

Танненбаум Е. Архітектура компютера [pdf]
.pdf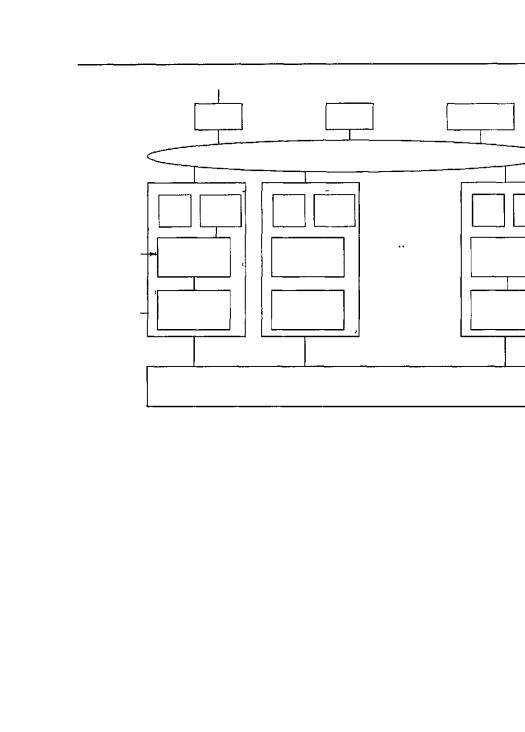

Мультикомпьютеры с передачей сообщений |
62 |
ветственно. Для сравнения: 100 терафлопов (1014 операций с плавающей точко в секунду) — это в 500000 раз больше, чем мощность процессора Pentium Pr работающего с частотой 200 МГц.
В отличие от машины ТЗЕ, которую можно купить в магазине (правда, за бол шие деньги), машины, работающие со скоростью 1014 операций с плавающей то кой, — это уникальные системы, распределяемые в конкурентных торгахДепарт ментомэнергетики,которыйруководитнациональнымилабораториями. Компани Intel выиграла первый контракт; IBM выиграла следующие два. Если вы планир ете вступить в соревнование в будущем, вам понадобится 80 млн долларов. Эт машины предназначены для военных целей. Какой-то сообразительный работни Пентагона придумал патриотические названия для первых трех машин: red, whi и blue (красный, белый и синий — цвета флага США). Первая машина, выполняв шая 1014 операций с плавающей точкой, называлась Option Red (Sandia Nation Laborotary, декабрь 1996), вторая — Option Blue (1999), а третья — Option Whi (2000). Ниже мы будем рассматривать первую из этих машин, Option Red.
Машина Option Red состоит из 4608 узлов, которые организованы в трехмер ную сетку. Процессоры запакованы на платах двух разных типов. Платы kestr используются в качестве вычислительных узлов, а платы eagle используютс для сервисных, дисковых, сетевых узлов и узлов загрузки. Машина содержи 4536 вычислительных узлов, 32 сервисных узла, 32 дисковых узла, 6 сетевых узло и 2 узла загрузки.
Плата kestrel (рис. 8.30, а) содержит 2 логических узла, каждый из которы включает 2 процессора Pentium Pro на 200 МГц и разделенное ОЗУ на 64 Мбай Каждый узел kestrel содержит собственную 64-битную локальную шину и собствен ную микросхему NIC (Network Interface Chip — сетевой адаптер). Две микро схемы NIC связаны вместе, поэтому только одна из них подсоединена к сети, чт делает систему более компактной. Платы eagle также содержат процессор Pentium Pro, но всего два на каждую плату. Кроме того, они отличаются высоко производительностью процесса ввода-вывода.
