

Кзаменаційний білет №14
14.1 Види, переваги та недоліки numa-систем. Описание архитектуры.
Архитектура с неоднородным доступом к памяти (NUMA - Non-Uniform Memory Access). Система состоит из однородных базовых модулей (плат), состоящих из небольшого числа процессоров и блока памяти. Модули объединены с помощью высокоскоростного коммутатора. Поддерживается единое адресное пространство, аппаратно поддерживается доступ к удаленной памяти, т.е. к памяти других модулей. При этом доступ к локальной памяти в несколько раз быстрее, чем к удаленной.
Каждый модуль довольно часто является SMP-системой, которая дополнена специальной системой доступа к удаленно памяти.
Впервые идею гибридной архитектуры предложил Стив Воллох и воплотил в системах серии Exemplar. Вариант Воллоха - система, состоящая из 8-ми SMP узлов. Фирма HP купила идею и реализовала на суперкомпьютерах серии SPP. Идею подхватил Сеймур Крей (Seymour R.Cray) и добавил новый элемент - когерентный кэш, создав так называемую архитектуру cc-NUMA (Cache Coherent Non-Uniform Memory Access), которая расшифровывается как "неоднородный доступ к памяти с обеспечением когерентности кэшей". Он ее реализовал на системах типа Origin.
Масштабируемость.
Масштабируемость NUMA-систем ограничивается объемом адресного пространства, возможностями аппаратуры поддежки когерентности кэшей и возможностями операционной системы по управлению большим числом процессоров. На настоящий момент, максимальное число процессоров в NUMA-системах составляет 256 (Origin2000), что гораздо больше, чем возможное число процессоров SMP-систем.
Операционная система.
Обычно вся система работает под управлением единой ОС, как в SMP. Но возможны также варианты динамического "подразделения" системы, когда отдельные "разделы" системы работают под управлением разных ОС (например, Windows NT и UNIX в NUMA-Q 2000). Операционная система должна в отличие от SMP учитывать неоднородность адресного пространства для каждого процессора, чтобы избегать частого межмодульного доступа.
Модель программирования.
Полностью аналогично SMP.
Достоинства и недостатки.
NUMA-системы по своим параметрам аналогичны SMP-системам. Ее предназначение - частично устранить главный недостаток SMP - низкую масштабируемость. Это достигается за счет создания виртуальной общей памяти. Масштабируемость вырастает на порядок, но за это приходится платить увеличением стоимости аппаратного и програмного обеспечения.
Аппаратура усложняется за счет появления единой коммуникационной среды, к качеству которой предъявляются высокие требования. Програмное обеспечение усложняется в основном за счет необходимости создания новой ОС, учитывающей особенности архитектуры.
14.2 Узагальнена передача даних від одного процесу всім процесам.
Обобщенная операция передачи данных от одного процесса всем процессам (распределение данных) отличается от широковещательной рассылки тем, что процесс передает процессам различающиеся данные (см. рис. 4.4). Выполнение данной операции может быть обеспечено при помощи функции:
int MPI_Scatter(void *sbuf,int scount,MPI_Datatype stype, void *rbuf,int rcount,MPI_Datatype rtype, int root, MPI_Comm comm),
где
sbuf, scount, stype - параметры передаваемого сообщения (scount
количество элементов, передаваемых на каждый процесс), rbuf, rcount, rtype - параметры сообщения, принимаемого в процессах, root – ранг процесса, выполняющего рассылку данных, comm - коммуникатор, в рамках которого выполняется передача данных.
