

Распознавание образов / Lection_RECOGNITION / lecture8 / NeuroSlides
.docЗадачи решаемые НС
-
Классификация образов.
-
Кластеризация / категоризация.
-
Аппроксимация функций.
-
Предсказание/прогноз.
-
Оптимизация.
-
Ассоциативная память.
-
Управление.
Классификация по архитектуре связей
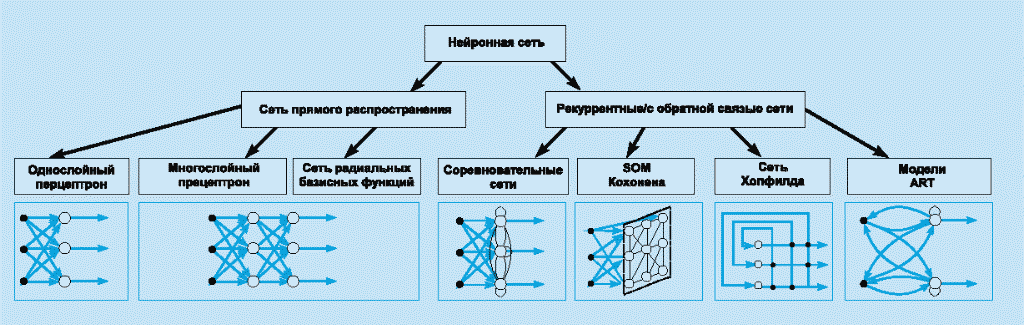
Свойства искусственных нейронных сетей
-
Обучение
-
Обобщение
-
Абстрагирование
-
Применимость
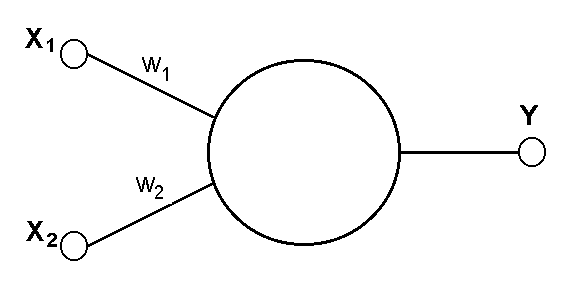
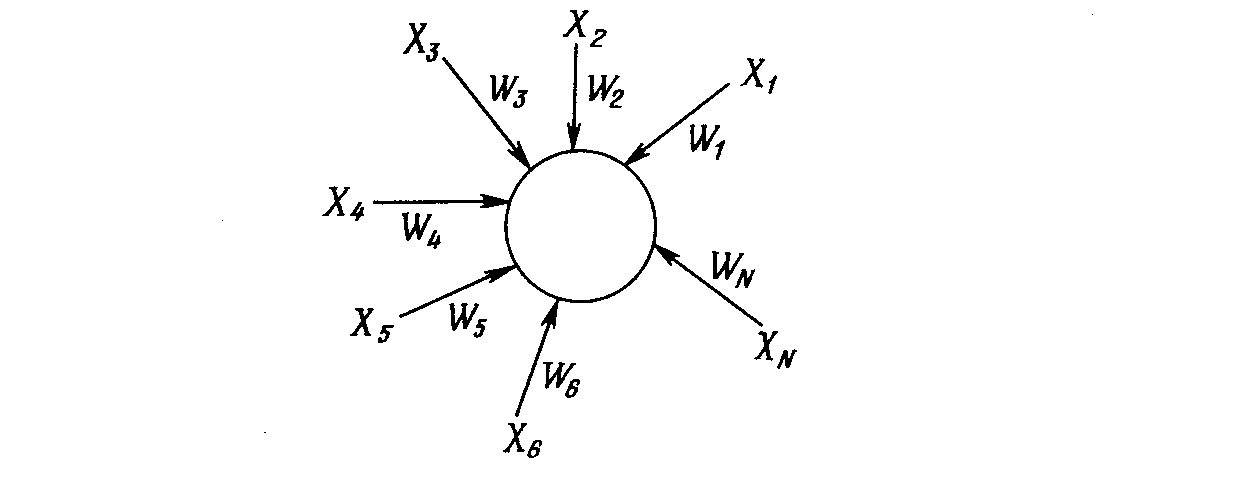
Модель нейрона
Т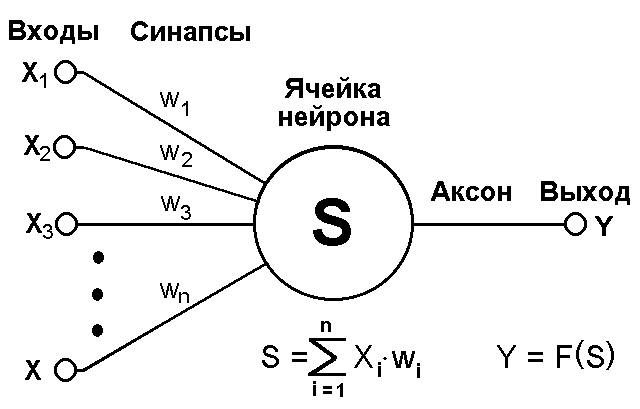 екущее
состояние нейрона определяется, как
взвешенная сумма его входов:
екущее
состояние нейрона определяется, как
взвешенная сумма его входов:
![]() (1)
(1)
Выход нейрона есть функция его состояния:
y = f(s) (2)
а) функция единичного
скачка; б) линейный порог (гистерезис);
в) сигмоид – гиперболический
тангенс; г) сигмоид – формула (3)
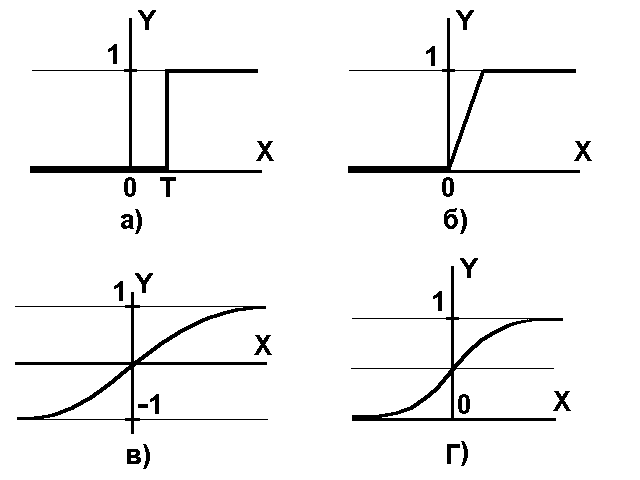
![]() (3)
(3)
![]() (4)
(4)
