

5 (26) Условия и ограничения, накладываемые на отношения реляционной моделью данных
Отношение обладает следующими характеристиками:
Отношение имеет имя, которое отличается от имен всех других отношений в реляционной схеме.
Каждая ячейка отношения содержит только одно элементарное (неделимое)значение.
Каждый атрибут должен иметь уникальное имя.
Значения атрибута берутся из одного и того же домена.
Каждый кортеж должен быть уникальным, т.е. дубликатов кортежей быть не может.
Порядок следования атрибутов не имеет значения.
Теоретически порядок следования кортежей в отношении не имеет значения. (Но практически этот порядок может существенно повлиять на эффективность доступа к ним.)
Большая часть свойств реляционных отношений происходит от свойств математических отношений:
При вычислении декартова произведения множеств с простыми однозначными элементами (например, целочисленными значениями) каждый элемент в каждом кортеже имеет единственное значение. Аналогично, каждая ячейка отношения содержит только одно значение. Однако математическое отношение не нуждается в нормализации. Кодд предложил запретить применение повторяющихся групп с целью упрощения реляционной модели данных.
Набор возможных значений для данной позиции отношения определяется множеством, или доменом, на котором определяется эта позиция. В таблице все значения в каждом столбце должны происходить от одного и того же домена, определенного для данного атрибута.
В множестве нет повторяющихся элементов. Аналогично, отношение не может содержать кортежей-дубликатов.
Поскольку отношение является множеством, то порядок элементов не имеет значения. Следовательно, порядок кортежей в отношении несуществен.
Однако в математическом отношении порядок следования элементов в кортеже имеет значение. Например, допустимая упорядоченная пара значений (1, 2) совершенно отлична от упорядоченной пары (2, 1). Это утверждение неверно для отношений в реляционной модели, где специально оговаривается, что порядок атрибутов несуществен. Дело в том, что заголовки столбцов однозначно определяют, к какому именно атрибуту относится данное значение. Следствием этого факта является положение о том, что порядок следования заголовков столбцов в заголовке отношения несуществен. Однако, если структура отношения уже определена, то порядок элементов в кортежах тела отношения должен соответствовать порядку имен атрибутов.
Преимущества реляционной БД(в историческом аспекте)
В реляционной модели все данные логически структурированы внутри отношений (таблиц). Каждое отношение имеет имя и состоит из именованных атрибутов (столбцов) данных. Каждый кортеж (строка) данных содержит по одному значению каждого из атрибутов. Большое преимущество реляционной модели заключается именно в этой простоте логической структуры. Хотя, конечно же, за этой простотой скрывается серьезный теоретический фундамент, которого не было у первого поколения СУБД (т.е. у сетевых и иерархических СУБД).
(15,34,42) Нормальные формы – 1-ая, 2-ая, 3-я (нф)
Нормальная форма (НФ) - определенная формализация данных в таблицах для устранения избыточности данных. (убрал унификацию)
Ненормализованная форма (ННФ) - таблица, содержащая одну или несколько повторяющихся групп данных.
Для чего нужна нормализация:
БД занимает меньше места
Работает быстрее
Просто делать запросы
Меньше вводить данных
Стандарт ISO и правило хорошего тона
Первая нормальная форма (1НФ) - отношение, в котором на пересечении каждой строки и каждого столбца содержится одно и только одно значение. (Т.е. таблица, в которой каждому столбцу соответствуют все разные строки, а строкам столбцы)

Как это делается:
1. Повторяющиеся группы устраняются путем ввода соответствующих данных в пустые столбцы строк с повторяющимися данными, т.е. пустые места заполняются дубликатами неповторяющихся данных (этот способ частно называют "выравниванием" таблицы). Полученная таблица, теперь называемая отношением, содержит элементарные (или единственные) значения на пересечении каждой строки с каждым столбцом и поэтому находится в 1НФ. Однако, полученное отношение имеет определенную избыточность данных, устраняемую в ходе дальнейшей нормализации.
2. Один атрибут или группа атрибутов назначаются ключом ненормализованной таблицы, а затем повторяющиеся группы изымаются и помещаются в отдельные отношения вместе с копиями ключа исходной таблицы, в новых отношениях устанавливаются свои первичные ключи(Т.е. в исходной таблице выбираем какой нибудь ключ, убираем повторение и делаем новую таблицу с первичным ключом из исходной таблицы). При наличии в ненормализованной таблице нескольких повторяющихся групп или повторяющихся групп, содержащихся в других повторяющихся группах, данный прием применяется до тех пор, пока повторяющихся групп совсем не останется. Полученный набор отношений будет находиться в первой нормальной форме только тогда, когда ни в одном из них не будет повторяющихся групп атрибутов. Данный способ находится в 1НФ и обладает меньшей избыточностью данных, чем первый способ.
Вторая нормальная форма (2НФ)
Первичный ключ - столбец в таблице БД с уникальным параметром на каждом поле, выступающий, идентификатором строки.
Вторая нормальная форма (2НФ) - отношение, которое находится в первой нормальной форме и каждый атрибут которого, не входящий в состав первичного ключа, характеризуется полной функциональной зависимостью от этого первичного ключа. Полная функциональная зависимость: если А и B - атрибуты отношения, то атрибут B находится в полной функциональной зависимости от атрибута А, если атрибут B является функционально зависимым от А, но не зависит ни от одного собственного подмножества атрибута А.
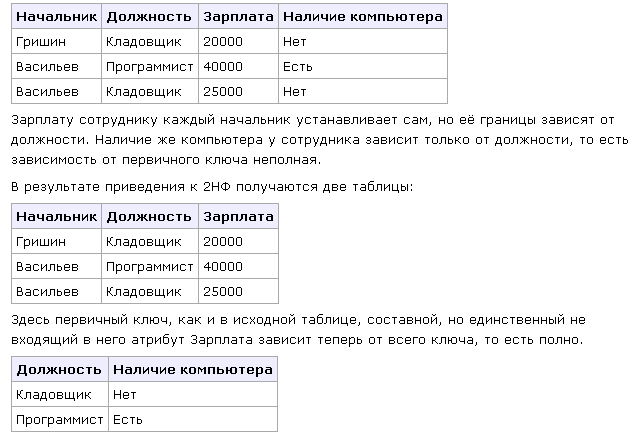
Первичный ключ у нас выходит составной: начальник+должность(во второй таблице Начальник – перв ключ, а в третьей Должность). Но тот факт, есть ПК или нет, не зависит от начальника, правильно? Зачем кладовщику ПК?
Для этого и получают две таблицы.
Третья нормальная форма (ЗНФ) - отношение, которое находится в первой и во второй нормальных формах и не имеет атрибутов, не входящих в первичный ключ атрибутов, которые находились бы в транзитивной функциональной зависит от этого первичного ключа.
 3нф=1нф+2нф+
отсутствие последовательных (транзитивных) зависимостей.
3нф=1нф+2нф+
отсутствие последовательных (транзитивных) зависимостей.
Транзитивная зависимость - когда из 1го следует 2ое, из 2го следует 3е, а 1ое и 3е - в одной таблице. Это неправильно, потому что из этого следует избыточность данных.