемы обеспечивают процессор, видеоадаптер и контроллер локальной шины. До недавнего времени использовалась шина PCI (эта шина является стандартом для подключения модемов, сетевых контроллеров и т.д.) на 33МГц – 132МБайта/с. В настоящее время используется шина AGP. Наличие AGP порта повышает быстродействие компьютера (на 66МГц – скорость 528Мбайт/с). Кроме видеопамяти на плате видеоадаптера располагается специальный мощный графический процессор, который по сложности приближается к центральному. Кроме визуализации содержимого видеопамяти графический дисплейный процессор выполняет такие растровые операции как рисование массивов пикселей, манипуляции с цветами пикселей, копирование, наложение текстуры и т.д. Ранее эти функции выполнялись центральным процессором, а графически использовались лишь для рисования линий и т.д. Видеоадаптер выполняет эти операции аппаратно, что позволяет намного ускорить их в сравнении с программной реализацией центрального процессора. Одним из наиболее распространенных графических интерфейсов является OpenGL. Он является библиотекой графических функций и поддерживается многими ОС, в том числе и Windows. Графический интерфейс DirectX предназначен для работы под Windows, имеет подсистему 3-х мерной графики Direct3D и подсистему DirectDraw, который обеспечивает прямой доступ к видеопамяти.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
2. Графика и компьютерная графика. Графика – результат визуального представления реального или воображаемого объекта, полученный традиционными методами: рисованием или печатанием худ. образов. Комп. графика - графика, включающая любые данные, предназначенные для отображения на устройстве вывода. В комп. графике различают понятия создания и визуализации изображения. В комп. графике выполнение работы иногда отделено от его графического представления. Одним из способов завершения комп. граф. процесса является вирт. вывод, т.е. вывод файла на какое-нибудь запоминающее устройство. Данные, которые были выведены в файл могут быть в последствии восстановлены и использованы для граф. представления. Изображением считается визуальное представление реального объекта, зафиксированное человеком с помощью нек. механич., электронного или фотографического процесса. В комп. графике изображением считается объект, воспроизв-й устройством вывода. Интерактивная комп. графика – это способность комп. системы создавать графику и одновременно вести диалог с человеком. Первые ИК системы САПР. САПР используется в машиностроении, электронике, дизайне, проектировании и т.д. ГИС – новая разновидность систем ИКГ, соединяют в себя методы таких наук, как математика, физика, геодезия, криптография, картография, и комп. графика. ГИС позволяют выполнять ввод и редактирование объектов с учетом их расположения на поверхности земли, формирования на их основе разнообразных моделей и запись информации в базу данных. В ГИС важнейшей является возможность графического анализа БД.
|
3. Графический формат. Графический формат – это способ записи данных, описывающих графическое изображение. Они разработаны для эффективной и логичной организации и сохранения графических данных в файле. Почти каждая прикладная программа создает и сохраняет некоторые виды графических данных. Сейчас многие программы поддерживают смешанные форматы, что позволяет включать растровые, векторные и текстовые данные друг в друга. Графические данные делят на 2 класса: 1 векторные 2 растровые Векторные данные используются для представления прямых, прямоугольников и кривых и любых других объектов, которые могут быть созданы на их основе с помощью определения в численном виде ключевых точек. Программа воспроизводит линии посредством соединения ключевых точек. С векторными данными всегда связаны информация об атрибутах и набор соглашений. Соглашения могут быть заданы как явно, так и неявно, но они программно зависимы. В компьютерной графике термин вектор используется для обозначения части линий и задается конечным набором точек. Растровые данные – набор числовых значений, определяющих цвета отдельных пикселей. Пиксели – цветовые точки, расположенные на правильной сетке и формирующие образ. Техническим растром является массив числовых значений, задающих цвета отдельных пикселей при отображении образа на отдельном устройстве вывода. Для обозначения числового значения в растровых данных, соответствующих цвету пикселя в изображении на устройствах вывода используется термин пиксельное значение. Термин bitmap используется для обозначения массива пикселей, независимо от типа, а термин битовая глубина используется для указания размеров этих пикселей, выраженных в битах или байтах.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
4. Графические файлы. Граф. файлы – файлы, в которых хранятся любые типы графических данных, предназначенных для последующей визуализации. Способы организации этих файлов называются графическими форматами. После записи в файл изображение становится данными, формат которых может быть изменен. Графические данные делят на 2 класса: 1 векторные 2 растровые Векторные данные используются для представления прямых, прямоугольников и кривых и любых других объектов, которые могут быть созданы на их основе с помощью определения в численном виде ключевых точек. Программа воспроизводит линии посредством соединения ключевых точек. С векторными данными всегда связаны информация об атрибутах и набор соглашений. Соглашения могут быть заданы как явно, так и неявно, но они программно зависимы. В компьютерной графике термин вектор используется для обозначения части линий и задается конечным набором точек. Растровые данные – набор числовых значений, определяющих цвета отдельных пикселей. Пиксели – цветовые точки, расположенные на правильной сетке и формирующие образ. Техническим растром является массив числовых значений, задающих цвета отдельных пикселей при отображении образа на отдельном устройстве вывода. Для обозначения числового значения в растровых данных, соответствующих цвету пикселя в изображении на устройствах вывода используется термин пиксельное значение. Термин bitmap используется для обозначения массива пикселей, независимо от типа, а термин битовая глубина используется для указания размеров этих пикселей, выраженных в битах или байтах.
|
5. Графические данные. Графические данные делят на 2 класса: 1 векторные 2 растровые Векторные данные используются для представления прямых, прямоугольников и кривых и любых других объектов, которые могут быть созданы на их основе с помощью определения в численном виде ключевых точек. Программа воспроизводит линии посредством соединения ключевых точек. С векторными данными всегда связаны информация об атрибутах и набор соглашений. Соглашения могут быть заданы как явно, так и неявно, но они программно зависимы. В компьютерной графике термин вектор используется для обозначения части линий и задается конечным набором точек. Растровые данные – набор числовых значений, определяющих цвета отдельных пикселей. Пиксели – цветовые точки, расположенные на правильной сетке и формирующие образ. Техническим растром является массив числовых значений, задающих цвета отдельных пикселей при отображении образа на отдельном устройстве вывода. Для обозначения числового значения в растровых данных, соответствующих цвету пикселя в изображении на устройствах вывода используется термин пиксельное значение. Термин bitmap используется для обозначения массива пикселей, независимо от типа, а термин битовая глубина используется для указания размеров этих пикселей, выраженных в битах или байтах.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
6. Физические и логические пиксели. В компьютерной графике для указания местоположения графич. объекта используется математические координаты, хотя поверхность отображения устройства вывода – реальный физический объект => есть разница между логическими и физическими пикселями.
Физические пиксели – реальные точки отображаемые устройством вывода, т.е. наименьшие физические элементы поверхности отображения, которые можно обработать аппаратным или программным способом. На практике устройства вывода формируют отдельный пиксель их нескольких более мелких элементов, в большинстве устройств вывода – это несколько по-разному окрашенных точек, которые человеческий глаз находясь на достаточном расстоянии воспринимает как единный однообразный пиксель. Так как физические пиксели занимают определенную площадь поверхности отображения, то на расстоянии между двумя соседними пикселями вводится ограничение.
Логические пиксели – это математические координаты, которые имеют местоположение, но не занимают физическое пространство. Поэтому при отображении значения логических пикселей из растровых данных в физические пиксели экрана должны учитываться реальный размер и расположение физических пикселей.
