

3.4. Теорема кодирования для дискретных источников без памяти (неравномерные коды)
Все
предыдущие рассуждения проводились в
предположении, что кодирование
осуществлялось побуквенно: каждому
элементарному сообщению
![]() которое уместно также именовать буквой,
сопоставлялось кодовое слово
которое уместно также именовать буквой,
сопоставлялось кодовое слово![]() .
В действительности реальный источник
обычно генерирует элементарные сообщения
(буквы) одно за другим последовательно
во времени. Рассмотрим блок из
.
В действительности реальный источник
обычно генерирует элементарные сообщения
(буквы) одно за другим последовательно
во времени. Рассмотрим блок из![]() последовательных букв
последовательных букв![]() ,
где верхний индекс (i), т.е. номер
элемента последовательности, как и
ранее, отвечает дискретному времени.
Указанный блок может трактоваться как
новое, укрупненное сообщение, с тем
чтобы объектом кодирования служили
теперь не буквы, а подобные
,
где верхний индекс (i), т.е. номер
элемента последовательности, как и
ранее, отвечает дискретному времени.
Указанный блок может трактоваться как
новое, укрупненное сообщение, с тем
чтобы объектом кодирования служили
теперь не буквы, а подобные![]() -блоки.
Убедимся, что при таком подходе среднюю
длину неравномерного кода можно сделать
сколь угодно близкой к энтропии источника.
-блоки.
Убедимся, что при таком подходе среднюю
длину неравномерного кода можно сделать
сколь угодно близкой к энтропии источника.
Ограничимся
анализом стационарного ДИБП, генерирующего
буквы из ансамбля
![]() .
Будем кодировать не отдельные буквы
.
Будем кодировать не отдельные буквы![]() а
последовательности букв (блоки) длины
а
последовательности букв (блоки) длины![]() ,
т.е.
,
т.е.![]() ,
где
,
где![]()
![]() Напомним, что для стационарных дискретных
источниковm-мерные вероятности не
зависят от временного сдвига. Кроме
того, ДИБП формирует буквы независимо
друг от друга, т.е. при нахождении энтропии
множества
Напомним, что для стационарных дискретных
источниковm-мерные вероятности не
зависят от временного сдвига. Кроме
того, ДИБП формирует буквы независимо
друг от друга, т.е. при нахождении энтропии
множества![]() -блоков
можно использовать свойство аддитивности.
-блоков
можно использовать свойство аддитивности.
При мощности
![]() множества
множества![]()
![]() мощность множества
мощность множества![]() ,
образованного всеми возможными векторами
,
образованного всеми возможными векторами![]() ,
равна
,
равна![]()
![]() .
Тогда, согласно (2.3), энтропия
.
Тогда, согласно (2.3), энтропия![]() определится как
определится как
![]() .
.
Рассмотрим
последовательность
![]() ,
где
,
где
![]() , (3.4)
, (3.4)
энтропия
на букву блока длины
![]() ,
получившей наименованиеудельной
энтропии. Пусть
,
получившей наименованиеудельной
энтропии. Пусть![]() –
длина слова, кодирующего вектор (
–
длина слова, кодирующего вектор (![]() -блок)
-блок)![]() ,
а
,
а![]() – средняя длина кода при заданной длине
блока букв
– средняя длина кода при заданной длине
блока букв![]() .
Тогда на основании теоремы 3.1.2 существует
префиксный код, для которого
.
Тогда на основании теоремы 3.1.2 существует
префиксный код, для которого
![]()
В силу аддитивности
энтропии для ДИБП
![]() так что
так что![]() .
Тогда число кодовых символов, в среднем
затрачиваемых на одну букву, определяемое
как
.
Тогда число кодовых символов, в среднем
затрачиваемых на одну букву, определяемое
как![]() ,
удовлетворяет соотношению
,
удовлетворяет соотношению
![]() ,
,
и
при
![]()
![]() .
.
Итогом приведенных рассуждений является следующая теорема.
Теорема 3.4.1.Кодируя достаточно длинные последовательности
букв стационарного ДИБП, можно сделать
среднее число кодовых символов на букву
источника![]() сколь угодно близким к значению энтропии
алфавита источника
сколь угодно близким к значению энтропии
алфавита источника![]() .
.
Теоремы 3.1.2 и 3.4.1 проливают новый свет на роль энтропии как характеристики дискретного источника. Ранее эта роль представлялась довольно абстрактной: ее значение выступало как характеристика непредсказуемости источника. Теперь же установлен строгий количественный смысл энтропии как минимально возможного числа двоичных символов, затрачиваемых на кодирование буквы источника. Как было доказано на примере неравномерного кодирования ДИБП, к этой границе всегда можно подойти сколь угодно близко, кодируя достаточно длинные блоки букв источника.