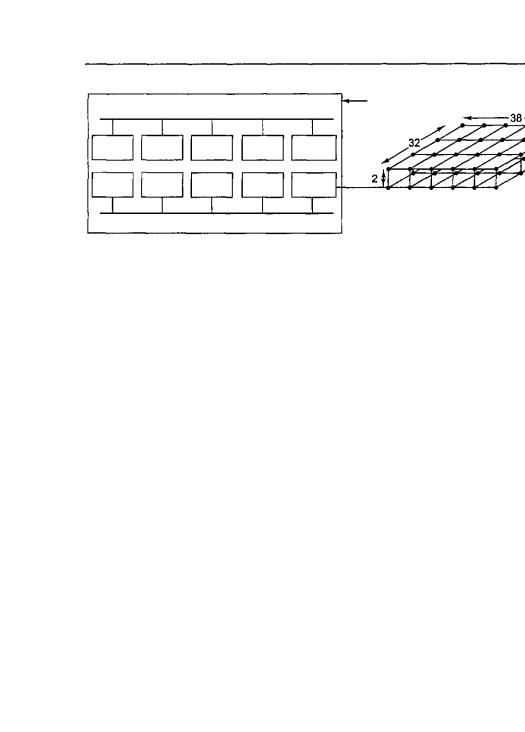
Платы связаны в виде решетки 32x38x2 в виде двух взаимосвязанных плоско стей 32x38 (размер решетки продиктован целями компоновки, поэтому не во все узлах решетки находятся платы). В каждом узле находится маршрутизатор с шес тью каналами связи: вперед, назад, вправо, влево, с другой плоскостью и с плато kerstel или eagle. Каждый канал связи может передавать информацию одновре менно в обоих направлениях со скоростью 400 Мбайт/с. Применяется маршрути зация «червоточина», чтобы сократить время ожидания.
Применяется пространственная маршрутизация, когда пакеты сначала потенци ально перемещаются в другую плоскость, затем вправо-влево, затем вперед-назад наконец, в нужную плоскость, если они еще не оказались в нужной плоскости. Дв

Мультикомпьютеры с передачей сообщений |
|
62 |
Исторически система МРР отличалась высокоскоростной сетью. Но с появл нием коммерческих высокоскоростных сетей это отличие начало сглаживатьс Например, исследовательская группа автора данной книги собрала систему COW которая называется DAS (Distributed ASCII Supercomputer). Она состоит и 128 узлов, каждый из которых содержит процессор Pentium Pro на 200 МГц и ОЗ на 128 Мбайт (см. http://www.cs.vu.nl/~baL/das.htmt). Узлы организованы в 2-ме ный тор. Каналы связи могут передавать информацию со скоростью 160 Мбайт в обоих направлениях одновременно. Эти характеристики практически не отлич ются от характеристик машины Option Red: скорость передачи информации п каналам связи в два раза ниже, но размер ОЗУ каждого узла в два раза больш Единственное существенное различие состоит в том, что бюджет Sandia был зн чительно больше. Технически эти две системы практически не различаются.
Преимущество системы COW над МРР в том, что COW полностью состоит и доступных компонентов, которые можно купить. Эти части выпускаются больш ми партиями. Эти части, кроме того, существуют на рынке с жесткой конкуренц ей, из-за которой производительность растет, а цены падают. Вероятно, систем COW постепенно вытеснят ММР, подобно тому как персональные компьютер вытеснили большие вычислительные машины, которые применяются теперь тольк в специализированных областях.
Существует множество различных видов COW, но доминируют два из них: це трализованные и децентрализованные. Централизованные системы COW пре ставляют собой кластер рабочих станций или персональных компьютеров, смо тированных в большой блок в одной комнате. Иногда они компонуются бол компактно, чем обычно, чтобы сократить физические размеры идлинукабеля. Ка правило, эти машины гомогенны и не имеют никаких периферических устройст кроме сетевых карт и, возможно, дисков. Гордон Белл (Gordon Bell), разработчи PDP-11 и VAX, назвал такие машины «автономными рабочими станциями» (п скольку у них не было владельцев).
Децентрализованная система COW состоит из рабочих станций или персонал ных компьютеров, которые раскиданы по зданию или по территории учреждени Большинство из них простаивают много часов в день, особенно ночью. Обычн они связаны через локальную сеть. Они гетерогенны и имеют полный набор пер ферийных устройств. Самое важное, что многие компьютеры имеют своих вл дельцев.
