

ВВЕДЕНИЕ
В данной курсовой работе передо мной стоит задача о создание базы данных, в данную задачу входит: функции информационной системы обеспечивает учет прохождения изделий по технологическому маршруту. Технологический маршрут представляет собой последовательность технологических операций, выполняемых на станках.
1. «Регистрация годных изделий». Данная учетная функция выполняется после каждой технологической операции и должна обеспечивать ввод следующих данных: количество годных; табельный номер работника; табельный номер рабочего; дату регистрации.
2. «Регистрация забракованных изделий». Данная учетная функция выполняется после каждой технологической операции и должна обеспечивать ввод следующих данных: количество забракованных; табельный номер работника; табельный номер рабочего; дату регистрации.
3. «Справка о проценте выхода годных изделий на станках». Данная функция должна обеспечивать вывод таблицы, в которых для каждого станка выводится процент выхода годных изделий.
Данную задачу я «разбил» на цели. Первой целью для меня является создание моделей баз данных, изучение языка SQL и Microsoft Office Access.
Следующая цель полностью посвящена созданию базы данных, интерфейсу и запросам.
1. ОБЩИИ СВЕДЕНЬЯ О РАБОТЕ В ACCESS
1.1 Модели баз данных.
Работающая информационная система (ИС) подразумевает использование модели предметной области. В общем случае понятиями, формирующими модель, являются объекты и отношения между ними. Модель может иметь явное описание, хранимое полностью или частично в ЭВМ, и храниться (также полностью или частично) в ЭВМ сама. Хранимую в ЭВМ и используемую программно модель можно называть базой данных. Альтернативу явному хранимому описанию модели составляет ее неявное и часто некорректное описание "логикой прикладной программы".
Принципиальные трудности описания предметной области, технические трудности реализации баз данных и исторический ход событий привели к тому, что в программировании понятие базы данных (и это видно из самого термина) связано в первую очередь с хранением "данных", доступом к ним. В этом случае для базы данных нет однозначного строгого определения и чаще всего встречается два различных ее понимания. В первом речь идет о хранилище структур данных - чаще всего связанных множеств записей - и о способе для пользователей (программы) работать с записями. Во втором - о хранении собственно модели предметной области, допускающей организацию доступного конечному пользователю (видеале- "предметнику") способа взаимодействия с моделью. Определения, которые принимаются большинством специалистов по разработке информационных систем, могут быть самыми общими, как, например: "Собрание данных, организованных для особо быстрого и удобного способа поиска и извлечения (например, из ЭВМ)", и более специфицированными, как, например: "Собрание структурированных данных в ЭВМ, поддерживаемое СУБД, которая обеспечивает различным приложениям различный вид данных".
Реально при проектировании ИС используется несколько моделей: две "крайних", обобщенная (понятийная) модель и модель, представленная схемой базы данных, могут дополняться рядом промежуточных. Промежуточной может быть, например, модель "сущность-связь" определенного уровня общности. [1,стр.12]
Упоминаемая во втором определении СУБД непосредственно осуществляет функции управления доступом к базе данных, а также целый ряд вспомогательных функций. Таким образом, СУБД отвечает за хранение модели в компьютере и за работу программ и пользователей с моделью.
Если база данных, по крайней мере теоретически, может иметь математическое описание, то СУБД - чисто инженерный продукт. Современная СУБД должна обеспечивать работу приложений и пользователей с информационной моделью: на ЭВМ разной архитектуры с установленными на них различными операционными системами; в компьютерных сетях разных типов, работающих по различным протоколам; с различными графическими и символьными системами представления информации. [4,стр.38]
Вот неполный перечень некоторых функций, которые обеспечивают современные СУБД: поддержка логической модели данных (определение данных, оперирование данными); восстановление данных (транзакции, журнализация, контрольные точки); управление одновременным доступом; безопасность данных (права доступа); самостоятельная оптимизация выполнения операций; другие функции (администрирование, статистика, распределение данных и т.д.). [4,стр.39]
Если можно говорить об основной идее СУБД, то она заключается в передаче управления данными из прикладной программы и/или от пользователя одной специальной системе, которая вне зависимости от того, какая программа или версия программы, или же какой пользователь работает с данными, единым во всех случаях образом отслеживает защиту данных от рассогласованности, оптимизирует выполнение операций над данными, обращения к ним и т.д. (список выгод, которые дает СУБД, имеется в любом учебнике).
