

Новосибирский Государственный Технический Университет
Кафедра ВТ
КУРСОВОЙ ПРОЕКТ
По дисциплине «Программирование» на тему:
«Сортировка последовательного текстового файла»
Выполнил:
Студент группы АБ-421
Иванов А.В.
Проверил:
Романов Е.Л.
Новосибирск 2006
Постановка задачи
Сортировка текстового файла простым разделением (по длине строк). Файл читается группами по n строк в массив строк, группа сортируется и записывается в промежуточный файл. Имя промежуточного файла генерируется в виде n.txt, где n – номер группы. Затем файлы сливаются по “олимпийской” системе – по два файла в один.
При сортировке файла в памяти хранится и сортируется только его часть.
Структурное описание разработки. Описание основных алгоритмов.
Структурой, с помощью которой реализована сортировка, является массив строк m размерности N
String[] m=new String[N];
Класс в котором реализован алгоритм str.
Класс состоит из полей:
public String end_file;
Строка в которой хранится имя файла с результатом сортировки
static int n=0;
Статическая переменная используемая для создания имен временных файлов.
String time1,time2,time3;
time1 – время затрачиваемое программой на реализацию алгоритма разбиения исходного файла на части и их сортировки.
time2 – время затрачиваемое программой на реализацию алгоритма слияния полученных отсортированных текстовых файлов по «олимпийской» системе.
time3 – суммарное время, то есть время затраченное программой на сортировку исходного файла.
И одного конструктора копирования, параметрами которого являются:
String filename
Строка, передающая конструктору имя исходного файла.
int N
Количество строк в группе.
Алгоритм разбиения и сортировки
Алгоритмы написаны с помощью стандартных методов классов пакетов java.lang и java.io.
Создаем указатель на поток и указатель на буфер для этого потока.
Считываем в массив строк N строк из исходного файла.
Сортируем массив пузырьковым методом.
Создаем новый указатель на поток для записи данных и буфер для этого потока.
Записываем поочередно строки из массива в новый файл, добавляя символы конца строки и перехода каретки на новую строку (\r\n).
Цикл продолжается до тех пор пока при считывании строк из файла метод readLine() не вернет нам null.
Таким образом мы получили n отсортированных файлов по N строк(за исключением последнего, его длина может быть < N)
Алгоритм слияния файлов по «олимпийской» системе
Открывается i-ый файл для чтения
Открывается i+1-ый файл для чтения
Открывается n+1-ый фаил для зписи
i-ый и i+1-ый файлы сливаются в n+1-ый

Файлы закрываются.
Сливаемые файлы удаляются за ненадобностью.
После слияния n файлов цикл продолжается дальше и происходит слияние файлов, полученных в результате первого слияния и т.д. до тех пор пока все файлы не сольются в один.
Рассмотрим сам алгоритм слияния непосредственно.
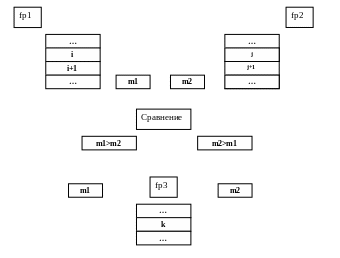
Считываем первые строки из 1го и 2го файлов в строки m1 и m2
Сравниваем их длину (m1.length()<=m2.length()). Метод length() возвращает длину строки
Если m1 больше то записываем ее в выходной файл и считываем следующую строку из первого файла.
Если m2 больше то записываем ее в выходной файл и считываем следующую строку из второго файла.
И так продолжается до тех пор пока указатели на считанные строки не станут равны null.
Алгоритм расчета времени реализации алгоритмов
Для получения необходимых нам параметров воспользуемся методом currentTimeMillis() класса System который возвращает значение типа long в которое является текущим временем. Это время представляется как количество миллисекунд, прошедших с 1-го января 1970 года.
Для получения time1 сохраним время в момент начала алгоритма в переменную типа long t0 и в момент окончания алгоритма разбиения еще раз считаем текущее время в переменную t2. Их разность и даст время которое необходимо нам. Так как в дальнейшем нам необходимо будет вывести значение времени на экран меню(поэтому у нас переменные time1,time2,time3 типа String), мы преобразуем long в String.
time1=String.valueOf(t1);
Для получения time2 считаем время окончания алгоритма и вычтем из него начальное время и полученное нами t1. И также изменим тип наших данных.
Для получения общего времени, то есть time3, просуммируем время разбиения и время слияния.
Таким образом, мы получили время затрачиваемое алгоритмом на разбиение исходного файла, слияние и общее время. Данные параметры понадобятся нам для определения оптимального количества строк в группе.
Класс menu
Этот класс реализует меню для более удобного и наглядного использования алгоритма.
Меню создано с помощью классов пакета java.awt.
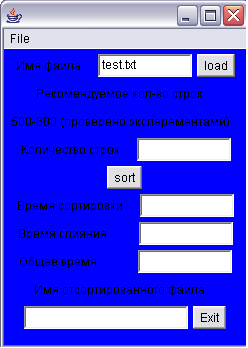
В первом поле вводится имя сортируемого файла, либо с помощью кнопки load находим нужный нам файл в проводнике.
Рекомендуемое количество строк для наиболее быстрой реализации алгоритма оказалось примерно 500-600 строк, более подробно этот пункт будет рассмотрен далее.
В следующем поле вводится количество строк в группе.
По нажатию кнопки sort запускается алгоритм сортировки.
В следующих трех полях выводится время затраченное на разбиение, слияние и общее время.
В последнем поле выводится имя файла с результатом сортировки.
Вывод текстового поля:
TextField Addr = null; //создаем указатель на объект типа TextField
Addr=new TextField(10);//присваиваем указателю новый объект типа TextField
add(Addr);//выводим его на экран
Addr.setText("test.txt");//вводим текст в поле
Addr.getText();//получаем текст из поля
Вывод кнопки:
Button load=new Button("load");
load.addActionListener(this);
add(load);
MenuItem A = new MenuItem("load");
A.addActionListener(this);
file.add(A);
if(e.getActionCommand().compareTo("load")==0)//нажатие кнопки
Вывод текста:
Label name = new Label("Имя фаила");
add(name);
Для связи нашего меню с функцией main() в ней создаем новое меню new MENU();