Планирование
Возникает вопрос: чем отличается децентрализованная система COW от локально сети, соединяющей пользовательские машины? Отличие связано с программны обеспечением и не имеет никакого отношения к аппаратному обеспечению. В л
кальной сети пользователи работают с персональными машинами и использу

Мультикомпьютеры с передачей сообщений |
62 |
Ethernet и gigabit Ethernet. Они работают со скоростью 10,100 и 1000 Мбит/с (1, 12,5 и 125 Мбайт/с)1 соответственно. Все они совместимы относительно сред формата пакетов и протоколов2. Отличие только в производительности.
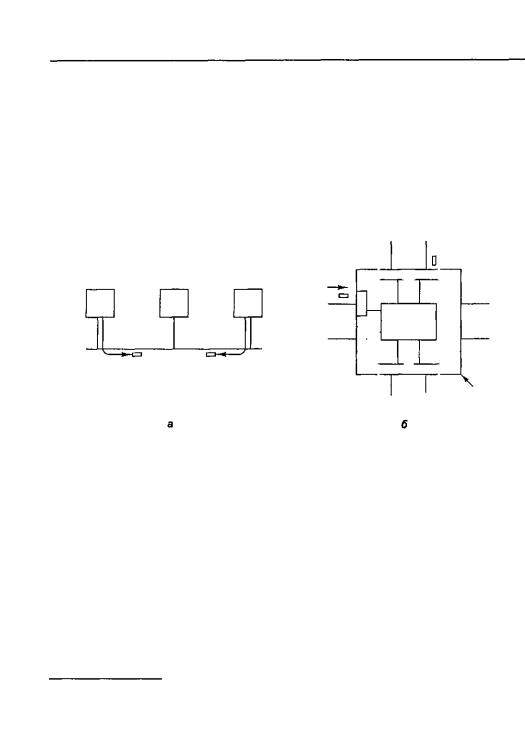
Каждый компьютер в сети Ethernet содержит микросхему Ethernet, обычно съемной плате. Изначально провод из платы вводился в середину толстого медн го кабеля, это называлось «зуб вампира». Позднее появились более тонкие кабе и Т-образные коннекторы. В любом случае платы Ethernet на всех машинах соед нены электрически, как будто они соединены пайкой. Схема подсоединения тр машин к сети Ethernet изображена на рис. 8.32, а.
|
|
|
|
|
|
|
|
\ |
Процессор |
Процессор |
Процессор |
|
|
1 |
1 1 |
1 |
|
|
|
|
|
J |
|
Плата |
- С |
|
|
|
|
|
|
|
i: |
||
|
|
|
|
-| |
backplane |
|
||
Пакет, |
|
Пакет, |
|
|
|
|
|
|
|
|
|
1 |
1 1 |
i |
|||
движущийся |
движущийся |
|
|
|||||
|
|
|
|
|
||||
направо |
налево |
Канальная |
|
|
Коммутатор |
|||
|
|
|
|
карта |
|
Ethernet |
|
|
Рис. 8.32. Три компьютера в сети Ethernet (а); коммутатор Ethernet (б)
В соответствии с протоколом Ethernet, если машине нужно послать пакет, сн чала она должна проверить, не совершает ли передачу в данный момент кака либо другая машина. Если кабель свободен, то машина просто посылает пакет. Ес кабель занят, то машина ждет окончания передачи и только после этого посыла пакет. Если две машины начинают передачу пакета одновременно, происход конфликтная ситуация. Обе машины определяют, что произошла конфликтн ситуация, останавливают передачу, затем останавливаются на произвольный п риод времени и пробуют снова. Если конфликтная ситуация случается во втор раз, они снова останавливаются и снова начинают передачу пакетов, удваивая сре нее время ожидания с каждой последующей конфликтной ситуацией.
Дело в том, что «зубы вампира» легко ломаются, а определить неполадку в к беле очень трудно. По этой причине появилась новая разработка, в которой кабе из каждой машины подсоединяется к сетевому концентратору (хабу). По сущ
1 Соотнесение автором скоростных показателей упоминаемых технологий, выраженных отношени скорости передачи бит/с, с отношениями Мбайт/с неправомочно. Ни одна их этих технологий не зволяет передать по сети соответствующее количество байтов за секунду. Даже теоретически возмо ная скорость для стандарта Ethernet лежит в интервале 800-850 Кбайт/с. Дело в том, что для пере

6 3 0 Глава 8. Архитектуры компьютеров параллельного действия
ству, это то же самое, что и в первой разработке, но производить ремонт зд ще, поскольку кабели можно отсоединять от сетевого концентратора по пока поврежденный кабель не будет изолирован.