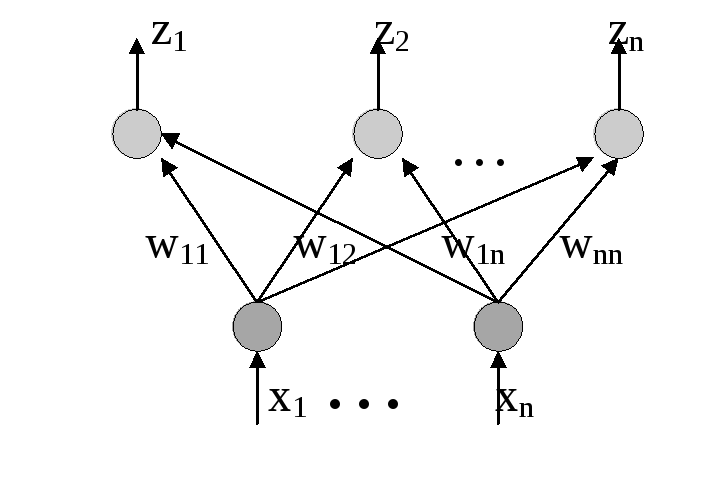
Однослойный перцептрон

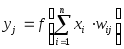 ,
j=1...3 (5)
,
j=1...3 (5)
Процесс, происходящий в НС, может быть записан в матричной форме: Y=F(XW) (6)
Двухслойный перцептрон

Проблема исключающего ИЛИ
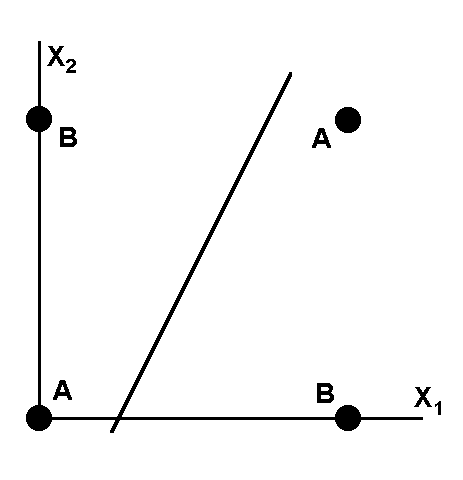
![]()
 ,
k=1...m
,
k=1...m
|
x1 x2 |
0 |
1 |
|
0 |
A |
B |
|
1 |
B |
A |
![]()
Таблица: Линейно разделимые функции
|
n |
22n |
Число линейно разделимых функций |
|
1 |
4 |
4 |
|
2 |
16 |
14 |
|
3 |
256 |
104 |
|
4 |
65536 |
1882 |
|
5 |
4,3х109 |
94572 |
|
6 |
1,8х1019 |
15 028 134 |
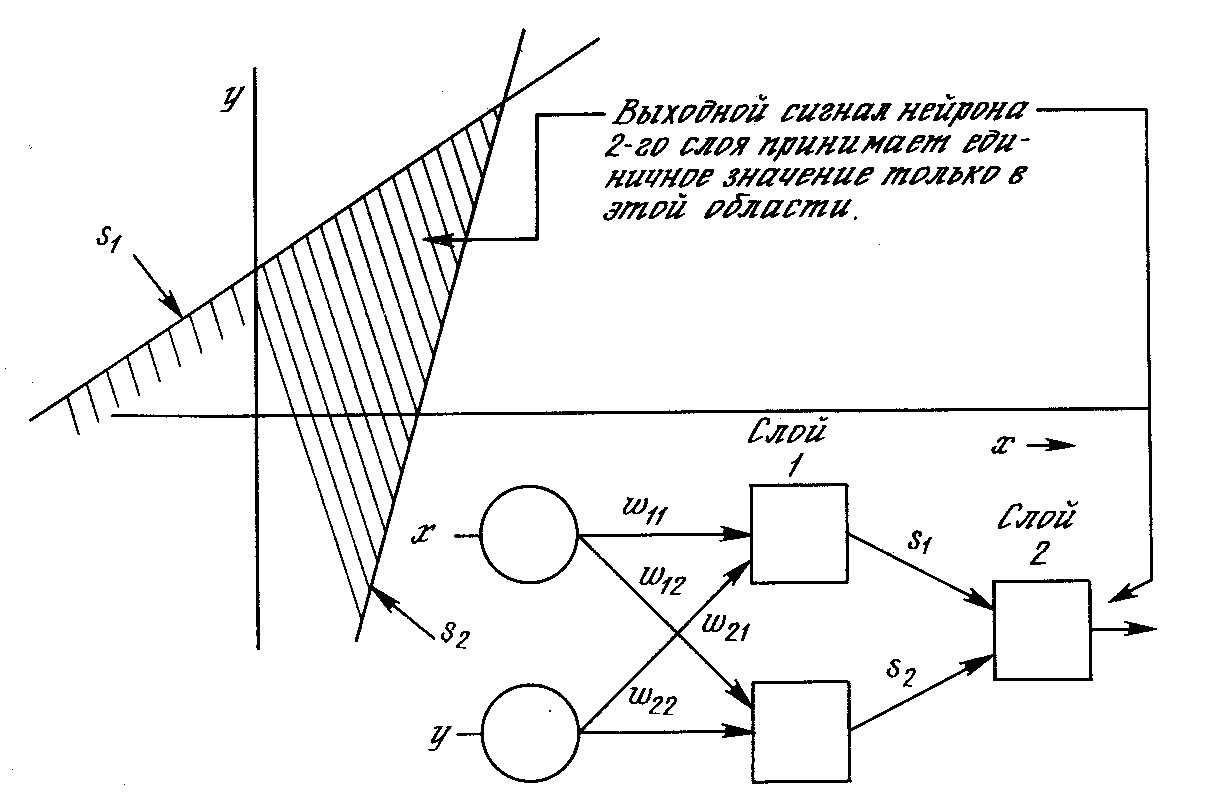
Выпуклая область решений, задаваемая двухслойной сетью
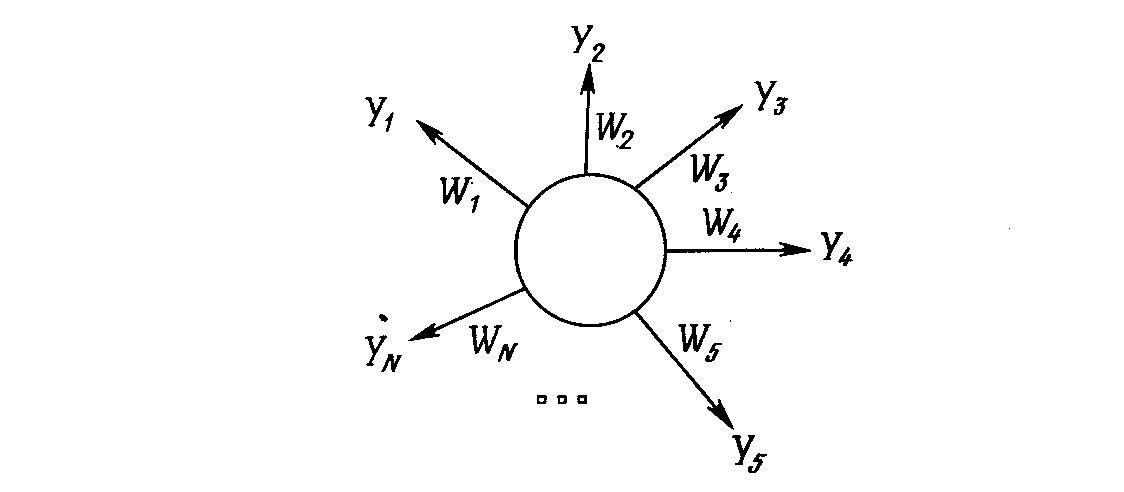
Сеть «Инстар» Гроссберга
Алгоритм обучения:
wi(t+1) = wi(t) + [xi – wi(t)],
где wi – вес входа хi; хi – i–й вход; – нормирующий коэффициент обучения, который имеет начальное значение 0,1 и постепенно уменьшается в процессе обучения.
Сеть «Аутстар» Гроссберга
Алгоритм обучения:
wi(t+1) = wi(t) + [yi – wi(t)],
где представляет собой нормирующий коэффициент обучения, который в начале приблизительно равен единице и постепенно уменьшается до нуля в процессе обучения
Обучение однослойного перцептрона
1. Проинициализировать элементы весовой матрицы (обычно небольшими случайными значениями).
2. Подать на входы один из входных векторов, которые сеть должна научиться различать, и вычислить ее выход.
3. Если выход правильный, перейти на шаг 4.
Иначе вычислить разницу между идеальным и полученным значениями выхода:
![]()
Модифицировать веса в соответствии с формулой:
![]()
где t и t+1 – номера соответственно текущей и следующей итераций; – коэффициент скорости обучения, 0<Ј1; i – номер входа; j – номер нейрона в слое.
Очевидно, что если YI > Y весовые коэффициенты будут увеличены и тем самым уменьшат ошибку. В противном случае они будут уменьшены, и Y тоже уменьшится, приближаясь к YI.
4. Цикл с шага 2, пока сеть не перестанет ошибаться.
На втором шаге на разных итерациях поочередно в случайном порядке предъявляются все возможные входные вектора.
Обучение без учителя
Сигнальный метод обучения Хебба
![]() (1)
(1)
При обучении по данному методу усиливаются связи между возбужденными нейронами.
дифференциальный метод обучения Хебба.
![]() (2)
(2)
сильнее всего обучаются синапсы, соединяющие те нейроны, выходы которых наиболее динамично изменились в сторону увеличения.
Алгоритм обучения
1. На стадии инициализации всем весовым коэффициентам присваиваются небольшие случайные значения.
2. На входы сети подается входной образ, и сигналы возбуждения распространяются по всем слоям согласно принципам классических прямопоточных (feedforward) сетей[1], то есть для каждого нейрона рассчитывается взвешенная сумма его входов, к которой затем применяется активационная (передаточная) функция нейрона, в результате чего получается его выходное значение yi(n), i=0...Mi-1, где Mi – число нейронов в слое i; n=0...N-1, а N – число слоев в сети.