1.2 Модели данных
Использование модели данных при работе с БД (в "компьютерном" смысле, в смысле хранения структур данных) неизбежно по нескольким причинам. Во-первых, модель дает общий язык пользователям, работающим с данными. Во-вторых, модель может обеспечить предсказуемость результатов работы с данными. Становится возможным объяснить пользователю, почему он получил конкретный результат при просмотре или изменении данных, и наоборот, работающий с базой может предвидеть, какого сорта он получит результат. За время существования разработок программных систем предложено много различных моделей разной степени распространенности. На некоторых можно остановиться. [2,стр.87]
1.3 Реляционная модель и СУБД
Не будучи хронологически первой, наиболее популярной с начала 80-х гг. была и до сих пор остается реляционная модель данных. Она первая получила математическое описание, и она экономна по части базовых понятий. Первое повлекло возможность тщательного и интенсивного исследования свойств этой модели (немедленно реализованного в обширной литературе), а второе сделало ее привлекательной для программистов и пользователей. [2,стр.90]
В реляционной модели считается, что все данные ИС представлены в виде таблиц. Строки в каждой таблице - это кортеж неструктурированных единиц данных, "атрибутов". Набор кортежей, составляющий таблицу, образует математическое отношение; таким образом, модель данных представляется множеством таблиц-отношений (называемых также R-таблицами); отсюда название "реляционная", т.е. модель, представленная отношениями.
Атрибуты строк-кортежей (и таблиц-отношений) - это значения из заданных наравне с таблицами областей определения ("доменов"). Разные столбцы в одной и той же или в разных таблицах могут иметь одну и ту же область определения, а могут - разные.
Значения атрибутов в таблице-отношении могут иметь только один определенный вид функциональной зависимости друг от друга, а именно, все значения в произвольном кортеже должны по отдельности зависеть только от значений столбца или группы столбцов - одних для всего отношения. Такой столбец или группа столбцов, называются ключевыми, а значения атрибутов в них - ключами.
Реляционная база данных - это набор R-таблиц и только R-таблиц, т.е. считается, что никаким иным образом (переменные, массивы и т.п.) данные в базе не представлены.
В рамках реляционной теории имеется список операций, которые можно осуществлять над R-таблицами, причем так, что результатом снова будет R-таблица (и, таким образом, в результате выполнения операции мы снова получим реляционную базу данных). Обычно это следующие операции:
-базовые операции
-ограничение - исключение из таблицы некоторых строк;
-проекция - исключение из таблицы некоторых столбцов;
-декартово произведение - из двух таблиц получается третья по принципу декартова произведения двух множеств строк;
-объединение - объединение множеств строк двух таблиц;
-разность - разность множеств строк двух таблиц;
-присвоение - именованной таблице присваивается значение выражения над R-таблицами;
-производные операции
-группа операций соединения;
-пересечение - пересечение множеств строк двух таблиц;
-деление - позволяет отвечать на вопросы типа: "какие студенты посещают все курсы ?";
-разбиение - позволяет отвечать на вопросы типа: "какие пять служащих в отделе наиболее оплачиваемы ?";
-расширение - добавление новых столбцов в таблицу;
-суммирование - в новой таблице с меньшим, чем в исходной, числом строк, строки получены как агрегирование (например, суммирование по какому-то столбцу) строк исходной.
Помимо "основных" таблиц, "изначально" присутствующих в БД, приведенные операции позволяют получать выводимые таблицы-"представления", получаемые в результате применения операций.
Если можно говорить об основной идее использования реляционного подхода в СУБД, то это именно предсказуемость результатов работы с данными, обеспечиваемая математическим аппаратом в основе этого подхода. Действительно, поскольку в основе лежит корректная математическая модель, то любой запрос к базе данных, составленный на каком-нибудь "корректном" (формальном) языке повлечет ответ, однозначно определенный схемой данных и конкретными данными. Ничего другого для объяснения пользователю, почему он получил тот, а не иной результат, не требуется (не требуется, например, знать о физическом расположении данных на дисках или же в буферах памяти либо "заглядывать" в одни файлы, чтобы получить описания информации о других). А учитывая, что набор основных понятий достаточно прозрачен, получается, что результат не просто предсказуем, но и относительно просто предсказуем(1). То же можно сказать не только о запросах, но и о манипулировании моделью с помощью перечисленных операций над таблицами. [3,стр.90]
Кроме того, как отмечалось, реляционный подход приносит относительную простоту работы разработчику ИС, поскольку прикладная область часто описывается в терминах таблиц достаточно естественно.