Третья разработка — Ethernet с использованием коммутаторов — пок рис. 8.32, б. Здесь сетевой концентратор заменен устройством, содержащи коскоростную плату backplane, к которой можно подсоединять канальны Каждая канальная карта принимает одну или несколько сетей Ethernet, и карты могут воспринимать разные скорости, поэтому classic, fast и gigabit могут быть связаны вместе.
Когда пакет поступает в канальную карту, он временно сохраняется там ре, пока канальная карта не отправит запрос и не получит доступ к плате ba которая функционирует почти как шина. Если пакет был перемещен в ка карту, к которой подсоединена целевая машина, он может направлятьс машине. Если каждая канальная карта содержит только один Etherne Ethernet имеет только одну машину, конфликтных ситуаций больше не нет, хотя пакет может быть потерян из-за переполнения буфера в канально Gigabit Ethernet с использованием коммутаторов с одной машиной на Et высокоскоростной платой backplane имеет потенциальную производительн крайней мере, это касается пропускной способности) в 4 раза меньше, чем связи в машине ТЗЕ, но стоит значительно дешевле.
Но при большом количестве канальных карт обычная плата backplane жет справляться с такой нагрузкой, поэтому необходимо подсоединить не машин к каждой сети Ethernet, вследствие чего опять возникнут конф ситуации. Однако с точки зрения соотношения цены и производительно на основе gigabit Ethernet с использованием коммутаторов — серьезный рент на компьютерном рынке.
Следующая технология связи, которую мы рассмотрим, — это ATM ronousTransferMode—асинхронныйрежимпередачи). ТехнологияAT разработана международным консорциумом телефонных компаний в кач мены существующей телефонной системы на новую, полностью цифров новная идея проекта состояла в том, чтобы каждый телефон и каждый ко в мире связать с помощью безошибочного цифрового битового канала со тью передачи данных 155 Мбит/с (позднее 622 Мбит/с). Но осуществит практике оказалось не так просто. Тем не менее многие компании сейчас в ют съемные платы для персональных компьютеров со скоростью передачи 155 Мбит/с или 622 Мбит/с. Вторая скорость, ОС-12, хорошо подходит д тикомпьютеров.
Провод или стекловолокно, отходящее от платы ATM, переходит в пер тель ATM — устройство, похожее на коммутатор Ethernet. В него тоже по пакеты и сохраняются в буфере в канальных картах, а затем поступают в щую канальную карту для передачи в пункт назначения. Однако у Etherne

Мультикомпьютеры с передачей сообщений |
63 |
ный пункт. Нарис. 8.33. показаныдве виртуальные цепи. В сети Ethernet, напроти нет никаких виртуальных цепей. Поскольку установка виртуальной цепи занимае некоторое количество времени, каждая машина в мультикомпьютере должна уста навливать виртуальную цепь со всеми другими машинами при запуске и использо вать их при работе. Пакеты, отправленные по виртуальной цепи, всегда будут дос тавлены в правильном порядке, но буферы канальных карт могут переполнятьс как и в сети Ethernet с коммутаторами, поэтому доставка не гарантируется.