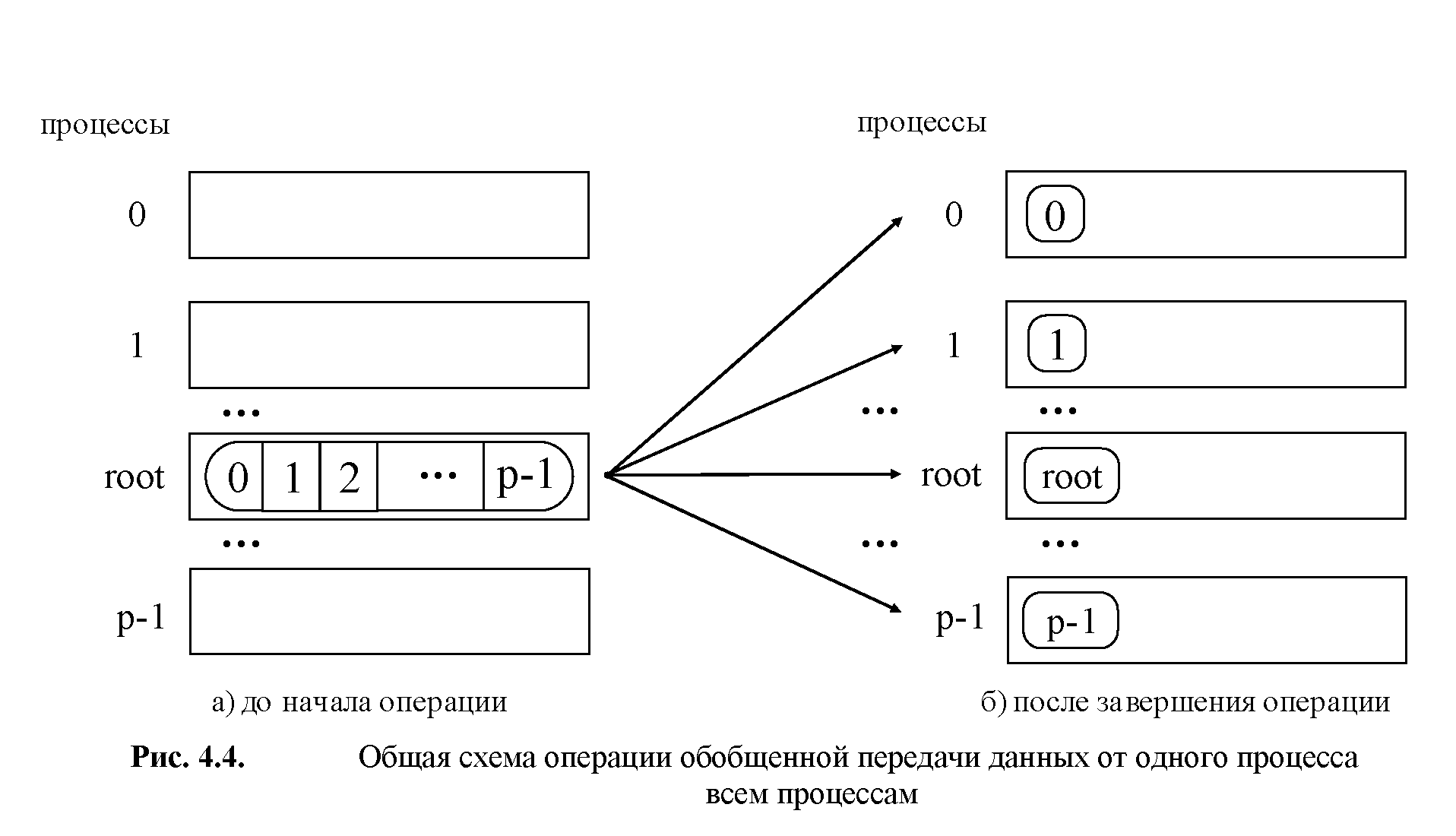
При вызове этой функции процесс с рангом root произведет передачу данных всем другим процессам в коммуникаторе. Каждому процессу будет отправлено scount элементов. Процесс с рангом 0 получит блок данных из sbuf из элементов с индексами от 0 до scount-1, процессу с рангом 1 будет отправлен блок из элементов с индексами от scount до 2* scount-1 и т.д. Тем самым, общий размер отправляемого сообщения должен быть равен scount * p элементов, где p есть количество процессов в коммуникаторе comm.
Следует отметить, поскольку функция MPI_Scatter определяет коллективную операцию, вызов этой функции при выполнении рассылки данных должен быть обеспечен в каждом процессе коммуникатора.
Отметим также, что функция MPI_Scatter передает всем процессам сообщения одинакового размера. Выполнение более общего варианта операции распределения данных, когда размеры сообщений для процессов могут быть разного размера, обеспечивается при помощи функции MPI_Scatterv.
Пример использования функции MPI_Scatter рассматривается в разделе 7 при разработке параллельных программ умножения матрицы на вектор.