Пиксельная глубина устройства отображения – принятая глубина 1,4,8,24,32 бит. Изображения, которые хорошо визуализируются в ч/б исполнении логично хранить в виде однобитовых данных. Для устройств, которые способны достичь и превысить цветовосприятие чел. Глаза исп-ся термин «полно цветные» или «truecolor». |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
7. Отображение цветов. Набор цветов, который задаётся пиксельными значениями в файле, не всегда совпадает с тем, который может быть отображен на физическом устройстве вывода. Задача согласования набора цветов решается программой визуализации, которая осуществляет преобразование цветов, заданных в файле, в цвета устройства вывода. Существует 2 варианта: 1 если количество цветов, заданных пиксельными значениями в файле значительно меньше количества цветов, которое способно отобразить устройство вывода. 2. устройство вывода способно отобразить меньше цветов, чем записью в исходных данных Программа визуализации сопоставляет наборы цветов источника и адресата, количество цветов приводится в соответствие с тем количеством цветов, которое способно отобразить устройство. Этот процесс называется квантованием и сопровождается потерей цветов. Оно приводит к появлению артефактов квантования (дополнительные контуры, муар). Иногда артефакты квантования находят применение: используются для удаления шумов в изображении, такой процесс квантования называется сверткой.
|
8. Пиксельные данные и палитры. Пиксельные данные, содержащие более 1 бита/пиксель могут быть представлены: - как набор индексов палитры цветов; - непосредственно определяться в соответствии со схемой определения цветов. Палитра – карта цветов – карта индексов – таблица перекодировки. Она представляет собой одномерный массив цветовых величин. С помощью палитры цвета задаются косвенно, посредством указания их позиций в массиве. При использовании этого метода данные записываются в файл в виде индексов, что позволяет сократить объем памяти.
Растровые данные, в которых используется пал. называется растровыми данными с косвенными или псевдо-цветной записью. Пал. обычно включается в тот же самый файл, где содержатся из. Каждые пиксельные значения рассматриваются в таком файле как индекс палитры. Программа визуализации читает из файла письменные значения и обращается к палитре за значением цвета.
768*320*200 пикс./байт = 6400 байтов + 768=64768 байтов. 320*200*3 пикс./байт = 192000 байтов Исп. палитры целесообразно только когда объем памяти, занимаемой палитры во много раз меньше объема растровых данных. Косв. задание цветов удобно в случаях, когда необх. знать реальное кол. цветов в изображении, так же когда нужно изменить цвета в исходном изображении.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
9. Цветовые пространства. Чтобы передать цвет нужно задать несколько значений, обычно 3, определяющих интенсивность каждого из основных цветов, которые смешивают для получения составных цветов, составной цвет задается упорядоченным набором значений и представляет собой точку в цветовом пространстве. Наиболее распространенным способом передачи цвета является модель RGB. Так же эти данные могут задаваться в процентах. Порядок следования может быть произвольным, а порядок и обработка цветовых составляющих в различном порядке. Цветовое пространство LAB представляет цвет в трех каналах: один канал выделен для значений яркости (L - Lightnes) и два других для цветовой информации (А и В). Цветовые каналы соответствуют шкале, а не какому-нибудь одному цвету. Канал А представляет непрерывный спектр от зеленого к красному, в то время как канал В - от синего к желтому. Средние значения для А и В соответствуют реальным оттенкам серого.
|
10. Типы палитр. Различают одноканальные и многоканальные палитры. Одноканальная палитра предусматривает только одну цветовую величину для каждого элемента изображения, причем эта цветовая величина явно указывает цвет пикселя. (G)=220. Многоканальная палитра предусматривает 2 или более цветовые величины для каждого элемента. Палитры могут быть как пиксельно- так и плоскостно-ориентированные. Пиксельно-ориентированные палитры хранят все данные о цветах пикселей в виде последовательности битов в каждом элементе массива. В плоскостно-ориентированной палитре цветовые составляющие пикселей плоскостно разделены. Величины, соответствующие определенному цветовому каналу сохраняются вместе, и палитра состоит из 3-х одноканальных палитр, по одной для каждого цветового канала.
Одноканальная пиксельно-ориентированная палитра содержит одно пикс. значение на элемент палитры. Многоканальная пиксельно-ориентированная палитра также хранит по одному пикселю на элемент, но каждый пиксель содержит 2 или более цветовых канала. Одноканальная плоскостно-ориентированная палитра хранит 1 пиксель на элемент и 1 бит на плоскость. Многоканальная плоскоориентированная палитра содержит одно значение цветового канала на элемент и несколько разноцветных плоскостей. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
11. Цвет. Рецепторы человеческого глаза различают длину волны 380-770 нм. Волны различной длины воспринимаются чел. глазом по-разному. Система визуального восприятия легче различает близкорасположенные цвета, особенно если они разделены видимым объектом. Для восприятия цвета важное значение имеет то, как этот цвет получен. На данный момент не существует идеальной модели представления цвета из-за разного способа получения цвета на различных устройствах. Все множество цветов, которые получаются путем смешивания основных цветов образует цветовую гамму.
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
12. Цветовые модели. Аддитивная – новые цвета получаются при сложении основного цвета с черным. Чем больше интенсивность добавляемого цвета, тем ближе результирующий цвет к белому. Смешивание всех основных цветов дает чисто белый цвет, если значение их интенсивности максимальны, и черный, если значения интенсивности минимальны (равны нулю) Аддитивные цветные среды являются самосветящимися. Например, цвет на мониторе – аддитивный. Субтрактивная – для получения всех цветов основные цвета вычитаются из белого. Чем больше интенсивность вычитаемого цвета, тем ближе результирующий цвет к черному. Смешивание всех основных цветов дает черный, когда значение интенсивности максимально, и белый, когда значение интенсивности равно нулю. В природе субтрактивные среды являются отражающими. Все изображения, визуализированные на бумаге, это пример субтрактивной цветной модели. RGB – аддитивная цветовая модель, основанная на 3-х цветах красном, зеленом, голубом. Если все три цвета равны, то это оттенки серого цвета. CMY(Cyan Magenta Yellow) – голубой, пурпурный, желтый. Это субтрактивная цветовая модель, основанная на том, что при освещении каждый из основных цветов поглощает дополняющий его цвет (голубой поглощает красный, пурпурный – зеленый, желтый – синий) Теоретически при вычитании всех основных цветов, суммой является черный, но на практике получить черный сложней, поэтому модель дополнена отдельным черным цветовым компонентом. Цветовая модель CMYK (К от Black – последняя буква). К – черный цвет, который является в этой модели основным. Результат применения этой модели называется 4-х цветной печатью. Данные в модели CMYK представляются либо цветным триплетом, аналогичным RGB, либо 4-мя величинами. Если данные представлены цветным триплетом, то отдельные величины противоположны модели RGB. 4-х цветные величины модели CMYK задаются в процентах. HSV (Hue Saturation Value – оттенок, насыщенность, величина). В этой модели при моделировании новых цветов не изменяют их цвета, а изменяют их свойства. Весь оттенок – это цветовая насыщенность (цветность), которая определяет количество белого в оттенке. В полностью насыщенном 100%-ном оттенке не содержится белого, и такой оттенок считается чистым. Красный оттенок 50%-ной насыщенности – это розовый. Величина, которая называется яркостью, определяет интенсивность света. |
Оттенок с высокой интенсивностью является очень ярким, низкой – темным. Черный и белый цвета смешиваются с основными красками для получения оттенков: tint, shade, tone. Оттенок tint – является чистым, полностью насыщенным цветом, смешанным с белым. Оттенок shade – полностью насыщенный цвет смешанный с черным. Tone – полностью насыщенный цвет, к которому добавлен серый. Насыщенность представляет собой – количество белого, величина – кол-во черного, а оттенок это тот цвет, к которому добавляется белый и черный. Существуют модификации модели: HIS(,,интенсивность) HSL(,,освещенность) HBL(,яркость,освещенность) Модель YUV – модель состоит из 3 сигналов: Y, U, V. Основана на линейных преобразованиях данных VGB – изображений и применяется для кодирования цвета в телевидении. Y – сигнал определяет полутон или яркость, U и V – цветность. На этой модели основаны YcbCr и YpbPr. Полутоновая модель – состоит из черн., белого, оттенков серого цвета. Белый, черный соответствуют граничным значениям диапазона, черный – min интенсивность, белый – max. В общем случае это гамма всех цветов серого цвета, каждая точка состоит из 3-х составляющих с равной величиной не имеющих насыщенности и различающихся только интенсивностью. Рассмотрим основные цвета в моделях RGB, CMY, HSV.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