Вскоре после появления идея (и теория) реляционных баз данных стала популярна среди разработчиков СУБД. Однако сделать реляционную СУБД оказалось непросто. Сложилась неоднозначная ситуация, когда после некоторых усовершенствований одни фирмы стали называть свои разработки реляционными (иногда просто добавляя '/R' к имени своей СУБД), а другие - отказываться от создания реляционных СУБД в силу сложности задачи. Для того чтобы внести ясность в оценку разработок одних фирм и более определенно сформулировать цель, к которой разработчикам нужно стремиться, для других (или тех же самых) фирм, Е. Кодд, автор реляционного подхода, в конце 70-х гг. опубликовал свои 12 правил соответствия произвольной СУБД реляционной модели, дополнив основные понятия реляционных баз данных определениями, важными для практики. Ниже приводятся эти правила вместе с дополняющим их подразумеваемым общим положением.
1. Основное (подразумеваемое) правило. Система, которая рекламируется или провозглашается поставщиком как реляционная СУБД, должна управлять базами данных исключительно способами, соответствующими реляционной модели.
2. Информационное правило. Вся информация, хранимая в реляционной базе данных, должна быть явно, на логическом уровне, представлена единственным образом: в виде значений в R-таблицах.
3. Правило гарантированного логического доступа. К каждому имеющемуся в реляционной базе атомарному значению должен быть гарантирован доступ с помощью указания имени R-таблицы, значения первичного ключа и имени столбца.
4. Правило наличия значения (missing information). В полностью реляционной СУБД должны иметься специальные индикаторы (отличные от пустой символьной строки или строки из одних пробелов и отличные от нуля или какого-то другого числового значения) для выражения (на логическом уровне, систематично и независимо от типа данных) того факта, что значение отсутствует по меньшей мере по двум различным причинам: его действительно нет либо оно неприменимо к данной позиции. СУБД должна не только отражать этот факт, но и распространять на такие индикаторы свои функции манипулирования данными не зависимо от типа данных.
5. Правило динамического диалогового реляционного каталога. Описание базы данных выглядит логически как обычные данные, так что авторизованные пользователи и прикладные программы могут употреблять для работы с этим описанием тот же реляционный язык, что и при работе с обычными данными.
6. Правило полноты языка работы с данными. Сколько бы много в СУБД ни поддерживалось языков и режимов работы с данными, должен иметься по крайней мере один язык, выразимый в виде командных строк в некотором удобном синтаксисе, который бы позволял формулировать:
-определение данных,
-определение правил целостности,
-манипулирование данными (в диалоге и из программы),
-определение выводимых таблиц (в том числе возможности их модификации),
-определение правил авторизации,
-границы транзакций.
7. Правило модификации таблиц-представлений. В СУБД должен существовать корректный алгоритм, позволяющий автоматически для каждой таблицы-представления определять во время ее создания, может ли она использоваться для вставки и удаления строк и какие из столбцов допускают модификацию, и заносящий полученную таким образом информацию в системный каталог.
8. Правило множественности операций. Возможность оперирования базовыми или выводимыми таблицами распространяется полностью не только на выдачу информации из БД, но и на вставку, модификацию и удаление данных.
9. Правило физической независимости. Диалоговые операторы и прикладные программы на логическом уровне не должны страдать от каких-либо изменений во внутреннем хранении данных или в методах доступа СУБД.
10. Правило логической независимости. Диалоговые операторы и прикладные программы на логическом уровне не должны страдать от таких изменений в базовых таблицах, которые сохраняют информацию и теоретически допускают неизменность этих операторов и программ.
11. Правило сохранения целостности. Диалоговые операторы и прикладные программы не должны изменяться при изменении правил целостности в БД (задаваемых языком работы с данными и хранимых в системном каталоге).
