

Некластеризованный индекс, заданный на кластеризованной таблице.
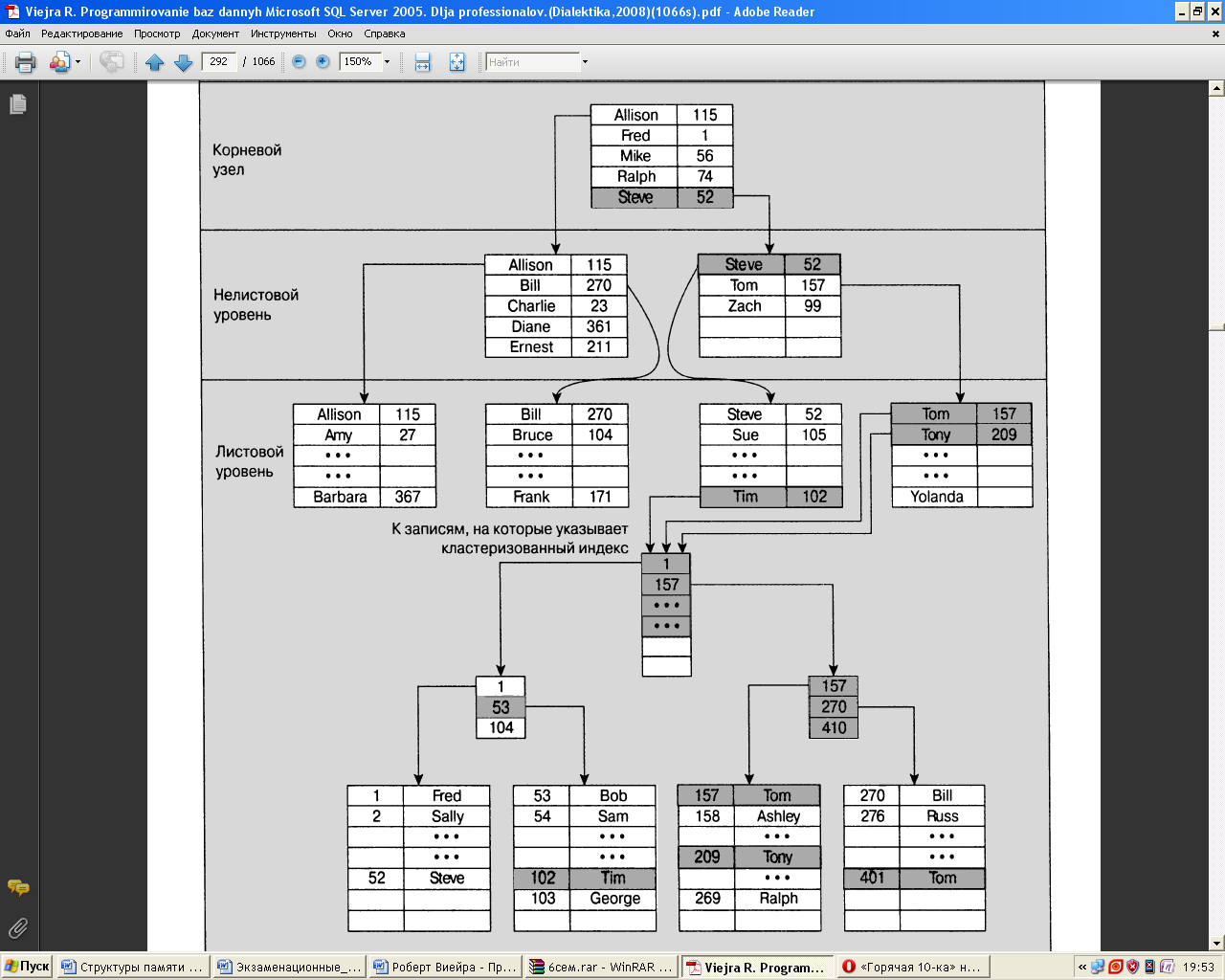
Если применяются некластеризованные индексы, заданные на кластеризованной таблице, то аналогии с кластеризованными индексами продолжаются, но обнаруживаются и свои различия. В некластеризованных индексах заданных на кластеризованной таблице так же как и в некластеризованных индексах, заданных на неупорядоченной таблице, уровни индекса, отличные от листовых во многом напоминают соответствующие уровни кластеризованного индекса. Различия обнаруживаются только после перехода к листовому уровню.