13. Наложение изображений и прозрачность. Если изображение не прозрачно, то не существует условий, при которых можно наложить одно изображение на другое и видеть при этом элементы нижнего изображения. Для того, чтобы изображения могли накладываться задается прозрачность изображения на уровне либо всего изображения, либо фрагмента этого изображения, либо даже отдельного пикселя. Прозрачностью управляют при помощи дополнительной информации, содержащейся в каждом элементе пиксельных данных. Каждому пиксельному значению добавляется по крайней мере 1 оверлейный бит. Установка только оверлейного бита позволяет программе визуализации выборочно игнорировать те пиксельные значения, у которых этот бит установлен. 16 бит = 5 бит + 5 бит + 5 бит + 1 оверлейный бит Программа визуализации может переключить оверлейный бит, что будет интерпретироваться как команда: игнорировать данный пиксель. Т.о. появится возможность наложить 2 изображения, причем переключить оверлейные биты нужно в верхнем изображении, чтобы через него было видно нижние. Программа визуализации может выборочно переключать оверлейный бит пиксельных значений заданого цвета, а также отключить отображение любых областей изображения, не окрашенных в данный цвет. Процесс отключения любых областей изображения и наложение разных изображений называется цветной рирпроекцией. Существует также другой вариант наложения изображений за счет изменения прозрачности нижней и накладываемых картинок, в этом случае каждое пикс. значение содержит не 1 оверлейный бит, а обычно 8. 32 бит = 8 бит + 8 бит + 8 бит + 8 бит для задания прозрачности 8 бит прозрачности так же называют -каналом. «0» указывает на то, что каждый пиксель полностью прозрачен, «255» указывает что полностью не прозрачен. Данные о прозрачности могут сохранятся как в виде пиксельных данных, так и в виде 4-й плоскости, сохраненные тем же способом, что и данные палитры. Кроме того информация о прозрачности так же может сохранятся в виде отдельного блока, не зависящего от остальных данных изображения. Это позволяет манипулировать данными о прозрачности отдельного от данных изображения. |
14. Векторные файлы. Файлы в которых содержится мат. описание всех отдельных элементов изображения относительно точки начала координат, исп. программу визуализации для конструирования конечного изобр. Вект. файлы строятся не из описания пиксельных значений, а из описания элементов из. или объектов. Вект. данные вкл. данные о типе линий и ее атрибутах, линии исп. для построения геом. фигур, те в свою очередь могут быть исп. для создания объемных 3D – фигур. Векторные данные предст. собой список операций черчения и мат. описаний эл. из., записанных в файле в той после., в которой они создавались. Простейшие вект. форматы исп. текстовым ред.и и эл. табл.. Но большинство вект. форматов разр. для хранения и создания рисунков САПР. Большинство вект. форматов могут так же содержать внедренные в файл растровые объекты или ссылку на растр. файл (технология OPI-технология, позволяющая импортировать не ориг. файлы, а их образы, создавая в прог. лишь копию низкого разрешения (эскиз) и ссылку на оригинал. В проц. печати на принтер, эскизы подменяются на ориг. файлы. Применение OPI, вместо простого внедрения дает возм. экономить ресурсы комп.). Сложность при передаче данных из одного вект. формата в другой закл. в исп. программами разл. алг., разной мат. при постр. векторных и описании растр. объектов. Преимущества: - в/ф наиболее удобны для хранения изображений, которые могут быть разложены на простейшие геометрические объекты. - в/ф легко масштабируются и поддаются любым манипуляциям, позволяющим адаптировать их к различным устройствам вывода. - в/ф, содержащие текстовые данные в формате ASCII, могут быть легко модифицированы с пом. простых средств редактирования текста без ущерба для других объектов изображения. Недостатки: - векторные файлы неудобно применять для хранения сложных изображений, как фотография. - внешнее представление векторных изображений может изменяться в зависимости от отображающей их программы; - векторные данные плохо отображаются на растровых устройствах вывода. - визуализация векторных данных может потребовать значительно больше времени, чем визуализация растровых данных равной сложности. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
15. Структура векторных файлов. Базовая структура векторного файла – заголовок и векторные данные.
Когда в файл требуется записать дополнительную информацию, которая не помещается в заголовок, либо появляясь в процессе изменения файла, к нему добавляется концовка, либо палитра. Заголовок. Состоит из числа или строки, идентифицирующих файловый формат, номера версии и цветовой информации. Может содержать значение атрибутов по умолчанию, которые применяются к любым элементам векторных данных этого файла, сведения о высоте и ширине изображения, его позиции на устройстве вывода, а также информацию о количестве слоев изображения. Векторные данные. Векторные данные содержат информацию об отдельных объектах изображения. Элементы являются наименьшими частями изображения. Каждый элемент векторных данных либо однозначно связан с информацией по умолчанию, либо сопровождается информацией, задающей его размер, форму, относительную позицию в изображении, цвет и другие атрибуты. В векторных форматах элементы векторных данных поименованы и разделены специальным символом. Можно задать по умолчанию значение линии и значение цвета. Палитра и цветовая информация. Векторные файлы могут содержать палитры векторных данных, прежде чем воспроизводить изображение, программа визуализации должна найти определение этого цвета в палитре файла. Концовка векторных файлов. Концовка, по крайней мере, должна содержать маркер конца файла. Обычно, если концовка содержит дополнительную информацию, она не является обязательной для корректной интерпретации данных файла, но может давать дополнительную информацию о количестве объектов изображения, количестве цветов в изображении, о дате создания, о времени, имени разработчика и т.д. |
16. Преимущества и недостатки векторных файлов. Преимущества: - в/ф наиболее удобны для хранения изображений, которые могут быть разложены на простейшие геометрические объекты. - в/ф легко масштабируются и поддаются любым манипуляциям, позволяющим адаптировать их к различным устройствам вывода. - в/ф, содержащие текстовые данные в формате ASCII, могут быть легко модифицированы с пом. простых средств редактирования текста без ущерба для других объектов изображения. Недостатки: - векторные файлы неудобно применять для хранения сложных изображений, как фотография. - внешнее представление векторных изображений может изменяться в зависимости от отображающей их программы; - векторные данные плохо отображаются на растровых устройствах вывода. - визуализация векторных данных может потребовать значительно больше времени, чем визуализация растровых данных равной сложности. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
17. Растровые файлы. Растровый файл представляет из себя прямоугольную матрицу (bitmap), разделенную на маленькие квадратики - пикселы (pixel - picture element). Растровые файлы можно разделить на два типа: предназначенные для вывода на экран и для печати. Растровые форматы, предназначенные исключительно для вывода на экран имеют только экранное разрешение (на квадратный дюйм экрана приходится 72 пиксела), то есть один пиксел в файле соответствует одному экранному пикселу. На печать они выводятся так же с экранным разрешением. Растровые файлы, предназначенные для допечатной подготовки изданий имеют, подобно большинству векторных форматов, параметр Print Size - печатный размер. С ним связано понятие печатного разрешения, которое представляет из себя соотношение количества пикселов на один квадратный дюйм страницы (ppi, pixels per inch или dpi). Печатное разрешение может быть от 130 dpi (для газеты) до 300 (высококачественная печать), больше почти никогда не нужно. Растровые форматы, так же отличаются друг от друга способностью нести дополнительную информацию: различные цветовые модели, вектора, Альфа-каналы, слои различных типов, интерлиньяж (черезстрочная подгрузка), анимация, возможности сжатия и другое. |
18. Структура растрового файла.
Заголовок Палитра Растровые данные Концовка
Если файловый формат позволяет хранить
несколько изображений, то после
заголовка в файле размещается каталог
изображений, который содержит информацию
о смещении начальных позиций всех
изображений в файле.
