

5.3 Кластеризация с известным числом классов
В этом разделе мы предполагаем, что число классов в изображении или по крайней мере приблизительная идея относительно номера и расположения кластеров известно. Будет приведено несколько алгоритмов.
5.3.1 Минимизация суммы квадратов расстояний
Этот алгоритм основан на минимизации суммы квадратов расстояний от всех точек кластера до центра кластера, то есть
![]() (5.34)
(5.34)
где Sj(k) есть кластер с центром zj на k-той итерации. Процедура кластеризации для этого алгоритма приведена на рисунке 5.3. Для ясности мы рассматриваем 20 двумерных образцов.
1. Произвольно выбираем 2 образца в качестве центров кластеров.
![]() (5.35)
(5.35)
Номер в кавычках индексирует порядок итерации.
2. Распределяем образцы x среди выбранных кластеров в соответствии с правилом:
![]() (5.36)
(5.36)
![]() (5.37)
(5.37)
где K = 2 в данном случае. Таким образом,

3. Скорректировать центры кластеров в соответствии с уравнением 5.38
![]() (5.38)
(5.38)

и
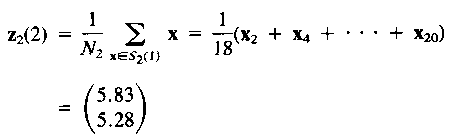
Заметим, что эти откорректированные центры кластера, которые являются средним всех выборок модели в их соответствующих доменах кластера, минимизирует сумму возведенных в квадрат расстояний от всех точек в Sj (k) к новым центрам кластера. В этом случае j = 2, k = 2. N1 и N2 - соответственно число выборок в S1 (k) и S2 (k).
4. Поскольку zj(2) != zj(1), j = 1, 2, алгоритм не завершился. Мы возвращаемся на шаг 2 и повторяем процесс. Иначе процедура завершается.
2. Для новых центров кластеров
![]()
и
![]()
Кластерные домены S1(2) и S2(k) соответственно
![]()
3. Скорректируем центры кластеров:
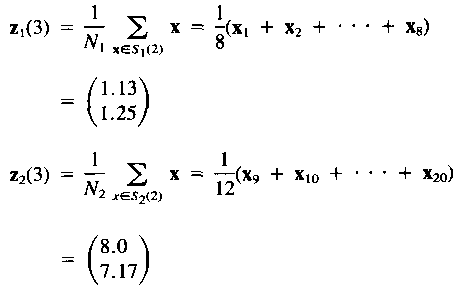
4. Возвращаемся на шаг 2 поскольку
![]()
2. Получаем те же результаты, что и на предыдущей итерации:
![]()
3. Результаты те же.
4. Поскольку zj(4) = zj(3), j = 1, 2, алгоритм сошёлся. Полученные центры кластеров следующие
![]()
Из процедуры, перечисленной выше, нетрудно увидеть, что центры кластера модифицируются последовательно. Вот почему термин "K-средние" иногда используется для этого алгоритма. Также нетрудно увидеть, что эффективность этого алгоритма зависит от числа центров кластера, первоначально выбранных и также порядка, в котором выборки модели пропускаются в системе. На это также повлияют геометрические свойства данных, которые будут проанализированы.

Рисунок 5.3.
5.3.2 Алгоритм isodata
ISODATA - акроним для Итерационных Самоорганизующихся Методов Анализа данных (добавляемый, чтобы делать слово удобопроизносимым). Для этого алгоритма несколько параметров процесса должны быть определены:
M = желаемое число кластеров
= минимальное число выборок в кластере
S = максимальное отклонение
= максимальное расстояние между кластерами
L = максимальное число пар центров кластеров, которые могут быть сосредоточены
I = Число допустимых итераций
Процедура этого алгоритма может быть обобщена следующим образом:
1. Выбрать некоторые начальные центры кластера.
2. Назначить модели самым близким центрам кластера.
3. Повторно вычислить центры кластера (берите среднее выборок в их доменах как новые центры кластера).
4. Проверить что каждый кластер не имеет достаточно членов. Если так, то выбросить кластер.
5. Вычислить среднеквадратичное отклонение для каждого домена кластера, и проверить является ли оно большим чем максимально позволенное значение. И если также среднее расстояние выборок в домене кластера Sj от их центра кластера большее чем полное среднее расстояние выборок от их соответствующих центров кластеров, то разбейте этот кластер на два.
6. Вычислить попарно расстояния среди всех центров кластера. Если некоторые из них меньше чем минимальное позволенное расстояние, объединить пары кластеров в один согласно некоторому предложенному правилу.
Вся процедура может быть изображена блок-схемой как показано на рисунке 5.4. Объяснения терминов использованных на рисунке следующее:
x = выборки
Si = домен кластера
zj = центр кластера
Ni = число выборок в Si
Nc = произвольно выбранное начальное число кластеров
N = общее число выборок
Di = среднее расстояние от выборок в Si до zj
D = общее среднее расстояние от выборок до соответствующих центров кластеров
zil, zjl = центры кластеров для группировки
Nil, Njl = число выборок в кластерах zil, zjl
Пример. Применить алгоритм ISODATA для задачи 20 двумерных выборок из раздела 5.3.1.

Зададим следующие значения параметрам:

В этом случае N = 20 и n = 2. Для начала пусть Nc = 1, с единственным центром кластера в z1(0,0)T.

Рисунок 5.4 Блок-схема алгоритма ISODATА.
Заметим, что эти исходы сверяются с полученными в методе минимизации суммы квадратов расстояний, обсуждённом в разделе 5.3.1. Но если S мало и М велико, скажем 3, то z2 может быть далее разбито на два кластера.