|
|
Процессор |
|
|
|
|
|
|
|
|
|
|||||||||||
|
|
|
|
|
1 |
2 |
|
|
|
|
|
|
3 |
|
4 |
|
|
|||||
|
|
I |
| | |
| |
Ячейка |
|
L |
|
|
1 |
|
|
||||||||||
|
|
|
|
|
|
|
|
|||||||||||||||
|
|
|
|
|
|
|
|
|||||||||||||||
5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
--. Г |
7 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
] |
|
|
|
|
i |
M |
|
6 |
|
|
|
|
|
|
|
|
|
|
|
|
|
Пакет |
|
|
|
|
|L |
Q |
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
/ I |
|
1 I |
1 |
|
|
г |
|
|
1 |
гг"Л |
|
|
|||||||||
|
|
|
|
|
|
|
|
|||||||||||||||
|
|
|
1 |
1 |
|
1 |
11 1 1 |
1 |
|
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
Порт |
|
|
|
|
|
|
|
Виртуальная цепь |
|
|
•-{ |
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||
|
h |
L |
|
|
i |
I |
J |
|
|
L_ J |
Lj.4J |
i |
|
|||||||||
_9^ |
|
|
|
|
|
|
|
|
|
|
|
С |
|
] --, |
|
! |
11 |
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
10 |
|
|
|
|
|
|
|
|
|
|
|
|
|
i|li |
12 |
|||||||
|
|
|
|
—i |
|
|
|
|
|
|
|
|
|
|
|
|
j |
L |
|
|||
|
|
|
|
I — |
|
|
|
|
Г |
|
|
1 |
|
|
||||||||
|
|
г |
|
|
|
|
|
|
|
^ |
|
r- |
|
|
||||||||
атоpATM |
|
|
|
13 |
14 |
|
|
|
|
|
|
15 |
1f5 |
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
Рис.8.33. 16процессоров,связанныхчетырьмяпереключателямиATM. Пунктиром показаны две виртуальные цепи (канала)
Во-вторых, Ethernet может передавать целые пакеты (до 1500 байтов данных одним блоком. В ATM все пакеты разбиваются на ячейки по 53 байта. Пять и этих байтов — это поля заголовка, которые сообщают, какой виртуальной цеп принадлежит ячейка, что это за ячейка, каков ее приоритет, а также некоторы другие сведения. Полезная нагрузка составляет 48 байтов. Разбиение пакетов н ячейки и их компоновку в конце пути совершает аппаратное обеспечение.
Наш третий пример — сеть Myrinet — съемная плата, которая производитс одной калифорнийской компанией и пользуется популярностью у разработчико систем COW [18]. Здесь используется та же модель, что и в Ethernet и ATM, гд каждая съемная плата подсоединяется к коммутатору, а коммутаторы могут со
единяться в любой топологии. Каналы связи сети Myrinet дуплексные, они пере

6 3 2 Глава 8. Архитектуры компьютеров параллельного действия
Myrinet появилась со своей стандартной операционной системой, многие довательские группы уже разработали свои собственные операционные мы. У них появились дополнительные функции и повысилась производите (см., например, [17,107,155]). Из типичных особенностей можно назвать управление потоком, надежное широковещание и мультивещание, а также в ность запускать часть кода прикладной программы на плате.
Связное программное обеспечение для мультикомпьютеров
Для программирования мультикомпьютера требуется специальное прогр обеспечение (обычно это библиотеки), чтобы обеспечить связь между про и синхронизацию. В этом разделе мы расскажем о таком программном об нии. Отметим, что большинство этих программных пакетов работают в с МРРиCOW.
Всистемах с передачей сообщений два и более процессов работают неза друг от друга. Например, один из процессов может производить какие-ли ные, а другой или несколько других процессов могут потреблять их. Если вителя есть еще данные, нет никакой гарантии, что получатель (получател принять эти данные, поскольку каждый процесс запускает свою программ
Вбольшинстве систем с передачей сообщений имеется два примитив receive, но возможны и другие типы семантики. Ниже даны три основных ва
1.Синхронная передача сообщений.
2.Буферная передача сообщений.
3.Неблокируемая передача сообщений.
Синхронная передача сообщений. Если отправитель выполняет операц а получатель еще не выполнил операцию recei ve, то отправитель блокиру тех пор, пока получатель не выполнит операцию receive, а в это время соо копируется. Когда к отправителю возвращается управление, он уже знает, общение было отправлено и получено. Этот метод имеет простую семанти требует буферизации. Но у него есть большой недостаток: отправитель б ется до тех пор, пока получатель не примет и не подтвердит прием сообще
Буферная передача сообщений. Если сообщение отправляется до то получатель готов его принять, это сообщение временно сохраняется где-л пример в почтовом ящике, и хранится там, пока получатель не возьмет его При таком подходе отправитель может продолжать работу после операц даже если получатель в этот момент занят. Поскольку сообщение уже отпр отправитель может снова использовать буфер сообщений сразу же. Така сокращает время ожидания. Вообще говоря, как только система отправил