Заголовок Палитра Каталог изображений Растровые данные
изображения 1 Растровые данные
изображения 2 . . . Растровые данные
изображения N Концовка
Если файловый формат позволяет иметь
каждому изображению свою палитру, то
она сохраняется непосредственно перед
данными того изображения, с которым
она связана. В таком случае структура
изменится, и будет иметь вид.
Заголовок Каталог изображений Палитра 1 Растровые данные
изображения 1 . . . Палитра N Растровые данные
изображения N Концовка
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
19. Заголовок растрового файла. Заголовок – раздел данных и символов в формате ASCII данных, который хранит общую информацию о растровых данных, хранящихся в файле. Типичный набор полей заголовка: Идентификатор файла Уникальное ID-значение, идентификатора формата. Позволяет программе определить формат графического файла, с которым она работает. Идент. файлов выбираются разраб. произвольно и содержат последовательность символов ASCII. Версия файла Т.к. версии одного и того же формата могут иметь различные характеристики, то после идент. файлового формата программа должна проверить номер версии, чтобы опред. сможет ли она обраб. данные, содерж. в этот файле. Информация, описывающая из. Кол-во строк наз. высотой из. или кол-м строк развертки. Содержит значение, опред. кол-во строк развертки растровых данных. Кол-во пикселей в строке наз. шириной из. или шириной строки-развертки. Кол-во битов на пиксель – опред. размер данных, необх. для описания каждого пикселя в цветовой плоскости, т.е. поле характеризует пиксельную глубину. Если растровые данные были записаны в виде послед. цветовых плоскостей, то добавляется поле – количество цветовых плоскостей. Тип сжатия. Если с целью уменьш. объема файла формат поддерж. какой-нибудь вид кодирования, то в заголовок должно быть включено поле – тип сжатия. Нек. форматы поддерж. несколько алг. компрессии, все они должны быть перечислены в этом поле. Текст описания. Комментарии содержат произв. симв. в формате ASCII, например, название изображения, имя автора, имя файла, имя программы, исп. для создания изображения. Неиспользуемое пространство. В конце заголовка может распол. неиспользуемые поля, наз. зарез. простр. или зарез. полями. Они не содержат данных, не описываются и не структурируются. Если возн. необх. расширить файловый формат, то сведения о новых данных заносятся в зарез. пространство.
|
20. Растровые данные. В большинстве форматов располагаются непосредственно после заголовка, но могут быть и в любом др.месте растрового файла. Т.к. после заголовка в файле могут быть палитра или какие-нибудь др.данные. Тогда в заголовке в поле смещения данных изображения или в поле каталог изображений указывается место положения начала данных изображения в файле. Растровые данные, состоящие из пиксельных значений обычно выводятся на устр-во в виде строк развертки по всей ширине поверхности изображения, но иногда растр.данные записаны в файле в виде плоскостей. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
21. Организация данных в виде строк развертки При такой орг. пикс. данные в файле, описывающем это изо. представляют собой послед. наборов значений, где каждый набор соотв.т строке из. Несколько строк представлены некоторыми наборами, записанными в файл от начала до конца. Если известен размер каждого пикселя из. и кол-во пикселей в строке, то можно рассчитать смещения начала каждой строки в файле. Пусть в строке 21 пиксель, на 1 пиксель – 8 бит(1 байт), тогда смещение будет: 1строка: 0…..20;2строка: 21…41;3строка: 42…62; 4строка: 63… Если 24 бита, то 0…62; 63…125; 126… Сущ. правило, согласно кот. строки растровых данных выравниваются по границе байта. Пиксельные данные, организованные в виде строк развертки, могут быть сохранены в файле 3 способами: в виде непрерывных данных, в виде полос, в виде фрагментов. Непрерывные данные Это простейший способ организации данных, когда данные записываются в файл непрерывно строка со строкой. При воспроизведении данные читаются в том же порядке, в котором были записаны, большими порциями, быстро и легко собираются в памяти. Полосы. При такой орг. изображение хранится в виде полос, каждая из которых содержит непрерывно записанные строки. Общее из. предст. несколькими полосами. Каждая полоса может храниться в файле отдельно друг от друга. Полосы разделяют изображение на несколько сегментов, каждый из которых всегда имеет ширину ту же, что и ориг. из. Полосы облегчают управление данными на компьютерах с ограниченной памятью. Пример: 1280x1024. на 1 пиксель – 8 бит инфо, т.е. 1 байт на пиксель. Т.е. получим изображение размером 1310720 байт (1280 Кб, 1,25 Мб). 128 строк x 8 полос = 1024. 160 Кб на обработку одной полосы. Если на 1 пиксель приходится 3 байта, то на все изображение необходимо: Vпам=1310720x3 =3932160 байт=3,75 Мбайт На одну полосу: Vпам/8=480 кбайт Фрагменты. Фрагменты подобны полосам, но каждый фрагмент соотв. верт. прямоуг. обл. из. Фрагменты могут иметь любую ширину от 1 пикселя до ширины всего из. Фрагменты орг. т.о., что пиксельные данные соотв. одному фрагменту имеют объем, кратный 16 Кб(8), а их высота и ширина кратны 16 пикселям. Если данные из. орг. в виде фрагментов, то фрагментируется все изображение, все фрагменты имеют одинаковый размер и не перекрываются. Фрагментация данных позв. опт. степень сжатия путем прим. к разл. частям из. разл. схем сжатия. Фрагменты можно раскод. незав. друг от друга. Для этого в загол. файла должны содерж. свед. о кол-ве фраг., их разм. и смещ.. |
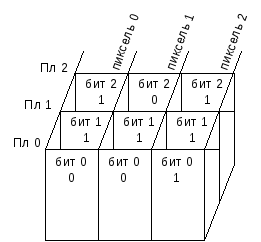
22. Организация данных в виде плоскостей. В таких файлах данные изображения делятся на 2 и более плоскости, наз. плоскостными файлами. Изображения, которые исп. несколько цветов наз. составными, они могут быть представлены несколькими блоками растр. данных, причем каждый блок будет содержать 1 из цветовых составляющих, использованных в данном изображении. Конструирование каждого блока – это разложение изображения на цветовые составляющие. Блоки могут быть сохранены в файле последовательно или физически раздельно. Организация данных в виде плоскостей – это обычная ориентация на какое-либо устройство вывода, конструкция которого позволяет в каждый момент времени только 1 цветом. Рассм. пример, состоящий из 6-ти пикселей, каждый пиксель представим сначала в виде строк развертки, потом в виде плоскостей. (00,01,02) В виде строк развертки: (00,01,02) (03,04,05) (06,07,08) (09,10,11) (12,13,14) (15,16,17) В виде плоскостей:
Пиксельные данные из плоскостного файла конструируются в отдельном буфере и программа, обслуживающая устройства вывода может обработать их как плоскостями, так и попиксельно.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
23. Преимущества и недостатки растровых файлов. Преимущества: - растровые файлы спец-но разрабатывались для хранения реальных изображений, полученных со сканирующего, фотографич., видеоизображений; - пиксельные данные могут изменяться индивидуально или в большими группами с помощью палитры; - легко преобразуются для передачи на точечное устройство вывода. Недостатки: - имеют очень большой размер, особенно при многоцветном изображении; - применение различных схем сжатия уменьшает размер, но необходимость распаковки перед исп. замедляет процесс чтения и визуализации изображения; - плохо поддаются масштабированию.
|
24. Сжатие данных. Сжатие данных – процесс, применяемый для уменьшения физич. размера блока инф. Сжатие – один из типов кодирования. Программа-компрессор сжимает, а программа-декомпрессор восстанавливает данные. Почти каждый современный растровый формат вкл-ет в себя какой-нибудь метод сжатия. Схемы сжатия, применяемые наиболее широко: - RLE – метод группового кодирования; - LZV – метод Лемпела-Зива-Велча; - CCITT – метод, частным случаем которого явл-ся алгоритм Хаффмана; - DCT – метод дискретных косинус-преобразований (применяется при сжатии jpeg); - фрактальное сжатие. В растр. файлах обычно сжимаются только данные изображения, заголовок и все остальные структуры типа таблицы цветов, концовка и т.д. остаются несжатыми. Векторные файлы вообще не имеют собственной схемы сжатия, т.к.: данные уже представлены в компактной форме; вект. изображения читаются с маленькой скоростью, если добавить и распаковку файла, то этот процесс станет еще более медленным; если вект. файлы сжимаются, то сжимается весь файл целиком, включая заголовок (сжатие архиваторами zip, rar и т.д.)