3. На основании полученных выходных значений нейронов по формуле (1) или (2) производится изменение весовых коэффициентов.
4. Цикл с шага 2, пока выходные значения сети не застабилизируются с заданной точностью. На втором шаге цикла попеременно предъявляются все образы из входного набора.
Алгоритм Кохонена
![]()
 (3)
(3)
![]() ,
(4)
,
(4)
![]() ,
нормализация
(5)
,
нормализация
(5)
![]() ,
(6)
,
(6)
![]() ,
где n – размерность
вектора весов для нейронов инициализируемого
слоя (7)
,
где n – размерность
вектора весов для нейронов инициализируемого
слоя (7)
Обучение многослойного перцептрона. Алгоритм обратного распространения ошибки
![]() (1)
(1)
![]() (2)
(2)
![]() (3)
(3)
Третий множитель sj/wij, очевидно, равен выходу нейрона предыдущего слоя yi(n-1).
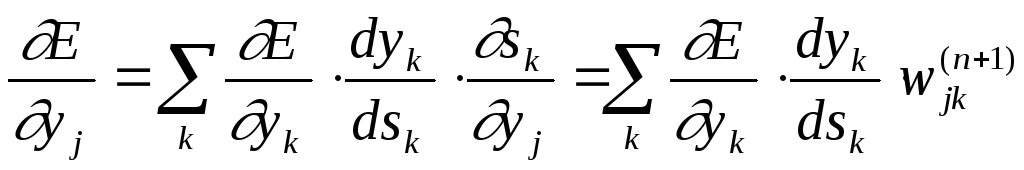 (5)
(5)
Здесь суммирование по k выполняется среди нейронов слоя n+1.
Введя новую переменную
![]() (6)
(6)
мы получим рекурсивную формулу для расчетов величин j(n) слоя n из величин k(n+1) более старшего слоя n+1.
![]() (7)
(7)
Для выходного же слоя
![]() (8)
(8)
Теперь мы можем записать (2) в раскрытом виде:
![]() (9)
(9)
Иногда для придания процессу коррекции весов некоторой инерционности, сглаживающей резкие скачки при перемещении по поверхности целевой функции, (9) дополняется значением изменения веса на предыдущей итерации
![]() (10)
(10)
где – коэффициент инерционности, t – номер текущей итерации.
Таким образом, полный алгоритм обучения НС с помощью процедуры обратного распространения строится так:
1. Подать на входы сети один из возможных образов и в режиме обычного функционирования НС, когда сигналы распространяются от входов к выходам, рассчитать значения последних. Напомним, что
![]() (11)
(11)
где M – число нейронов в слое n-1 с учетом нейрона с постоянным выходным состоянием +1, задающего смещение; yi(n-1)=xij(n) – i-ый вход нейрона j слоя n.
yj(n) = f(sj(n)), где f() – сигмоид (12)
yq(0)=Iq, (13)
где Iq – q-ая компонента вектора входного образа.
2. Рассчитать (N) для выходного слоя по формуле (8).
Рассчитать по формуле (9) или (10) изменения весов w(N) слоя N.
3. Рассчитать по формулам (7) и (9) (или (7) и (10)) соответственно (n) и w(n) для всех остальных слоев, n=N-1,...1.
4. Скорректировать все веса в НС
![]() (14)
(14)
5. Если ошибка сети существенна, перейти на шаг 1. В противном случае – конец.
Возможные проблемы
-
Паралич сети
-
Локальные минимумы
-
Размер шага
-
Временная неустойчивость

Структурная схема сети Хопфилда
 (1)
(1)
Здесь i и j – индексы, соответственно, предсинаптического и постсинаптического нейронов; xik, xjk – i-ый и j-ый элементы вектора k-ого образца.