12. Правило независимости от распределенности. Диалоговые операторы и прикладные программы на логическом уровне не должны страдать от совершаемого физического разнесения данных (если первоначально СУБД работала с нераспределенными данными) или перераспределения (если СУБД действительно распределенная).
13. Правило не нарушения реляционного языка. Если в реляционной СУБД имеется язык низкого уровня (для работы с отдельными строками), он не должен позволять нарушать или "обходить" правила, сформулированные на языке высокого уровня (множественном) и занесенные в системный каталог.
Важность правил Кодда в том, что, будучи сформулированы более 20 лет назад, они никем не оспаривались, не дополнялись и до сих пор являются единственными правилами такого рода. Несмотря на то, что не все они равноценны, а некоторые носят "печать времени" своего появления, эти правила в течение длительного периода задают определенную точку отсчета для одних (разработчики) и критерий соответствия для других (разработчики и пользователи).
1.4 Другие модели
Реляционная модель данных, несмотря на ее достоинства, совсем не идеальна. В ряде случаев она не позволяет ясно (или вовсе) отразить особенности предметной области: всего лишь одной из иллюстраций тому служит отсутствие прямых средств выражения иерархии. Поэтому постоянно ведутся поиски других моделей, которые, впрочем, все также имеют свои сильные и слабые стороны. В соответствии со степенью распространенности других моделей можно коротко упомянуть о двух из них. [3,стр.97]
Моделью данных, привлекающей нарастающее внимание с конца 80-х гг., является объектная, или "объектно-ориентированная" модель . Основными понятиями, с которыми оперирует эта модель, являются следующие: объекты, обладающие внутренней структурой и однозначно идентифицируемые уникальным внутрисистемным ключом; классы, являющиеся по сути типами объектов; операции над объектами одного или разных типов, называемые "методами"; инкапсуляция структурного и функционального описания объектов, позволяющая разделять внутреннее и внешнее описания (в терминологии предшествовавшего объектному модульного программирования - "модульность" объектов); наследуемость внешних свойств объектов на основе соотношения "класс-подкласс".
К достоинствам объектно-ориентированной модели обычно относят:
возможность для пользователя системы определять свои сколь угодно сложные типы данных (используя имеющийся синтаксис и свойства наследуемости и инкапсуляции); наличие наследуемости свойств объектов; повторное использование программного описания типов объектов при обращении к другим типам, на них ссылающимся.
К недостаткам объектно-ориентированной модели можно отнести:
отсутствие строгих определений; разное понимание терминов и различия в терминологии; как следствие - эта модель не исследована столь тщательно математически, как реляционная; отсутствие общеупотребимых стандартов, позволяющих связывать конкретные объектно-ориентированные системы с другими системами работы с данными.
Некоторые специалисты основным и главным отличием объектно-ориентированной модели от реляционной считают наличие уникального системного идентификатора. Эта разница связана с одним интересным семантическим явлением. Дело в том, что в реляционной модели объект целиком описывается его атрибутами. Если человек в таблице представлен именем и номером телефона, то что происходит после замены номера телефона в существующей строке ? Идет ли после этого речь о том же самом человеке или о другом ? В реляционной модели нет средств получить ответ на этот вопрос; в объектно-ориентированной его дает неизменившийся системный идентификатор. С другой стороны, мы можем "заменить" в базе данных одного сотрудника на другого, сохранив все связи и атрибуты прежнего, и при этом системный идентификатор не изменится. Ясно, однако, что подразумеваться будет совсем другой человек.
Еще одной моделью данных, имеющей конкретную реализацию (система InfoModeller), является модель "объектов-ролей", предложенная еще в начале 70-х годов, однако выведенная за рамки академических исследований совсем недавно коллективом фирмы Asymetrix. В отличие от реляционной модели в ней нет атрибутов, а основные понятия - это объекты и роли, описывающие их. Роли могут быть как "изолированные", присущие исключительно какому-нибудь объекту, так и существующие как элемент какого-либо отношения между объектами. Модель, по словам авторов, служит для понятийного моделирования, что отличает ее от реляционной модели. Имеются и другие отличия и интересные особенности: например, для нее помимо графического языка разработано подмножество естественного языка, не допускающее неоднозначностей, и, таким образом, пользователь (заказчик) не только общается с аналитиком на естественном языке, но и видит представленный на том же языке результат его работы по формализации задачи. (Можно заметить, что многие пользователи, в отличие от аналитиков, с трудом разбираются в описывающих их деятельность рисунках и схемах.) Модель "объектов-ролей" сейчас привлекает большое внимание специалистов, однако до промышленных масштабов ее использования, сравнимых с двумя предыдущими, ей пока далеко.