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
25. Физическое и логическое сжатие. Алгоритмы сжатия исп. для повторного кодирования данных в др.более компактную форму, которая позволяет передать ту же инф. Различие между методами физ. и лог. сжатия основаны на том, как данные преобразуются. При физ. сжатии данные преобразуются без учета содержащейся в них информации, происходит просто преобразование серии битов из одного шаблона в др. более компактный. Алгоритм физ. сжатия удаляет существующую в данных избыточность. Методы лог. сжатия явл. процессом лог. перестановки, т.е. заменой одного набора алфавитных, цифровых или др. двоичных символов другим. Лог. сжатие вып. только на символьном или более выс. уровне, основано на инф. содержащейся в исх. данных. Лог. сжатие не применяется для данных изображения. Методы физ. сжатия делятся на две категории: 1) сжатие всего файла (программа сжатия считывает все данные, применяет к ним сжимающий алгоритм и создает новый файл. Выигрыш в размере файла значительный, но файл нельзя использовать ни одной программой, пока он не будет восстановлен до исх.состояния. Поэтому такое сжатие применяется только для длит. хранения или для пересылки); 2) сжатие, включенное в структуру файла (программы, предназначенные для чтения файлов таких форматов, способны считать данные при распаковке файла. Внутр. сжатие файлов особенно удобно для граф. файлов, когда растр. данные этого файла занимают в памяти очень много места; когда в файлах встречаются большие объемы повторяющихся данных). |
26. Адаптивное, полуадаптивное и неадаптивное кодирование. Неадапт. кодировщики содержат статич. словарь предопределенных подстрок, о которых известно, что они появл. часто в кодированных данных. Напр., неадапт. кодировщик для сжатия англ.текстов может содержать and(00), but(01), the(10), from(11). Адапт. кодировщик не содержит предопределенных правил для сжимаемых данных. Адапт. компрессоры, такие как LZV не зависят от типов обрабатываемых данных, поскольку строят свои словари полностью из поступивших данных, т.е. они строят динамич. фразы в процессе кодирования. Адапт. компрессоры настраиваются на любой тип вводимых данных, добиваясь при этом максимально возможной степени сжатия. Метод полуадапт. кодирования основан на применении обоих методов кодирования, работает в 2 подхода: при 1-м как адаптивный кодировщик, т.е. просматривает все данные и строит свой словарь, при 2-м – как неадап. кодировщик, выполняя кодирование на основе полученных на 1-м этапе подстрок, что позволяет сначала построить оптимальный словарь, перед тем, как приступить к кодированию.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
27. Сжатие с потерями и без потерь. При сжатии без потерь порция данных сжимается, а затем распаковывается, и содержащаяся в данных информация сохраняется. Данные не должны быть изменены, потеряны или повреждены. Методы сжатия с потерями предусматривают отбрасывание некоторых данных изображения для достижения лучшей степени сжатия, чем в большинстве алгоритмов сжатия без потерь. Методы сжатия с потерями основаны на том, что небольшие изменения в пиксельных значениях многоцветных изображений могут быть не видны человеческим глазом, поэтому они уменьшают размер данных, удаляя цветовую информацию, которая большинством людей не воспринимается.
|
28. Метод группового кодирования или RLE. Алгоритм сжатия, поддерживающийся большинством растровых форматов (tif, wmp и т.д.).Этот алгоритм позволяет сжимать данные любых типов независимо от содержащейся в них информации. Сама информация влияет лишь на полноту сжатия. RLE не достигает большой степени сжатия (3:1), но выполняется легко и быстро, является альтернативой сложным методам. Суть метода: RLE уменьшает физический размер повторяющихся строк символов. Такие повторяющиеся строки называются группами и обычно кодируются в 2-х байтах. 1 байт определяет количество символов в группе и называется счетчиком группы. Кодируемая группа содержит от 1 до 128 или от 0 до 256 символов, что записывается в счетчик группы как количество символов – 1(т.к. считают с 0). 2 байт содержит значение символов группы и называется значением группы.
Для кодирования в RLE требуется минимум 2 байта. Эффективность сжатия зависит от типа данных изображения. Для сложного изображения с большим количеством цветов групповое кодирование практически не используется. Группа из одиночных символов, закодированная с помощью RLE-пакета, займет в 2 раза больше памяти, чем непосредственное представление этих данных. Групповое кодирование не является форматом файла. Это метод кодирования, который может быть включен в некоторые графические форматы (gif, tif, jpeg) Варианты группового кодирования. Обычно с помощью RLE данные изображения кодируются последовательно, по линиям развертки слева направо. Существуют альтернативные схемы кодирования, когда данные кодируются колонками вдоль оси у или 2-хмерными фрагментами вдоль оси х. Существует разновидность группового кодирования RLE с потерями. Заключается в отбрасывании данных в процессе кодирования (отбрасывается младший бит в каждом пикселе). Это повышает степень сжатия сложных изображений, но использовать этот метод можно лишь для многоцветных реалистичных изображений. Ещё одно преимущество построчного кодирования – программа легко воспроизводит любую часть изображения. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
29. RLE схемы битового, байтового и пиксельного уровней. Различие между этими способами кодирования заключается в формировании пакетов, соответствующих группам символов. Большинство форматов графических файлов в зависимости от уровня обрабатываемых данных выделяют 3 класса RLE схем. RLE-схемы битового уровня. Кодируют в группы биты строк развертки, игнорируя при этом границы байтов и слов. Используются только для обработки монохр., т.е. однобитовых из., содержащих дост. количество битовых групп.
RLE-схемы байтового уровня. Кодируют в группы одинаковые байтовые значения, игнорируя отдельные биты и слова. Исп для из., в которых каждый пиксель содержит 8 бит информации.
|
RLE-схемы пиксельного уровня Применяется, когда для хранения одного пиксельного значения используется два или более смежных байтов изображения. На пиксельном уровне биты игнорируются, а байты принимаются во внимание только для идентификации цветового канала.
Сведения о количестве битов или байтов в пикселе записаны в заголовке файла из., там же сведения о схеме кодирования. В RLE схемах пиксельного уровня счетчик содержит сведения о количестве пикселей, а не о количестве байтов. Существуют литеральные группы пиксельного уровня.Самый старший бит 1-го байта группы содержит указатель на то, является ли группа литеральной. 7 младших битов этого байта содержат счетчик группы. Остальные 3 байта информации содержат значения группы. Если старший бит установлен в 1, то это закодированная группа. Закодированные группы декодируются посредством чтения значения группы и повторения его столько раз, сколько указано в счетчике +1. Если самый старший бит установлен в 0, то он указывает на литеральную группу, т.е. следующие байты в количестве, указанном в счетчике группы +1, должны читаться напрямую из закодированных данных. В литеральных группах максимальное значение счетчика 128 байт. Применение литеральных RLE групп при обработке потока данных, содержащих много одно- и 2-хпиксельных групп более эффективно, чем кодирование этих групп, т.к. позволяет избежать отрицательного сжатия, т.е. увеличения объема данных в процессе сжатия. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
30. Схема RLE с использованием флага. Группа представлена 3 байтами 1-ый байт – флаговое значение, указывает на то, что следующие 2 байта являются частью закодированного пакета 2-ой байт – счетчик группы 3-ий байт – значение группы Если в процессе кодирования встречаются группы, состоящие из 1, 2х или 3х символов, то эти данные не кодируются, а непосредственно записываются в поток сжатых данных.
