

Архитектура и топологии многопроцессорных вычислительных систем / Архитектура и топологии многопроцессорных вычислительных систем www.informika.ru / 7. Надежность и отказоустойчивость МВС
.doc7. Надежность и отказоустойчивость МВС
![]()
Одной
из основных проблем построения
вычислительных систем остаётся задача
обеспечения их продолжительного
функционирования.
Важнейшей
характеристикой вычислительных систем
является надежность.
Повышение надежности основано на
принципе предотвращения неисправностей
путем снижения интенсивности отказов
и сбоев за счет применения электронных
схем и компонентов с высокой и сверхвысокой
степенью интеграции, снижения уровня
помех, облегченных режимов работы схем,
обеспечение тепловых режимов их работы,
а также за счет совершенствования
методов сборки аппаратуры. Понятие
надежности включает не только аппаратные
средства, но и программное обеспечение.
Главной целью повышения надежности
систем является целостность хранимых
в них данных. Единицей измерения
надежности является среднее время
наработки на отказ (MTBF — Mean Time Between
Failure).
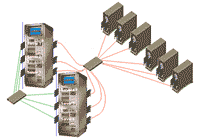 Кластеры
являются идеальной схемой для повышения
надёжности информационно-вычислительной
системы. Благодаря единому представлению,
отдельные узлы или компоненты кластера
могут незаметно для пользователя
подменить неисправные элементы,
обеспечивая непрерывность и безотказную
работу даже таких сложных приложений,
как базы данных.
Основа надёжности
кластера — это некоторое избыточное
количество отказоустойчивых серверов
(узел) от 2 до N в зависимости от конфигурации
кластера и его задач.
Во многих
случаях кластер, как типичный представитель
МВС, представляется пользователю и
администратору как одна единая система.
Наблюдение за системой включает сбор,
хранение и извлечение таких показателей
системы как использование центрального
процессора и памяти, температура системы
и процессора, скорость вращения
вентиляторов; эти и другие параметры
помогают пользователям и администраторам
понимать общее состояние системы и
эффективность её использования.
Системы
хранения должны быть представлены
RAID-системами высокой готовности.
Избыточные соединения должны обеспечивать
доступность данных даже в случае выхода
из строя узлов, контроллеров или кабелей.
Соединение с системами хранения данных
в кластере может быть реализовано как
с использованием SCSI интерфейсов, так и
на основе Fibre Channel технологии.
Программное
обеспечение позволяет организовать
эффективную службу сопровождения и
мониторинга решения, позволяя собирать
метрики на уровне узла, используя плату
управления. Важным направлением является
совершенствование и развитие библиотеки
MPI и развитие системы отладки параллельных
программ, работающих на МВС. К ней
относятся отладчики, профилировщики,
обеспечивающие контроль за прохождением
задач.
Для синхронизации и
совместной работы серверов в качестве
кластера необходимы избыточные соединения
между серверами, называемые «системным
соединением» (private interconnect). Системное
соединение используется для передачи
сигналов о состоянии серверов, а также
используется параллельными базами
данных для передачи данных.
Катастрофоустойчивые
решения создаются на основе разнесения
узлов кластерной системы на сотни
километров и обеспечения механизмов
глобальной синхронизации данных между
такими узлами.
Отказоустойчивость
— это такое свойство вычислительной
системы, которое обеспечивает ей, как
логической машине, возможность продолжения
действий, заданных программой, после
возникновения неисправностей. Введение
отказоустойчивости требует избыточного
аппаратного и программного обеспечения.
Направления, связанные с предотвращением
неисправностей и с отказоустойчивостью,
— основные в проблеме надежности.
Концепции параллельности и отказоустойчивости
вычислительных систем естественным
образом связаны между собой, поскольку
в обоих случаях требуются дополнительные
функциональные компоненты. Поэтому,
собственно, на параллельных вычислительных
системах достигается как наиболее
высокая производительность, так и, во
многих случаях, очень высокая надежность.
Имеющиеся ресурсы избыточности в
параллельных системах могут гибко
использоваться как для повышения
производительности, так и для повышения
надежности. Структура многопроцессорных
и многомашинных систем приспособлена
к автоматической реконфигурации и
обеспечивает возможность продолжения
работы системы после возникновения
неисправностей.
Единое управление
системами кластера позволяет максимально
увеличить период безотказной работы,
контроль и управление приложениями,
операционными системами и аппаратными
средствами. При этом все узлы кластера
управляются из единого центра
контроля.
Программы-утилиты
обеспечивают улучшение защиты и
возможности для восстановления данных,
а также сглаживают последствия сбоев
в работе оборудования для конечного
пользователя. Операционная система
кластера служит для управления всеми
функциями кластера.