1.5 Взаимосвязь моделей данных
Теоретически упомянутые три модели данных, а также большинство неупомянутых равносильны в том смысле, что все, выразимое в одной из них, выразимо в остальных. Различие, однако, составляет то, насколько удобно использовать ту или иную модель проектировщику-человеку для работы с реальными жизненными задачами, и то, насколько эффективно можно реализовать работу с конкретной моделью на ЭВМ (если это возможно вообще). Как уже говорилось, однозначно общеупотребимой модели сейчас нет (и, по-видимому, не будет никогда) и разные модели сосуществуют. Более того, они существуют взаимосвязано либо же попытки такой взаимоувязки (вплоть до объединения) неустанно предпринимаются.
Много дебатов, к примеру, ведется по вопросу, совместимы ли и если да, то каким образом, реляционная и объектная модели. Существуют мнения, что они взаимоисключают друг друга и что они взаимодополняют друг друга. Последнего придерживается, например, такой авторитет в области теории баз данных, как К.Дейт. Согласно Дейту синергия двух моделей могла бы ("должна" - по утверждению автора) базироваться на формуле "область определения атрибута = класс объектов". Иными словами, атрибутами в реляционных таблицах могут быть объекты произвольно заданной сложности. С точки зрения реляционной модели они остаются атомарными, а все возможности работы с ними, проистекающие из наличия внутренней структуры, реализуются объектно-ориентированными методами. Существует выбор, какие свойства предметной области моделировать реляционными методами (т.е. моделировать таблицами, связанными друг с другом ключами), а какие - объектными, но это уже составляет проблему разработчика базы данных: теория здесь лишь предоставляет возможности такого выбора. Предложение Дейта не противоречит ни реляционному, ни объектному подходу и выглядит теоретически обоснованным. В то же время оно противоречит другому подходу, основывающемуся на формуле "класс объектов = таблица", когда с объектом связывается строка таблицы. Этот подход получил распространение в практике производителей объектно-ориентированных СУБД. [5,стр.127]
Другой аспект взаимной связи указанных двух моделей носит реализационный характер. Некоторые объектно-ориентированные системы сами реализованы на "реляционно-ориентированных" СУБД, как на системах, получивших доминирующее распространение на рынке СУБД, и вследствие этого наиболее продвинутых как промышленные изделия. В таких системах определения, заданные в рамках объектного подхода, переводятся в реляционные определения, или наоборот, объектно-ориентированные определения строятся как надстройки над реляционно-ориентированными системами.
Переход от модели "объекты-роли" к реляционной заложен создателями в основу реализации первой. Модель "объекты-роли" согласно такой позиции рассматривается как понятийная, а реляционная модель - как реализационная. Трансформация определений "объектов-ролей" в реляционные определения не просто возможна, а и изначально предположена в InfoModeller, причем гарантируется высокое качество результата такого преобразования: получаемые таблицы имеют так называемую "5-ую нормальную форму", считающуюся более качественной в реляционном плане, чем обычно требуемая в реляционных СУБД "3-я нормальная форма".
1.6 Язык SQL
Программная реализация моделей данных, т.е. построение СУБД или программных систем, наталкивается на большие сложности. Наиболее отчетливо это видно на примере реляционной модели, для которой ни одной СУБД, если следовать строго определениям, не создано. Вместо этого имеется целое семейство систем, в той или иной степени поддерживающих язык работы с данными SQL. SQL изначально появился как язык для реляционных СУБД, однако по мере своего практического развития он все больше и больше отклонялся от реляционности. Причиной тому являются как принципиальные проблемы реализации, так и организационно-рыночные факторы, не позволяющие разным производителям СУБД договориться о "правильном" стандарте. Реально сейчас известно три основных стандарта :
SQL89,
SQL92,
SQL95 (в процессе разработки).
Каждый имеет свою структуру и несколько уровней (реализации, соответствия). SQL92, например, имеет базовый уровень, промежуточный уровень и "полный стандарт". Все из имеющихся на сегодня развитых "реляционных" СУБД сертифицированы уполномоченными органами максимум на базовый уровень SQL92.