3.5. Кодирование непрерывных источников.
Методы кодирования источника, рассмотренные в 3.2 и 3.3, базируются на точном априорном знании вероятностей всех его сообщений. На практике, однако, нередки ситуации, когда статистика источника заранее неизвестна, и для преодоления априорной неопределенности приходится оценивать вероятности сообщений непосредственно в процессе кодирования. Подобный подход лежит в основе схем словарного кодирования, основой которого является алгоритм Лемпеля-Зива. Более сложная ситуация имеет место в случае рассмотрения непрерывного источника сообщений, ансамбль которого представляет собой континуальное множество. Одним из наиболее распространенных типов подобных источников служит источник речи, в связи с чем ему и будет уделено основное внимание.
Передача речи является основным, обязательным режимом работы систем мобильной связи. Звук с помощью акустоэлектронного преобразователя (микрофона) превращается в аналоговый электрический сигнал. Поскольку в цифровых системах связи (см. рис.1.3) канальному кодированию подвергается последовательность бит, аналоговый речевой сигнал должен быть представлен в цифровой форме. При этом для эффективного использования канала требуется устранить его избыточность до величины, позволяющей на приемной стороне восстановить по нему звук с сохранением индивидуальных особенностей голоса (натуральность).
За длительный период развития телефонной связи были достаточно подробно изучены характеристики речи и устройство речевого аппарата человека. Так, установлено, что для обеспечения приемлемого качества восстановленной речи достаточно анализировать (передавать) речевой сигнал в полосе частот 300…3400 Гц. Выяснены и причины большой избыточности речевого сигнала. К ним относятся:
неравномерное распределение значений (отсчетов) сигнала (редки большие отсчеты);
высокая корреляция соседних отсчетов;
корреляция удаленных отсчетов, обусловленная периодичностью сигнала;
корреляция между периодами основного тона;
избыточность из-за пауз между слогами, словами, фразами при монологе, которые составляют (в среднем) до 25% времени разговора, и пауз, когда надо слушать собеседника (до 50% времени).
Задача устранения этой избыточности возлагается на речевые кодеки– устройства, осуществляющие кодирование речевого сигнала и его декодирование (восстановление). Основная проблема при разработке кодеков состоит в получении высокой степени сжатия без чрезмерного снижения качества восстановленной речи. Таким образом, основными характеристиками кодеков являютсяскорость преобразования
![]() , (3.5)
, (3.5)
где k – число бит на выходе кодера на интервале времениt, икачество восстановленной речи.
Скорость
преобразования
![]() является важной характеристикой речевых
кодеков, так как определяет требуемую
пропускную способность канала для
передачи речи. Сжатие сигнала тем больше
и, следовательно, кодек тем эффективнее,
чем меньше
является важной характеристикой речевых
кодеков, так как определяет требуемую
пропускную способность канала для
передачи речи. Сжатие сигнала тем больше
и, следовательно, кодек тем эффективнее,
чем меньше![]() (при обеспечении требуемого качества
восстановленной речи).
(при обеспечении требуемого качества
восстановленной речи).
Для оценки качества восстановленной речи предложены объективные и субъективные методы и критерии. Поскольку получателем речевого сообщения является человек, важно оценить его субъективное восприятие речи. Стандартами определена средняя экспертная оценка(MOS–mean opinion score), шкала которой имеет 5 градаций: 5 – качество превосходное, 4 – хорошее, 3 – посредственное, 2 – плохое, 1 – неудовлетворительное. Кодеки современных цифровых систем мобильной связи имеют MOS около 4.
Методы сжатия речевых сообщений можно разделить на 2 группы: кодеры формы сигнала и вокодеры. Совместное использование этих методов характерно для так называемыхгибридных кодеров. Вследствие ограниченности времени рассмотрим лишь кодеры формы сигнала.
Кодеры формы позволяют сохранить основную форму непрерывного сигнала. Они не являются специфичными для речи и могут применяться для сжатия любого непрерывного сигнала. Непрерывный сигнал источника кодируется в 2 этапа. Сначала с помощью аналого-цифрового преобразования (АЦП) формируются последовательности, дискретные по уровню и времени, т. е. производится так называемое натуральное кодирование. Затем используются собственно методы сжатия дискретных последовательностей.
На рис. 3.1 показано преобразование непрерывного сигнала в цифровую форму. В литературе эта операция часто именуется импульсно-кодовой модуляцией (ИКМ), хотя в реальности ни о какой модуляции несущей речь не идет.