Кластерная
конфигурация узлов, коммуникационного
оборудования и памяти может обеспечить
зеркалирование данных, резервирование
компонент самоконтроля и предупреждения,
а также совместное использование
ресурсов для минимизации потерь при
отказе отдельных компонент.
Решение,
обеспечивающее повышенную отказоустойчивость
сервера, должно включать:
Кластеры
являются идеальной схемой для повышения
надёжности информационно-вычислительной
системы. Благодаря единому представлению,
отдельные узлы или компоненты кластера
могут незаметно для пользователя
подменить неисправные элементы,
обеспечивая непрерывность и безотказную
работу даже таких сложных приложений,
как базы данных.
Основа надёжности
кластера — это некоторое избыточное
количество отказоустойчивых серверов
(узел) от 2 до N в зависимости от конфигурации
кластера и его задач.
Во многих
случаях кластер, как типичный представитель
МВС, представляется пользователю и
администратору как одна единая система.
Наблюдение за системой включает сбор,
хранение и извлечение таких показателей
системы как использование центрального
процессора и памяти, температура системы
и процессора, скорость вращения
вентиляторов; эти и другие параметры
помогают пользователям и администраторам
понимать общее состояние системы и
эффективность её использования.
Системы
хранения должны быть представлены
RAID-системами высокой готовности.
Избыточные соединения должны обеспечивать
доступность данных даже в случае выхода
из строя узлов, контроллеров или кабелей.
Соединение с системами хранения данных
в кластере может быть реализовано как
с использованием SCSI интерфейсов, так и
на основе Fibre Channel технологии.
Программное
обеспечение позволяет организовать
эффективную службу сопровождения и
мониторинга решения, позволяя собирать
метрики на уровне узла, используя плату
управления. Важным направлением является
совершенствование и развитие библиотеки
MPI и развитие системы отладки параллельных
программ, работающих на МВС. К ней
относятся отладчики, профилировщики,
обеспечивающие контроль за прохождением
задач.
Для синхронизации и
совместной работы серверов в качестве
кластера необходимы избыточные соединения
между серверами, называемые «системным
соединением» (private interconnect). Системное
соединение используется для передачи
сигналов о состоянии серверов, а также
используется параллельными базами
данных для передачи данных.
Катастрофоустойчивые
решения создаются на основе разнесения
узлов кластерной системы на сотни
километров и обеспечения механизмов
глобальной синхронизации данных между
такими узлами.
Отказоустойчивость
— это такое свойство вычислительной
системы, которое обеспечивает ей, как
логической машине, возможность продолжения
действий, заданных программой, после
возникновения неисправностей. Введение
отказоустойчивости требует избыточного
аппаратного и программного обеспечения.
Направления, связанные с предотвращением
неисправностей и с отказоустойчивостью,
— основные в проблеме надежности.
Концепции параллельности и отказоустойчивости
вычислительных систем естественным
образом связаны между собой, поскольку
в обоих случаях требуются дополнительные
функциональные компоненты. Поэтому,
собственно, на параллельных вычислительных
системах достигается как наиболее
высокая производительность, так и, во
многих случаях, очень высокая надежность.
Имеющиеся ресурсы избыточности в
параллельных системах могут гибко
использоваться как для повышения
производительности, так и для повышения
надежности. Структура многопроцессорных
и многомашинных систем приспособлена
к автоматической реконфигурации и
обеспечивает возможность продолжения
работы системы после возникновения
неисправностей.
Единое управление
системами кластера позволяет максимально
увеличить период безотказной работы,
контроль и управление приложениями,
операционными системами и аппаратными
средствами. При этом все узлы кластера
управляются из единого центра
контроля.
Программы-утилиты
обеспечивают улучшение защиты и
возможности для восстановления данных,
а также сглаживают последствия сбоев
в работе оборудования для конечного
пользователя. Операционная система
кластера служит для управления всеми
функциями кластера.
Кластерная
конфигурация узлов, коммуникационного
оборудования и памяти может обеспечить
зеркалирование данных, резервирование
компонент самоконтроля и предупреждения,
а также совместное использование
ресурсов для минимизации потерь при
отказе отдельных компонент.
Решение,
обеспечивающее повышенную отказоустойчивость
сервера, должно включать:
-
компоненты с «горячей» заменой
-
диски, вентиляторы, внешние накопители, устройства PCI, источники питания;
-
избыточные источники питания и вентиляторы;
-
автоматический перезапуск и восстановление системы;
-
память с коррекцией ошибок;
-
функции проверки состояния системы;
-
превентивное обнаружение и анализ неисправностей;
-
средства удаленного администрирования системы.