На листовом уровие обнаружuваются еще более резкие различия по сравнению с теми, которые обноружиеалисъ между двумя другими индексными структурами,посколъку в индексе рассматриваемого тиnа для поиска данных применяется еще один индекс прu uсnолъзовании кластеризованных индексов после достижения листового уровня обнаруживаются действительные данные. Еслu применяется некластериеованный индекс, заданный на неупорядоченной таблице, на листовом уровие обнаружuваются не искомые данные, а идентификатор, позволяющий перейти непосредственно к данным (т.е. для достижения данных нужuо сделатъ всего лишь еще один шаг). А что касается некластеризованного индекса, заданного на кластеризованной таблице, то nри его использовании на листовом уровне обuаружuвaemся так называемый кластеризованный ключ. Это позволяет nолучuтъ достаточно информации для того, чтобы nродолжuтъ поиск, восполъзоваешисъ кластеризованным индексом.
Действия, осуществляемые при использовании некластеризованных индексов, заданных на кластеризованной таблице, по казаны на рис. 8.8.
Таким образом, при использовании индекса рассматриваемого типа осуществляются две полностью разные процедуры поиска.
В примере, приведенном на рис.8.8, вначале осуществляется поиск в диапазоне.
Для этого выполняется один просмотр индекса, что позволяет выполнить выборку данных с помощью некластеризованного индекса для обнаружения непрерывного участка данных, соответствующих применяемому критерию (LIKE 'T%’). Просмотр такого рода, который позволяет перейти непосредственно к конкретному участку индекса, называется позиционированием (seek).
После этого начинается операция поиска второго типа - поиск с использованием кластеризованного индекса. Такая вторая операция поиска осуществляется с очень высоким быстродействием; единственная проблема заключается в том, что эта операция должна выполняться многократно. Дело в том, что в СУБД SQL Server после осуществления первой операции поиска с помощью индекса формируется список (в котором находятся все имена, начинающиеся с буквы "т"), но этот список логически не согласуется с кластеризованным ключом в виде каких-либо непрерывных участков, поэтому поиск каждой строки с данными должен выполняться отдельно, как показано на рис. 8.9.