Для значения флага выбирают значение, которое редко встречается. При декодировании флаговое значение анализируется прочитанный символ, если это флаговое значение, то следующий байт обрабатывается как счетчик., 3-ий байт – как значение. Результат записывается в выходной поток данных. Если прочитанный символ не является флаговым значением, то он записывается в выходной поток напрямую. Недостатки: Минимальный размер группы, пригодный для кодирования таким способом возрастает с 3 до 4 одинаковых символов. Если поток незакодированных данных содержит значение символов, равное флаговому значению, то этот символ должен быть закодирован в 3-х байтовый пакет. Алгоритмы RLE используют такие флаговые значения, которые в потоке несжатых данных встречаются крайне редко.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
31. RLE пакеты вертикального повторения. Многие RLE схемы для повышения эффективности сжатия используют пакеты повторения строк развертки, называемые пакетами вертикального повторения. Этот пакет не хранит реальных данных строк развертки, он лишь указывает на то, что необходимо повторить предыдущую строку. Пакет вертикального повторения, если содержит 1 байт информации, то это счетчик группы =0, указывает на то, что строка должна быть повторена 1 раз. Если за этим байтом следует значение, то это значение повторяющихся строк развертки. Т.е. одним пакетом, состоящим из счетчика группы + значением, можно описать количество повторяющихся строк.
100 строк развертки белых пикселей, в строке – 12380 пикселей 1 строка – 5 пакетов по 256 пикселей
В данном примере: 10 байт – описывается сама строка 1 байт – маркер конца строки 2 байта – пакет вертикального повторения (всего 13 байт)
|
32. Сжатие методом LZW . Этот метод сжатия без потерь Этот метод сжатия графических данных используется в файлах формата TIFF, PDF, GIF, PostScript и других. включен в стандарт сжатия для модемов, а также исп. в архив прогр. (zip, compress, avj) был разработан в 1977 Лемпелом и Зивом. В 84 был доработан Терри Велчем. Алг. LZW позволяет работать с любым типом данных, т к обеспечивает быструю распаковку и сжатие данных. Сжимает данные путем поиска одинаковых последовательностей (они называются фразы) во всем файле. Выявленные последовательности сохраняются в таблице, им присваиваются более короткие маркеры (ключи). Так, если в изображении имеются наборы из розового, оранжевого и зеленого пикселов, повторяющиеся 50 раз, LZW выявляет это, присваивает данному набору отдельное число (например, 7) и затем сохраняет эти данные 50 раз в виде числа 7.Степень сжатия 3:1и 4:1.Хорошо сжимаются насыщенные узоры содержащим большое кол-во однотонной краски или повторяющиеся цветовые узоры. LVZ не явл. форматом но включен в различные форматы файлов. Алгоритм распаковки аналогичен алг. сжатия(наоборот). Работа алг. начинается с с проверки наличия строки (очередного символа из вх. потока) в таблице, т к первые 255 символов уже определены, т.е. не находится строка в таблице символов, в вых поток записываются имеющиеся значения по таблице ASCI, а в табл. добавляется след значение равное строка+символ. Этот процесс продолжается до тех пор пока не закончится вых поток и не сформированы все коды. Алгоритм LZW относится к алг. подстановок, те к методам адаптированного кодирования, базирующегося на словарях. Словарь строится в процессе кодирования. При сжатии текстовых файлов LZW инициализирует 1-е 256 записей словаря однобитовыми символами ASCI. Эти записи представляют значения, кот, встречаясь в потоке данных в различных комбинациях строят новые подстроки, записываются в конец словаря. Как Кодировщик так и декодировщик, начинают свою работу инициализации словаря этим значением, поэтому декодеру не нужен словарь, т.к. он строит свой в процессе декодирования.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
33. Кодирование CCITT или кодирование по алгоритму Хаффмана. Этот алг разрабатывался для факсимильной передачи изображений по телефонным каналам и сетям передачи данных. Работает с однобитными изображениями, сохраненными в цветовой модели Bitmap. Он настраивался для кодирования каждого растра оптимальным образом. Удаляются повторяющиеся элементы, устанавливается постраничный порядок загрузки страниц через web, с приоритетом сначала для текста, потом графика, наконец шрифты. Если повторяющихся элементов нет, файл, после оптимизации, как правило, несколько увеличивается. В этом алг. исп. таблица кодовых значений, кот. были выбрали заранее для представления документов. Степень сжатия 5:1и 8:1. Кодировщик определяет длину пиксельной группы в строке развертки и вводит двоичное слово, представляющее длину и цвет группы. Кодовые слова берутся из предопределенной таблицы значений представляющих группы белых и черных пикселей. Размер кодового слова определяется на основе стат. усредненной частоты появления группы. Длине групп встречающихся более часто присваивается меньшее кодов слово, чем дл групп, появляющихся менее часто. По алг. Хаффмана, сжимая файл, необходимо прочитать его и посчитать сколько раз встречается каждый символ из набора ASCI кодов. После подсчета частоты вхождения каждый символа формируется бинарное дерево. Кодирование файла всегда начинается с корня, каждый левый поворот-0, каждый правый-1. Метод Х базируется на частоте повторения величин, чем чаще встреч величина, тем короче будет заменяющий ее код.
|
34. Сжатие с потерями JPEG. Группа Joint photograph expert group – сформирована в 1982. JPEG – это целый набор методов сжатия, сопровождается потерями, основанный на разнице между пикселами. В процессе кодирования отбрасывается та инф, отсутствие кот трудно заметить визуально. Основан алгоритм на особенностях восприятия человеческим глазом различных цветов, и достаточно громоздок с вычислительной точки зрения, так как занимает много процессорного времени. JPEG - схема спец разрабатывалась для сжатия цветных и полутоновых графич изображений, телевиз-х заставок и др.также исп-ся для сжатия видео из. внутри стандарта MPEG. Степень сж-25:1, 20:1 без изменений качества. Можно отрегулировать качество исползуя q-фактор (quality), изменяющ. в пределах от 1 до 100. При 100 - наилучшее качество при большом размере. JPEG основан на на схеме кодирования кот. основана на дискретных косинус-преобразованиях. JPEG эффективен только при сжатии многоцветных изобр., в кот значения между соседними пикс. незначительны. Пикс. глубина д.б. более 5 битов на цветной канал. Не желательно сохранять с JPEG-сжатием любые изображения, где важны все ньюансы цветопередачи (репродукции), так как во время сжатия происходит отбрасывание цветовой информации. Этот метод сжатия графических данных используется в файлах формата PDF, PostScript, собственно, JPEG и других. Главным недостатком компрессии с частичной потерей качества, является то, что эти потери, выражающиеся в искажении цветового тона или появлении характерной кубической структуры в контрастных участках изображения (так называемые артефакты) возникают каждый раз при сохранении изображения, и накладываются друг на друга при многократном сохранении файла в этом формате.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
35. Этапы сжатия JPEG. Он основан на схеме кодирования с помощью дискретных косинус преобразований (ДКП). ДКП всегда с потерями, но обеспечивает высокую степень сжатия при минимальных потерях. Схема Jpeg , используется только при сжатии многоцветных изображений в которых различие между соседними пиксельными значениями незначительно. Пиксельная глубина >=5 битов на цветовой канал: 65000 цветов. Процесс сжатия делится на: преобразование изображения в оптимальное цветовое пространство субдискретизация усреднением групп пикселей применение ДКП для снижения избыточности данных изображения, квантование блока коэффициентов ДКП, кодирование результирующих коэффициентов. Декодирование Jpeg в обратном порядке. Преобразование изображения: Алгоритм кодирует каждое изображение, основанное на любом типе цветового пространства. Jpeg преобразует каждый компонент отдельно в модель YCB or YCBCR, потому что в ней достигаются нужные: Y – яркость CB,CR – цветность. Субдискретизация компонентов цветности. Воспользовавшись меньшей чувствительностью человеческого глаза, к информации уменьшая количество пикселей для каналов цветности , оставляя без изменения количество пикселей для каналов яркости. При поступлении не сжатых данных в общепринятом формате, т. е. одинаковое разрешение для всех каналов цветности , компрессор Jpeg уменьшает разрешение каналов цветности путем СКЦ или усреднения групп пикселей . Канал яркости с полным разрешением (1:1). Оба канала цветности подвергаются СКЦ (2:1) в горизонтальном направлении и (1:1) или (2:1) в вертикальном, т. е. пиксель цветности охватывает ту же область , что и блок (2:1) ,(2:2) пикселей яркости. Согласно Jpeg эти процессы называются 2h1v and 2h2v. ДКП применяются к любому блоку 8*8 пикселей преобразовывает пространство в его спектральное представление. В спектральном преставлении можно разделить высоко и низко частотную информацию и отбросить высокочастотную информацию без потерь низкочастотной, т. к. высокочастотная информация не воспринимается человеческим глазом. Воздействуя на спектральное представление можно балансировать между качеством воспроизведения и степенью сжатия. Квантование. Прежде чем отбросить объём информации, компрессор делит выходное значение матрицы ДКП на коэффициенты квантования. Коэффициенты квантования – величина обратная Q. После деления результат округляется до целого. Чем больше коэффициент, тем больше данных теряется, т. к. реальное значение всё менее точное. На этом этапе мы управляем Jpg компрессором за счет установки качества. Кодирование результирующих коэффициентов. Они содержат объём избыточных данных кодируемых по алгоритму Хаффмана. Это позволяет понизить объём данных, удалив избыточность информации без потерь.