Положительной стороной языка SQL является его стандартизованность: для него разработано последовательно несколько стандартов, и работы в этой области продолжаются. Нужно, однако, отметить, что "чистых" SQL-систем, поддерживающих какой-нибудь из уровней какого-нибудь стандарта SQL и только этот уровень, не существует. На практике все из имеющихся SQL-систем являются диалектами, предлагаемыми отдельными фирмами, что безусловно девальвирует стандарты. В результате вводимых производителями многочисленных "дополнительных возможностей" (часто улучшающих эффективность работы с конкретной системой) перенести готовое приложение с одной СУБД, "удовлетворяющей" по утверждению разработчика "стандарту SQL имярек", на другую СУБД, удовлетворяющую тому же стандарту, если только и возможно, то нередко весьма затруднительно.
1.7 Реализованные SQL-системы
Первой системой, реализовавшей поддержку придуманного для этой же системы и самого первого варианта SQL, была Система R, разработанная в фирме IBM в конце 70-х гг. Система R не была коммерческим продуктом, каковым стало ее развитие - семейство СУБД DB2, существующих сейчас на большинстве машин этой фирмы. Первой же коммерческой SQL-системой стала СУБД Oracle, выпущенная во второй половине 80-х гг. фирмой, носящей теперь то же название. К середине 90-хгг. промышленно поставляемых SQL-систем стало довольно много, но если говорить о наиболее распространенных, то к ним относятся DB2, Oracle, Sybase и Informix. С рыночной точки зрения между этими (и "догоняющими" их) системами существует жесткая конкуренция, что имеет положительные для пользователя стороны: фирмы-разработчики систем постоянно следят за достижениями конкурентов и подхватывают друг у друга новые технологические идеи, не допуская крупных отставаний. С другой стороны, как указывалось, привнесение рыночных факторов в выработку стандартного общеупотребимого SQL сказывается отрицательно как на сроках разработки стандарта, так и на его качестве. [3,стр.37]
Хотя в количественном отношении объектно-ориентированные системы явно и значительно уступают реляционно-ориентированным, все же их разнообразие также велико. Можно указать на такие непохожие друг на друга системы, как Smalltalk, C++, Delphi и даже объектно-ориентированную версию языка Cobol. В отличие от SQL-ориентированных систем промышленные объектно-ориентированные не расчитаны на большую производительность и интенсивную переработку данных; они чаще служат для быстрой разработки небольших приложений или клиентской части больших систем. Другую группу образуют объектно-ориентированные СУБД, предназначенные для того, чтобы дать возможность пользователю создавать в рамках объектного подхода объекты предметной области и работать с ними. К таким СУБД относятся ONTOS, GemStore, UniSQL и др..
Нельзя не заметить схожести объектного подхода с сетевой моделью проектирования баз данных, распространенной в 70-х гг. (модель данных CODASYL [9]) и практически не встречающейся в новых системах сейчас. Многие из идей, тщательно разработанных в свое время в подходе CODASYL, появляются в более поздних системах вторично, как это, например, стало с процедурами баз данных, относительно недавно появившихся в SQL-системах. [3,стр.64]
Система InfoModeller была реализована специально созданной для этой цели фирмой, объединившей авторов этой модели данных. В случае, если модель окажется популярной, у фирмы найдутся последователи.
1.8 Основные сведения о Microsoft Access
Приложение Microsoft Access 97/2000 (далее Access) является мощной и высокопроизводительной 32-разрядной системой управления реляционной базой данных (далее СУБД).
База данных – это совокупность структурированных и взаимосвязанных данных и методов, обеспечивающих добавление выборку и отображение данных.
Реляционная база данных. Практически все СУБД позволяют добавлять новые данные в таблицы. С этой точки зрения СУБД не отличаются от программ электронных таблиц (Excel) ,которые могут эмулировать некоторые функции баз данных. Существует три принципиальных отличия между СУБД и программами электронных таблиц:
1.СУБД разрабатываются с целью обеспечения эффективной обработки больших объёмов информации, намного больших, чем те, с которыми справляются электронные таблицы.
2. СУБД может легко связывать две таблицы так, что для пользователя они будут представляться одной таблицей. Реализовать такую возможность в электронных таблицах практически невозможно.