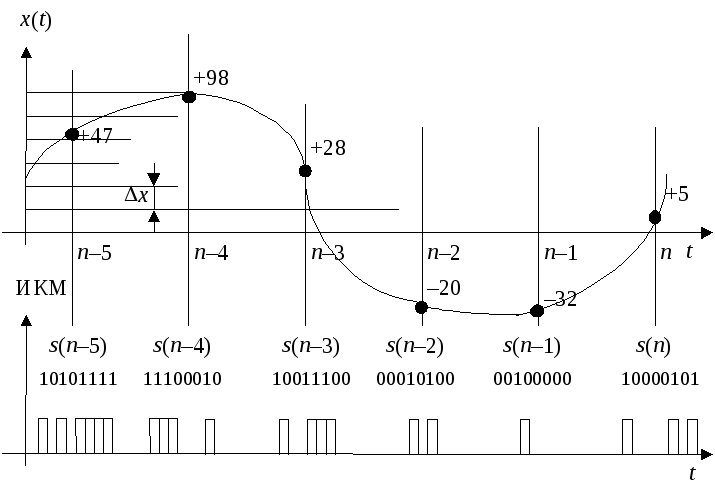
Рис. 3.1. Импульсно–кодовая модуляция
В соответствии с
теоремой Котельникова аналоговый сигнал
![]() заменяется своими непрерывными отсчетами
заменяется своими непрерывными отсчетами![]() ,
взятыми через интервал времени
,
взятыми через интервал времени![]() ,
где
,
где![]() – частота дискретизации, в два раза
превышающая верхнюю частоту
– частота дискретизации, в два раза
превышающая верхнюю частоту![]() спектраx(t). Посколькуtизвестен и на приемной стороне, в
обозначениях его можно опустить.
спектраx(t). Посколькуtизвестен и на приемной стороне, в
обозначениях его можно опустить.
Далее диапазон
изменения
![]() разбивается на
разбивается на![]() дискретных уровней через интервалыx,
называемыешагом квантования. Отсчет
дискретных уровней через интервалыx,
называемыешагом квантования. Отсчет![]() ,
удовлетворяющий условию
,
удовлетворяющий условию![]() ,
где
,
где![]() – целое, принадлежащее отрезку
– целое, принадлежащее отрезку![]() ,
заменяется значением
,
заменяется значением![]() .
При этом возникает погрешность,
максимальное значение которой равноx. Последовательность
таких погрешностей называетсяшумом
квантования.
.
При этом возникает погрешность,
максимальное значение которой равноx. Последовательность
таких погрешностей называетсяшумом
квантования.
Результатом
ИКМ аналогового сигнала x(t)
является последовательность чисел![]() .
Каждое
.
Каждое![]() представляется в двоичной системе
счисления, для чего требуетсяkбит.
На рис. 3.1 около каждого отсчета
представляется в двоичной системе
счисления, для чего требуетсяkбит.
На рис. 3.1 около каждого отсчета![]() указан номер уровня
указан номер уровня![]() в десятичной системе счисления и его
двоичный код на нижнем графике. Первый
бит определяет знак отсчета, остальные
- его значение (младшие разряды справа).
в десятичной системе счисления и его
двоичный код на нижнем графике. Первый
бит определяет знак отсчета, остальные
- его значение (младшие разряды справа).
По каналу за время tпередаютсяk бит со скоростью, определяемой (3.5). На приемной стороне аналоговый сигнал восстанавливается с помощью цифро-аналогового преобразователя (ЦАП) и интерполятора (фильтра нижних частот), например, по формуле
![]() .
.
Из-за
шумов квантования и погрешностей
интерполяции
![]() .
.
Для
речевых сигналов числа
![]() являются зависимыми случайными
величинами. Для сжатия таких
последовательностей широко используетсякодирование с предсказанием. На
рис. 3.2 показана обобщенная схема такого
кодирования.
являются зависимыми случайными
величинами. Для сжатия таких
последовательностей широко используетсякодирование с предсказанием. На
рис. 3.2 показана обобщенная схема такого
кодирования.
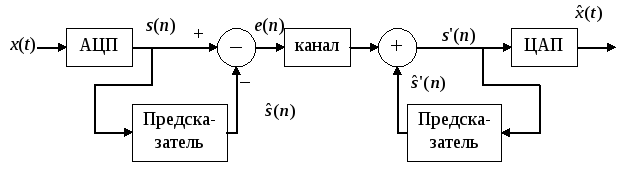
Рис. 3.2. Кодирование с предсказанием
Если известен
(даже не очень точно) вид зависимости
отсчетов друг от друга, то оценку текущего
отсчета
![]() можно вычислить (предсказать) поmпредыдущим отсчетам
можно вычислить (предсказать) поmпредыдущим отсчетам![]() .
При этом в канал разумно посылать только
ошибку предсказания
.
При этом в канал разумно посылать только
ошибку предсказания![]() .