|
36. Фрактальное сжатие. Фрактал – структура, которая состоит из подобных форм и рисунков, описывается математически и создаются с помощью простых алгоритмов. Делается копия участка из. и идет поиск подобных ему (применяется масштабирование и поворот), если подобные участки есть, создается мат описание данной копии. Обработав так всю поверхность, получим фрактальные коды – систему мат. уравнений. Сильная степень сжатия (пара Мбайт в пару кбайт), архивация кодирование часов, декодир. секунды. Производится миллионы и миллиарды итераций. Возможно масштабирования фрактального изображения. Фр. сжатие сопровождается потерями, нет абс. точного поиска соответствия фракталов. Изменяя параметры сжатия можем добиться, чтобы визуально изображение не имело потерь. Применяется в базах данных изображений. Фр. пакеты: Fractint, FractalTransform.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
37. Сжатие MPEG. Применяются при обработке видео данных. Это метод асиммитричного сжатия. Процесс сжатия более сложен, чем распаковка. Применяется 2 вида сжатия:1) Внутрикадровое кодирование ; 2) межкадровое кодирование. Межкадровое кодирование - основано на кодирование с предсказаниями и интерполятивном кодировании. Кадры, идущие друг за другом, содержат множество идентичных данных, поэтому кодируют лишь изменения в них, в результате на много увеличивается степень сжатия, поскольку кодируется мало информации – кодирование с предсказателями. Межкадровое кодирование ещё уменьшает размер данных, если применить двунаправленные предсказания позволят поддержать текущий кадр, на основе различий между ним, предыдущим и следующим кадрами видео данных – интерполятивное код.-е. Для поддержки межкадрового и внутрикадрового код.-я поток данных содержит 3 типа закодированных данных: I- кадры, B-кадры и P-кадры. I-кадры –внутрикадровое кодирование. В него записан один кадр видео данных, который не связан с информацией любого другого кадра. Каждый поток данных начинается с i-кадра. P-кадр – различие между текущим и представлен i- или p-кадром. B- кадр- состоит из различий между текущим кадром и двумя предыдущим и последним i- или p-кадрами. Между каждым i- кадром распологается 12 в-кадров и p-кадров. Данные декодируются не в том порядке, в котором они распологаются в потоке, т.к. в-кадры связаны с 2 справками i- и p-кадрами, справ-е кадры должны декодироваться раньше, чем в-кадры. Первым декодируется i-кадр, потом p-кадр, только потом в-кадры IP BB PBB PBB-декодирование I-в- и p-кадры сжимаются с прим-м метода сжатия , но в межкадровом код-ии для p-и в-кадром уменьшается также и врем-я изб-ть. На практике размер i-кадра=150кбит, p-кадра=50кбит и в-кадра=20кбит. I- кадры очень похожи на стат-е изображение jpeg. Кодирование с использованием номер внутрикадрового кодирования выполняется гораздо быстрее, чем кодирование межкадрового кодирования. |
38. Внутрикадровое кодирование MPEG. Кадры кодированных в 3 типа: I- кадры, B-кадры и P-кадры. I-кадры – внутрикадровое кодирование. В него записан один кадр видео данных, который не связан с информацией любого другого кадра. Каждый поток данных начинается с i-кадра. Занимает 150 кбит. I- кадры очень похожи на статические изображения jpeg. P-кадр – различие между текущим и представлен i- или p-кадром. B- кадр - состоит из различий между текущим кадром и двумя предыдущим и последним i- или p-кадрами.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
39. Межкадровое кодирование MPEG. Межкадровое кодирование - основано на кодирование с предсказаниями и интерполятивном кодировании. Кадры, идущие друг за другом, содержат множество идентичных данных, поэтому кодируют лишь изменения в них, в результате на много увеличивается степень сжатия, поскольку кодируется мало информации – кодирование с предсказателями.
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
40. Сравнительный анализ MPEG стандартов. MPEG1. Появился в 1992г. Был рассчитан на передачу видео по низкоскоростным сетям и на запись на CD со скоростью 150 кбит/сек. Разреш. спос. картинки снижена по сравн. с разверткой вещательного TV (720*576) в 2 раза по обеим осям, т.е. 288 строк и 360 отсчётов по оси Х в каждом кадре. Super VideoCD. Был разработан для устранения местного эффекта, в котором была добавлена поддержка многонац. звука, было повышено разрешение и снижена степень сжатия. MPEG2. Появился в 1995г. Он не являлся рев. форматом, это эволюционная доработка MPEG1 под новые возм. Он предназначен для обработки видео изображения, соизмеримого по качеству с телевизором при пропускной спос. каналов от 3 до 15 Мбит/сек. Спутниковое TV построено на MPEG2. В 1995 появился DVD=Digital Video Disk. В простейшем виде имеет емкость 4,7Гбайт. Основные отличия MPEG1и 2. Усоверш-ния коснулись всех этапов упаковки файлов. 1.После разбивки видео на кадры и группы кодер теперь анализирует содержание очередного кадра на предмет повторившихся данных. Составляется список оригинальных участков и таблицы повторившихся участков. Оригиналы сохраняются, копии удаляются. Таблицы повторившихся участков пользователем при декодировании. 2. При внутрикадровом сжатии вместо линейного преобразования Фурье применено нелинейное преобразование. 3. Оптимизируется алгоритм предсказания движения. 4. В MPEG2 в процессе кодирования можно задать частные коэффициенты матрицы квантования. Точность квантования: от 8 до 11 бит на одно значение элемента. Стандарт MPEG2 имеет возможность гибкой настройки качества изображения в зависимости от пропускной способности сети или емкости носителя. 5. В части аудио добавлена поддержка многокан. звука Dolby Digital 5.1 MPEG3. Он разрабатывается для пользователя в системах телевидения высокой чёткости НДТV со скоростью потока Д. от 20 до 40 Мбит/сек. MPEG3. стал сост. частью MPEG2 и отд. не упоминается. MPEG4. Появился в конце 1999г. Этот станд. задает принц. раб. с цифр. представлением media-D (контентом) для 3 областей: а) мультимедиа данных; б) графических прил.; в) цифрового TV; В нем определён двоичный язык для описания классов, объектов и сцен(BJFS)=(расш. С++). Помимо работы с аудио и видео-данными стандарт позв. раб. с естественными и синтезированными 2D и 3D объ., производить привязку их взаимного распол. и синхр. их отн. др. др. |
