

Interbase
.pdf

Введение
Базы данных в системах обработки информации
Автоматизация технологических и управленческих процессов, без которой немыслимо эффективное решение задач управления промышленным или торговым предприятием, банком, учебным заведением, государственной структурой, основывается на переработке больших объемов информации.
Эффективность автоматизированных информационных управляющих систем в значительной мере зависит от того, насколько обеспечивается скорость доступа к данным, их полнота, достоверность, непротиворечивость. И практически везде информационная система представляет собой интегрированную систему, ядро которой составляет база данных.
Персональные СУБД (Clipper, FoxPro, Clarion и др.) мало приспособлены для создания интегрированных систем, работающих с общей базой. В принципе эти СУБД вообще не поддерживают в строгом смысле понятие "база данных", работая на уровне индивидуальных таблиц-файлов и не обеспечивая контроля их логической целостности.
Более мощные системы, основанные на СУБД Btrieve, также не отвечают в полной мере требованиям масштабируемости, необходимой для корпоративной информационной системы. Достоинства Btrieve-систем, позволившие им унаследовать архитектуру и большую часть кода от своих предшественников, разработанных на Clipper и Clarion, что во многом объясняет их большую популярность, становятся тормозом при попытке построения информационных систем на более современных платформах и не обеспечивают переносимость решений.
Основным направлением в разработке автоматизированных информационных систем в настоящее время является ориентация на использование СУБД, базирующихся на SQL-серверах. В чем же состоят преимущества разработки информационных систем на их основе?

4 |
Введение |
1.SQL-серверы прямо ориентированы на создание интегрированных, многопользовательских систем, имея в своем распоряжении развитые словари данных.
2.Средства разработки для этих СУБД оптимизированы в отношении коллективной разработки сложных систем в рамках единой стратегической линии.
3.Развитый механизм обработки транзакций позволяет обеспечить целостность данных при одновременной работе многих пользователей.
4.Использование единого языка доступа к данным (SQL) позволяет упростить переход от одной СУБД к другой.
5.Обеспечивается масштабируемость разрабатываемых систем.
6.Поддерживается возможность работы как в локальной, так и в глобальной сетях.
Рассматриваемая здесь СУБД InterBase в полной мере удовлетворяет всем перечисленным требованиям.
InterBase и область его применения
InterBase представляет собой полнофункциональный SQL-сервер. Сервер баз данных - это программный процесс, который выполняется на узле сети, где расположен главный компьютер и физически расположена сама база данных. Процесс сервера - единственный процесс на любом узле, который может исполнять прямые операции ввода-вывода для файлов базы данных.
Клиенты посылают запросы серверному процессу, чтобы выполнить различные действия в базе данных, включая:
•поиск в базе данных по заданным условиям;
•сравнение, сортировку и предоставление данных в табличном виде;
•изменение хранимых данных;
•добавление новых данных в базу;
•удаление данных из базы данных;
•создание новых базы данных и структур данных;
•выполнение программного кода на сервере;
•передачу сообщения другим клиентам, подключенным в данный момент к серверу.


Введение |
7 |
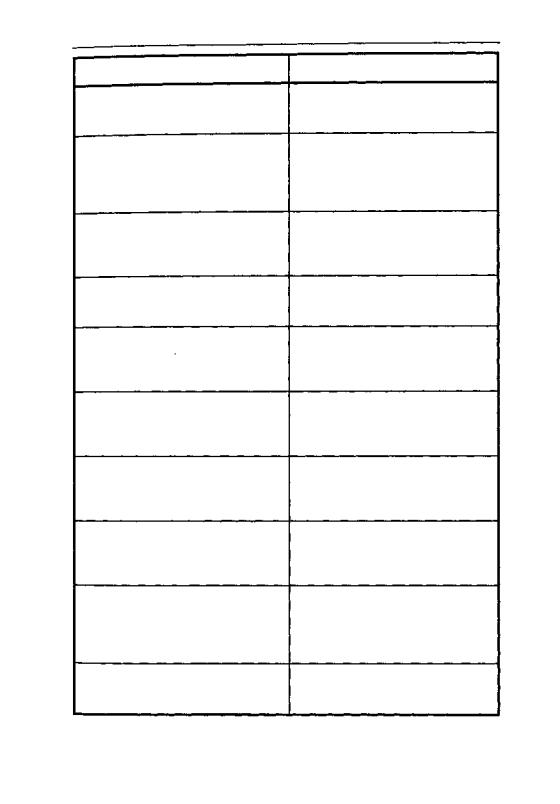
Функция
Доступ к базам данных
Архитектура нескольких поколений
Минимальный (оптимистический) уровень блокировки строк
Оптимизация запросов
BLOB-данные и фильтры BLOB.
Декларативная справочная целостность
Описание
Одно приложение может обращаться к нескольким базам данных одновременно
Сервер поддерживает (при необходимости) старые версии записей так, чтобы транзакции могли видеть непротиворечивое представление данных
Сервер блокирует только те записи, которые клиент модифицирует, вместо блокировки полной страницы базы данных
Сервер оптимизирует запросы автоматически. Можно также определить план запроса вручную
BLOB (большой двоичный объект) - данные, которые могут содержать неструктурированные данные типа графики или текста
Автоматическая поддержка логических связей между таблицами по внешним (FOREIGN) и первичным (PRIMARY) ключам
Хранимые процедуры |
Программы, |
хранимые |
элементы в |
|
базе данных для расширения воз- |
||
|
можностей запросов на поиск и из- |
||
|
менение данных |
|
|
Триггеры |
Программы, |
которые |
запускаются, |
|
когда в связанных с ними таблицах |
||
|
добавляются, модифицируются или |
||
|
удаляются данные |
|
|
Индикация событий |
Выдача сообщений приложению от |
||
|
базы данных. Дает возможность при- |
||
|
ложениям |
получить |
асинхронное |
|
уведомление об изменениях в базе |
||
|
данных |
|
|
Обновляемые обзоры |
Обзоры (виртуальные таблицы) мо- |
||
|
гут отражать изменения данных сра- |
||
|
зу, как только они происходят |
||



Глава 1
Реляционные базы данных
1.1. Организация храненияданных
Для обеспечения эффективного хранения данных, а это означает быстрый поиск, обновление данных, защиту от ошибочных вводов, обеспечение конфиденциальности информации и многое другое, необходима соответствующая их организация. Для быстрого поиска необходимо упорядочение хранимых данных, поддержание связей между ними, контроль на непротиворечивость, обеспечение однократного ввода или изменения при многократном последующем использовании. Ключевую роль при этом играют методы поддержания логических связей между данными. По способам организации хранения связей выделяются такие модели данных, как иерархические, сетевые и реляционные.
Иерархическая модель
Первые иерархические и сетевые СУБД были созданы в начале 60-х годов, что было вызвано необходимостью управления миллионами записей (прежде всего связанных друг с другом иерархическим образом), например при информационной поддержке лунного проекта Аполлон. Среди реализуемых на практике СУБД этого типа наибольшее распространение получила система IMS (Information Management System компании IBM). Достаточно широко используются и другие иерархические системы.
Информация в иерархической модели данных представляется в виде совокупностей ориентированных деревьев. Формально дерево - это граф без циклов, в ориентированном дереве выделяется начальная вершина -