3.СУБД минимизируют общий объём базы данных. Для этого таблицы, содержащие повторяющиеся данные, разбиваются на несколько связанных таблиц.
Access – мощное приложение Windows. При этом производительность СУБД органично сочетаются со всеми удобствами и преимуществами Windows.
Как реляционная СУБД Access обеспечивает доступ ко всем типам данных и позволяет одновременно использовать несколько таблиц базы данных. Можно использовать таблицы, созданные в среде Paradox или dBase. Работая в среде Microsoft Office , пользователь получает в своё распоряжение полностью совместимые с Access
текстовые документы(Word) , электронные таблицы(Excel) , презентации(PowerPoint).С помощью новых расширений для Internet можно напрямую взаимодействовать с данными из World Wide Web и транслировать представление данных на языке HTML, обеспечивая работу с такими приложениями как Internet Explorer и Netscape Navigator.
Access специально спроектирован для создания многопользовательских приложений , где файлы базы данных являются разделяемыми ресурсами в сети. В Access реализована надёжная система защиты от несанкционированного доступа к файлам.
База данных храниться в одном файле, но профессиональные пользователи предпочитают разделять базу данных на два файла: в одном хранятся объекты данных (таблицы, запросы), в другом объекты приложения (формы, отчёты, макросы, модули).
В последних версиях Access представлен новый формат файла (.MDE) –библиотеки, с помощью которого можно создавать приложения, не включая VBA-код.
Несмотря на то, что Access является мощной и сложной системой, его использование не сложно для непрофессиональных пользователей.
Системные требования:
1. 80486DX33 или мощнее
2. Windows 95/98/2000 или Windows NT (версия не ниже 3.51)
3. Не мене 12 Мб оперативной памяти (для совместной работы с другими приложениями не менее 24 Мб)
4. Около 100 Мб дискового пространства (только для Access и новых баз данных).
Основные функции:
1. Организация данных. Создание таблиц и управление ими.
2. Связывание таблиц и обеспечение доступа к данным.Access позволяет связывать таблицы по совпадающим значениям полей, с целью последующего соединения нескольких таблиц в одну.
3 .Добавление и изменение данных. Эта функция требует разработки и реализации представления данных, отличного от табличного (формы).
4. Представление данных. Access позволяет создавать различные отчёты на основе данных таблиц и других объектов базы данных.
5. Макросы. Использование макросов позволяет автоматизировать повторяющиеся операции. В последних версиях Access макросы используют для совместимости.
6. Модули. Модули представляют собой процедуру или функцию, написанные на Access VBA (диалект Visual Basic Application). Эти процедуры можно использовать для сложных вычислений. Процедуры на Access VBA превышают возможности стандартных макросов.
7. Защита базы данных. Эти средства позволяют организовать работу приложения в многопользовательской среде и предотвратить несанкционированный доступ к базам данных.
8. Средства печати. С помощью этой функции Access позволяет распечатать практически всё, что можно увидеть в базе данных.
Access так же позволяет создавать дистрибутивные диски для распространения готового приложения (с помощью Office Developer Edition Tools). Распространение подразумевает поставку всех необходимых файлов на каком-либо носителе.
Пакет ODE Tools включает мастер установки, автоматизирующий создание средств распространения и программы установки. Он так же позволяет выполнение приложения на компьютерах, на которых не установлен Access.
2. Создание таблиц в режиме конструктора
2.1 Задание
Функции информационной системы обеспечивает учет прохождения изделий по технологическому маршруту. Технологический маршрут представляет собой последовательность технологических операций, выполняемых на станках.
1. «Регистрация годных изделий». Данная учетная функция выполняется после каждой технологической операции и должна обеспечивать ввод следующих данных: количество годных; табельный номер работника; табельный номер рабочего; дату регистрации.
2. «Регистрация забракованных изделий». Данная учетная функция выполняется после каждой технологической операции и должна обеспечивать ввод следующих данных: количество забракованных; табельный номер работника; табельный номер рабочего; дату регистрации.
3. «Справка о проценте выхода годных изделий на станках». Данная функция должна обеспечивать вывод таблицы, в которых для каждого станка выводится процент выхода годных изделий.
