

Дендрограмма иерархической группировки
Для любой иерархической классификации существует соответствующее дерево, называемое дендрограммой, которое показывает, как формируются выборки. Дендрограмма обычно изображается в масштабе, чтобы показать расстояние между объединяемыми на каждом шаге группами. Значения расстояния можно использовать для определения типа того, было ли объединение естественным или вынужденным.
Процедуры иерархической группировки можно разделить на два различных класса агломеративный и дивизимный (делимый). Агломеративные процедуры (снизу-вверх, объединяющие) начинают с c одиночных групп и образуют последовательность постепенно объединяемых групп. Дивизимные (сверху-вниз, разделяющие) процедуры начинают с одной группы, содержащей все выборки и образуют последовательность постепенно объединяемых групп. Вычисления, необходимые для перехода с одного уровня на другой, обычно проще для агломеративных процедур. Однако, когда имеется много выборок, а нас интересует только небольшое число групп, такое вычисление должно повториться много раз, в этом случае более оправданным может оказаться применение дивизимных алгоритмов.
Алгоритм иерархической группировки. Формальное описание
c - желаемое число кластеров
n - количество элементов выборки
![]() ,...,
,...,![]() - исходная выборка
- исходная выборка
![]() -
разбиение на i-м
шаге
-
разбиение на i-м
шаге
-
 ;
k:=0
;
k:=0 -
Имеем
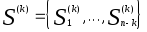
Вычислим матрицу взаимных расстояний (k) между классами и найдем пару классов
![]() т.ч.:
т.ч.:
![]()
3)
Пусть
![]() тогда положим
тогда положим
![]()
![]()
![]()
-
k:=k+1
-
Если k<n-c, то переход на п.2, иначе - конец иерархической группировки.
Метод K-внутригрупповых средних - Краткий обзор
Общая логика
Этот метод кластеризации весьма сильно отличается от алгоритмов иерхической группировки и двунаправленного объединения. Предположим, что у вас уже есть гипотеза относительно числа кластеров в ваших значениях или переменных. Можно просто потребовать, чтобы компьютер формировал точно 3 кластера, которые должны быть различны насколько возможно. Вопрос именно такого типа может разрешить алгоритм k-внутригрупповых средних. Вообще, данный метод формирует ровно k различных кластеров, наиболее “удаленных” друг от друга.
Пример.
В примере с анализом параметров физического состояния, медицинский исследователь может интуитивно предполагать из клинического опыта, что пациенты в целом подразделяются на три основных группы в зависимости от физического состояния. Он мог бы задаться вопросом, может ли это интуитивное предположение быть подтверждено количественно, то есть произвел бы ли алгоритм действительно три кластера пациентов как ожидается. Если так, то исследователь прав и пациенты из кластера 1 действительно будут иметь высокие значения 1-ого признака, и низкие на остальных, и т.д.
Вычисления.
С вычислительной точки зрения, этот метод похож на анализ вариации "наоборот". Программа начинает работу с k произвольными кластерами, и затем перемещает объекты между этими кластерами с целью (1) минимизации разброса внутри кластера, и (2) максимизации разброса между кластерами. Данные разброса являются стандартным выходом алгоритма.
Интерпретация результатов.
Обычно, как результат анализа k-групповых средних, мы будем проверять значения каждого кластера по каждому измерению, чтобы оценить, насколько различны полученные k кластеров. .В идеальном случае мы получим очень различные значения для большинства, если не всех измерений, используемых в анализе. Величина отклонений, полученных по каждому измерению с помощью анализа вариации, является хорошим индикатором того, как хорошо соответствующая компоненты разделены при разбиении на кластеры.
Алгоритм К-средних. Формальное описание.
C - число кластеров
-
Выберем случайным образом некоторое начальное разбиение
![]() где
где
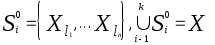
![]() при
i
j
при
i
j
2)
Построено k
-е разбиение
![]()
Вычислим
набор средних
![]() ,
где
,
где
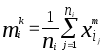
3)
Построим максимальное дистанционное
разбиение, порождаемое набором
![]() и возьмем его в качестве
и возьмем его в качестве
![]() .
Это делается из следующих соображений:
.
Это делается из следующих соображений:
![]()
. . . . . . . . . . . . . . . . . . . . . . . . .
![]()
. . . . . . . . . . . . . . . . . . .
для
1![]() l
l![]() c
c
4)
Если
![]() ,
то переход на п.2 и m:=m+1,
иначе - конец алгоритма.
,
то переход на п.2 и m:=m+1,
иначе - конец алгоритма.
Двунаправленное объединение - Краткий обзор.
В предыдущем разделе, мы обсудили этот метод в терминах "объектов", которые нужно кластеризовать (см. Иерархическая группировка (Объединение)). Во всех других типах анализа в пакете STATISTICA цель исследования, обычно выражается в терминах или значений (наблюдений) или переменных. Оказывается, что кластеризация по обоим этим признакам может давать хорошие результаты. Например, рассмотрим работу медицинского исследователя, который собрал данные относительно различных параметров физического состояния (переменным) для различных болезней сердца (значений). Исследователь может кластеризовать значения (пациентов), чтобы обнаружить кластеры пациентов со схожими симптомами. В то же время, исследователю может потребоваться кластеризовать переменные (параметры физического состояния) чтобы выделить кластеры параметров, которые, выявляют одни и те же отклонения в состоянии. В модуле кластерного анализа, мы можете выбирать кластеризацию как значений так и переменных.