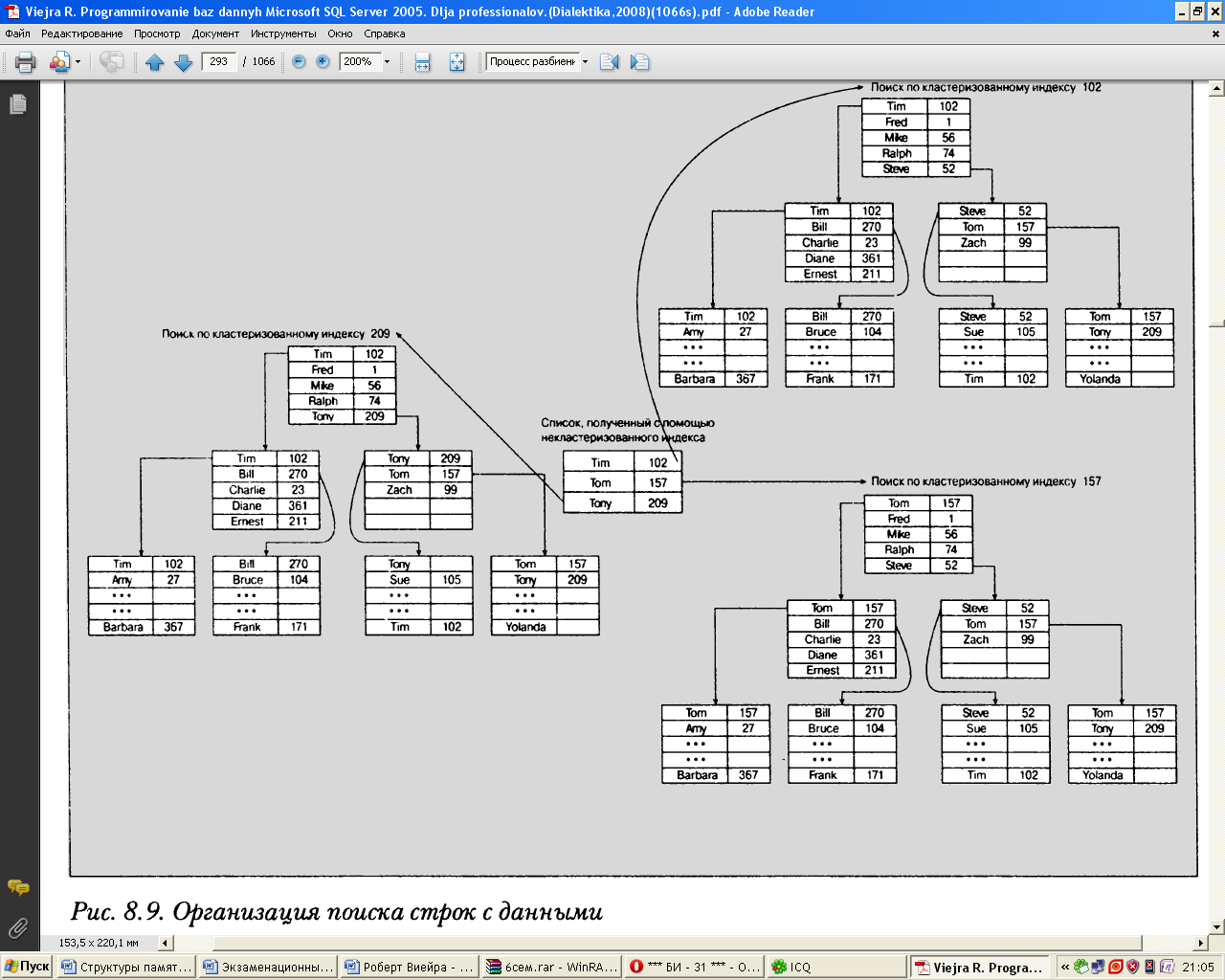
Вполне очевидно, что в связи с необходимостью дважды выполнять поиск издержки становятся больше, чем в той ситуации, когда есть возможность использовать кластер изо ванный индекс с самого начала. А для первой операции поиска с помощью индекса (в которой применяется некластеризованный индекс) обычно требуется осуществить лишь немного логических операций чтения.
Например, если данные хранятся в таблице с длиной строки, равной 1000 байтов, и выполняется операция поиска, аналогичная показанной на рис. 9.8 (скажем, такая операция, которая должна возвратить 5 или 6 строк), ТО должно потребоваться примерно 8-10 логических операций чтения для получения информации из некластеризованного индекса. Но выполнение ЭТИХ операций чтения позволяет лишь подготовиться к чтению строк с помощью кластеризованного индекса. На выполнение каждой такой операции поиска потребуется приблизительно 3-4 логических операций чтения, или 15-24 дополнительных операций чтения. На первый взгляд кажется, что такое увеличение количества операций не имеет особого значения, поэтому рассмотрим эту ситуацию под другим углом зрения.
Количество логических операций чтения увеличивается от минимального значения 3 до максимального значения 24, что соответствует увеличению объема работы, подлежащей выполнению, на 800%.
А теперь предположим, что масштабы обработки данных выросли и диапазон значений, подлежащих выборке с помощью некластеризованного индекса, составляет не такое небольшое значение, как пять или шесть строк, а пять или шесть тысяч строк или пять или шесть сотен тысяч строк; в таком случае влияние указанных факторов на производительность становится просто колоссальным.
Следует учuтыватъ то, что некластериэоеанные индексы nри осуществлениц оnераций чтения характеризуются более низкой эффектuвностю по сравнению с кластеризованнымн индексами (правда, в некоторых случаях некластеризованные индексы могут обеспечивать более высокую проивводительность при выполнении оnераций вставки). Кроме того, каким бы не был индекс, обычно он является основой наиболее быстрых способов поиска (хотя встречаются u исключения).