Создания базы данных информационной системы обеспечивающий учет прохождения изделий по технологическому маршруту. Данная база данных создается в шесть этапов: создание модели информационной системы, создание таблиц, создание схемы данных, запроса, формы и отчета.
2.2 Создание модели информационной системы
Модель информационной системы, обеспечивающие учет прохождения изделий по технологическому маршруту (рис.1).
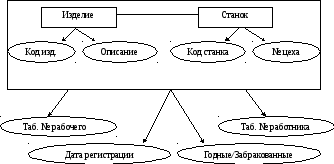 рис.1
рис.1
2.3 Создание таблиц
Создание трех таблиц с помощью функции «создание таблицы в режиме конструктора»:
1. Для создания первой таблицы двойным щелчком выбираем функцию «создание таблицы в режиме конструктора».
 рис.2
рис.2
После чего появляется таблица. В строке «имя поля» вводится, имена полей, в данном случае имена: код (счетчик), годные/забракованные (логический), табельный № работника (числовой), табельный № рабочего (текстовый), дата регистрации (дата/время), код изделия (числовой), описание (текстовый), код станка (числовой), № цеха (числовой). После чего данная таблица закрывается и сохраняется под именем «Изделие-станок», затем заполняется данными (рис.2).
2. Для создания второй таблицы двойным щелчком выбираем функцию «создание таблицы в режиме конструктора». После чего появляется таблица. В строке «имя поля» вводится, имена полей, в данном случае имена: код изделия (текстовый), описание (текстовый). Поле с именем «код изделия» объявляем ключевым полем. После чего данная таблица закрывается и сохраняется под именем «Изделие», затем заполняется данными (рис.3).
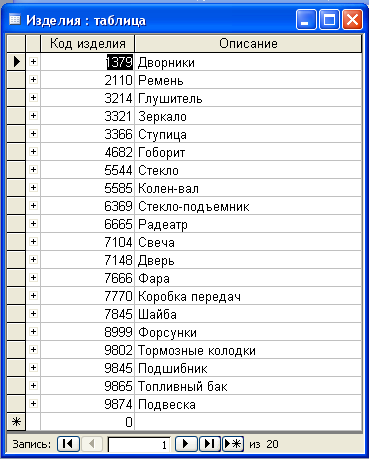 рис.3
рис.3
3. Для создания третей таблицы двойным щелчком выбираем функцию «создание таблицы в режиме конструктора». После чего появляется таблица. В строке «имя поля» вводится, имена полей, в данном случае имена: код станка (числовой), № цеха (числовой)(рис.4).
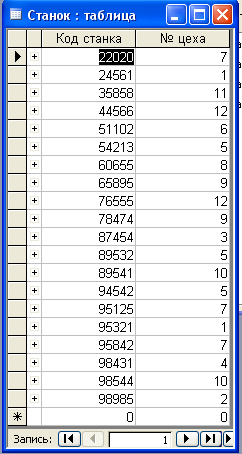 рис.4
рис.4
Поле с именем «код станка» объявляем ключевым полем. После чего данная таблица закрывается и сохраняется под именем «станок», затем заполняется данными (рис.).
2.4 Создание схемы данных
Для создания схемы данных следует щелкнуть мышью на панели управления по иконке «схема данных», после чего «всплывет» окно. В этом окне на вкладке «таблицы» следует выбрать все три таблицы и нажать кнопку добавить(рис.5).
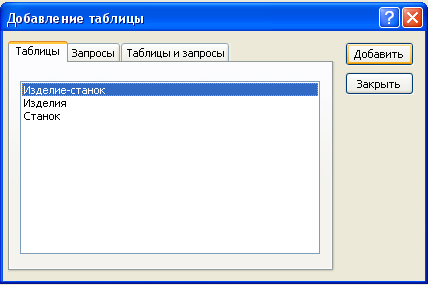 рис.5
рис.5
После чего между добавленными таблицами нужно создать связь: многие ко многим (рис.6).
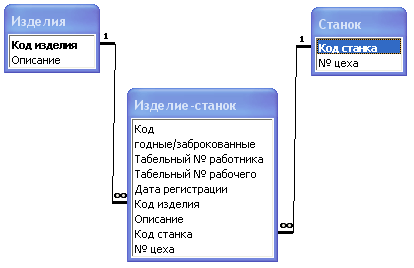 рис.6
рис.6