На приемной стороне с помощью такого
же предсказателя вычисляется прогноз
.
На приемной стороне с помощью такого
же предсказателя вычисляется прогноз![]() и восстанавливается сначала текущий
цифровой отсчет
и восстанавливается сначала текущий
цифровой отсчет![]() ,
а затем (с помощью ЦАП) и аналоговый
,
а затем (с помощью ЦАП) и аналоговый![]() .
Сжатие данных здесь достигается за счет
того, что диапазон измененияe(n)
существенно меньше, чем диапазон
измененияs(n). Поэтому при той
же точности представления требуется
меньшее, чем при ИКМ, число двоичных
разрядов. Основной проблемой является
разработка достаточно просто реализуемых
предсказателей, обеспечивающих
минимальную среднеквадратическую
ошибкуe(n).
.
Сжатие данных здесь достигается за счет
того, что диапазон измененияe(n)
существенно меньше, чем диапазон
измененияs(n). Поэтому при той
же точности представления требуется
меньшее, чем при ИКМ, число двоичных
разрядов. Основной проблемой является
разработка достаточно просто реализуемых
предсказателей, обеспечивающих
минимальную среднеквадратическую
ошибкуe(n).
На практике используется линейное предсказание, при котором
![]() , (3.6)
, (3.6)
где
![]() – коэффициенты предсказания;m–
порядок предсказания, обычно равный 8
– 10. Такое экономное кодирование
называетсядифференциальнойИКМ
(ДИКМ).
– коэффициенты предсказания;m–
порядок предсказания, обычно равный 8
– 10. Такое экономное кодирование
называетсядифференциальнойИКМ
(ДИКМ).
Поскольку
зависимость между отсчетами
![]() на отдельных временных интервалах может
изменяться, для уменьшенияe(n)
необходимо подстраивать коэффициенты
предсказания
на отдельных временных интервалах может
изменяться, для уменьшенияe(n)
необходимо подстраивать коэффициенты
предсказания![]() .
Эти изменения должны передаваться на
приемную сторону. В этом случае
дифференциальную ИКМ называютадаптивной(АДИКМ).
.
Эти изменения должны передаваться на
приемную сторону. В этом случае
дифференциальную ИКМ называютадаптивной(АДИКМ).
Другой,
полярный по отношению к ИКМ, метод
кодирования называется дельта –
модуляцией (ДМ). Частота дискретизации![]() выбирается в десятки раз больше верхней
частоты
выбирается в десятки раз больше верхней
частоты![]() спектраx(t). Ошибка предсказанияe(n) представляется 1 битом,
указывающим только знак ошибки –
спектраx(t). Ошибка предсказанияe(n) представляется 1 битом,
указывающим только знак ошибки –![]() больше или меньше
больше или меньше![]() .
Предсказанное значение получается из
предыдущего добавлением или вычитанием
фиксированного значения(отсюда и название метода кодирования).
В зависимости от скорости измененияx(t) величинуможно оперативно изменять, что
соответствуетадаптивнойДМ (АДМ).
Говорят, что если при ИКМ сигналx(t)
квантуется грубо по времени и точно по
уровню, то при ДМ – точно по времени и
грубо по уровню.
.
Предсказанное значение получается из
предыдущего добавлением или вычитанием
фиксированного значения(отсюда и название метода кодирования).
В зависимости от скорости измененияx(t) величинуможно оперативно изменять, что
соответствуетадаптивнойДМ (АДМ).
Говорят, что если при ИКМ сигналx(t)
квантуется грубо по времени и точно по
уровню, то при ДМ – точно по времени и
грубо по уровню.
Экспериментально
установлено, что качество речи,
восстановленной после ИКМ, остается
высоким, если частота дискретизации
![]() ,
а каждый отсчет
,
а каждый отсчет![]() представлен
представлен![]() битами. ИКМ с такими параметрами лежит
в основе так называемойпервичнойИКМ и формирует согласно (3.3) поток бит
со скоростью
битами. ИКМ с такими параметрами лежит
в основе так называемойпервичнойИКМ и формирует согласно (3.3) поток бит
со скоростью![]() кбит/с. Однако корреляция соседних
отсчетов при этом превышает 0,85, что
говорит о высокой избыточности полученной
последовательности. Использование
ДИКМ, АДИКМ позволяет снизить скорость
преобразования примерно в 2 раза с
сохранением высокого качества
восстановленной речи.
кбит/с. Однако корреляция соседних
отсчетов при этом превышает 0,85, что
говорит о высокой избыточности полученной
последовательности. Использование
ДИКМ, АДИКМ позволяет снизить скорость
преобразования примерно в 2 раза с
сохранением высокого качества
восстановленной речи.