Картинка разделяется на составные элементы, т.е. меди- объекты. Описывается структура этих объектов, их взаимосвязи для того, чтобы собрать их в единую видео- звуковую сцену. Результирующая сцена составляется из объектов, объединенных в иерархическую структуру: 1.неподвижная картинка например фон. 2.видеобъект, например, говорящий человек. 3.аудиобъект, например, голос этого человека. 4.текст, связывающий с данной сценой. 5.синтетические объекты (их не было изначально). 6.текст, из которого в конце синтезируется голос для синтетического объекта. Такой способ представления должен позволять перемещать и помещать объекты в любое место сцены, трансформировать объекты, собирать из отдельных объектов составной объект и производить над ним какие-либо операции, а также менять точку наблюдения за всей сценой. Алгоритм компрессии видео работ также как и в предыдущих стандартах. Отличие только в следующем: 1. кадр не делится на квадратные блоки, кодер оперирует целыми объектами произвольной формы в зависимости от содержимого; 2. применён интеллектуальный способ расстановки ключевых (i) кадров. Ключевые кадры не расставляются с заданной регулярностью, а выделяются кодером только в момент смены сюжета. Эффективность компрессии возросла в несколько раз и теперь фильм длится 1,5-2 часа умещается на КД. Div.X - кодер позволяет настраивать качество, длительность и другие характеристики, компрессировать видео - поток в соответствии со стандартом MPEG4. MPEG7. Был выпущен в конце 2001г. Он обеспечивает формализацию и стандартизацию описания различных типов мультимедийной информации, чтобы гарантировать эффективный и быстрый поиск. Официально этот стандарт называется MCDI(интерфейс описания мультимедийных Д.). В нем определён стандартный набор дескрипторов для различных типов мультимедиа информации. Здесь же стандартизуется способ определения дескрипторов и их взаимосвязи. Основная цель: поиск информации специальными машинами. Задав эскиз получаем набор рисунков, содержащих этот объект, задав объект и его движение получаем видео и анимационных роликов, задав голос получаем певца и набор его песен. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
41. Прикладные программы создания и редактирования растровых изображений. Программа VECTORY предназначена для обработки черно-белых (бинарных) растровых изображений, полученных в результате сканирования любых графических материалов: чертежей, карт, схем, набросков и т.п. Adobe Photoshop позволяет сжимать растровые данные с помощью алгоритма JPEG. Adobe доработала этот способ сжатия. Внутренний формат позволяет записывать изображение со многими слоями, их масками, дополнительными Альфа-каналами и каналами простых цветов, контурами и другой информацией - все, что может сделать Photoshop. В версии 3.0 появляются слои, контуры и RLE-компрессия, в 4-й версии алгоритм улучшается, файлы становятся еще меньше. В версии 5 реализован принципиально иной подход к управлению цветом- была внедрена архитектура управления цветом, появились новые эффекты со слоями, текстом, а так же возможность создавть дополнительные каналы для простых цветов, профили. Однослойный Photoshop Document понимают ряд программ, многослойные могут импортировать например, в Corel PHOTO-PAINT. CorelDRAW 10 предоставляет средства для работы с растровой графикой. Они заключаются, главным образом, в возможности накладывать на изображения фильтры и маски, изменять цветовую модель и разрешение, а также вращать и масштабировать изображение. Для более сложной обработки растровых изображений используется программа Corel PHOTO-PAINT. По своим возможностям Corel PHOTO-PAINT 10 конкурирует, а порой и превосходит Adobe Photoshop. Система манипулирования деталями изображения в виде "объектов" напоминает систему "слоев" в Adobe Photoshop и позволяет обрабатывать нужную часть изображения, не затрагивая остальную. С помощью масок, как и в Photoshop, изменяется прозрачность отдельных частей.
|
42. Прикладные программы создания и редактирования векторных изображений. CorelDRAW 8-ю и 9-ю версии CorelDRAW можно без натяжек назвать профессинальными. В файлах этих версий применяется компрессия для векторов и растра отдельно, могут внедряться шрифты, файлы CorelDRAW имеют огромное рабочее поле 45х45 метров (используют для наружней рекламы); начиная с 4-й версии поддерживается многостраничность, начиная с 7-й - технология OPI (Open Prepress Interface - технология, позволяющая импортировать не оригинальные файлы, а их образы, создавая в программе лишь копию низкого разрешения (эскиз) и ссылку на оригинал. В процессе печати на принтер, эскизы подменяются на оригинальные файлы. Применение OPI экономит ресурсы компьютера (память). CorelDRAW 10 - мощнейшее средство для создания и обработки двумерной векторной графики |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
43. Система автоматизации проектно- чертежных работ AutoCAD. Автокад - основа реализации высокоэффективных технологий в проектировании, позволяющих получать идеальный результат с меньшими затратами. Функциональные возможности Автокада, открытая архитектура, широкие возможности по программированию, связь с базами данных, большой выбор совместимых периферийных графических устройств, наличие сотен постоянно развивающихся прикладных программ на его базе сделали Автокад мировым промышленным стандартом во всех областях автоматизации проектирования.
|
44. Прикладные программы морфирования изображений. Морфинг - это плавное "превращение" одного изображения в другое, во время которого конкретный элемент первого изображения "перетекает" в элемент второго изображения. Hапример, при морфировании одного автомобиля в другой, колесо первого превращается в колесо второго. Компьютер не может выполнить морфинг двух изображений самостоятельно - сначала художнику требуется задать соответствие элементов первого изображения элементам второго а также другие параметры, пользуясь специальным редактором. Способ задания соответствия зависит от редактора - это могут быть точки, линии, полигоны. Программы типа Elastic Reality или PhotoMorph, представлялась возможность выработать нехитрую технику выделения и сопоставления контрастных элементов на изображениях человеческих лиц, костюмов, автомобильных кузовов и т. п. Пользователь задает вектора (начала которых находятся в якорных точках исходного изображения, а концы -- в якорных точках конечного), это позволяет построить векторное поле, оно используется для трансформации изображений при просчете промежуточных фаз морфирования.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
1. История развития компьютерной графики. 2. Графика и компьютерная графика. 3. Графический формат. 4. Графические файлы. 5. Графические данные. 6. Физические и логические пиксели. 7. Отображение цветов. 8. Пиксельные данные и палитры. 9. Цветовые пространства. 10. Типы палитр. 11. Цвет. 12. Цветовые модели. 13. Наложение изображений и прозрачность. 14. Векторные файлы. 15. Структура векторных файлов. 16. Преимущества и недостатки векторных файлов. 17. Растровые файлы. 18. Структура растрового файла. 19. Заголовок растрового файла. 21. Организация данных в виде строк развертки 22. Организация данных в виде плоскостей. 23. Преимущества и недостатки растровых файлов. 24. Сжатие данных. 25. Физическое и логическое сжатие. 26. Адаптивное, полуадаптивное и неадаптивное кодирование. 27. Сжатие с потерями и без потерь. 28. Метод группового кодирования или RLE. 29. RLE схемы битового, байтового и пиксельного уровней. 30. Схема RLE с использованием флага. 31. RLE пакеты вертикального повторения. 32. Сжатие методом LZW . 33. Кодирование CCITT или кодирование по алгоритму Хаффмана. 34. Сжатие с потерями JPEG. 35. Этапы сжатия JPEG. 36. Фрактальное сжатие. 37. Сжатие MPEG. 38. Внутрикадровое кодирование MPEG. 39. Межкадровое кодирование MPEG. 40. Сравнительный анализ MPEG стандартов. 41. Прикладные программы создания и редактирования растровых изображений. 42. Прикладные программы создания и редактирования векторных изображений. 43. Система автоматизации проектно- чертежных работ AutoCAD. 44. Прикладные программы морфирования изображений.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||