Алгоритм функционирования (p – номер итерации):
1. На входы сети подается неизвестный сигнал.
yi(0) = xi , i = 0...n-1, (2)
2. Рассчитывается новое состояние нейронов
![]() ,
j=0...n-1 (3)
,
j=0...n-1 (3)
и новые значения аксонов
![]() где f – в виде
скачка, приведенная на рис.1а. (4)
где f – в виде
скачка, приведенная на рис.1а. (4)
Рис.1
Активационные функции

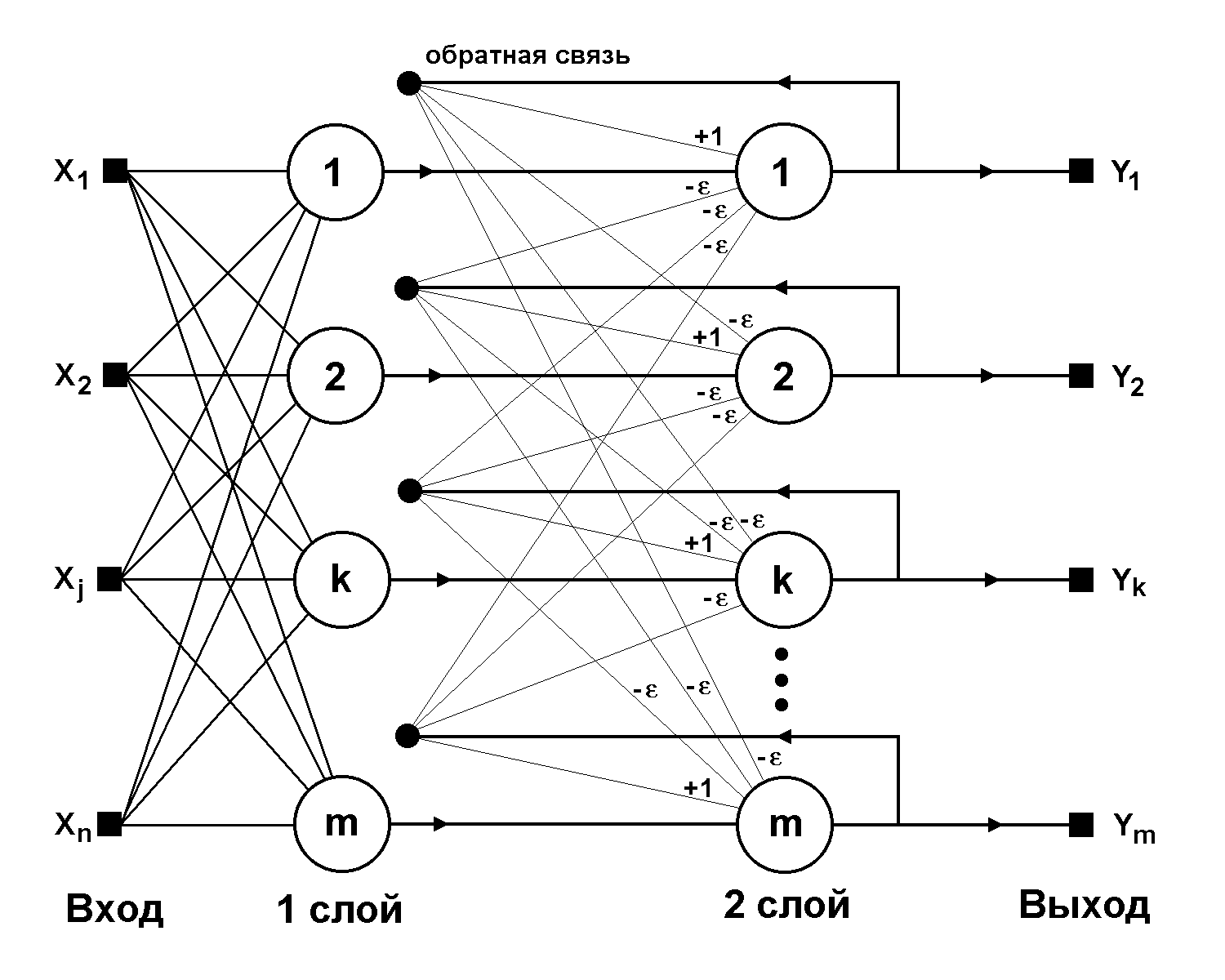
Структурная схема сети Хэмминга
![]() ,
i=0...n-1, k=0...m-1 (5)
,
i=0...n-1, k=0...m-1 (5)
Tk = n / 2, k = 0...m-1 (6)
Здесь xik – i-ый элемент k-ого образца.
0 < < 1/m. Синапс нейрона, связанный с его же аксоном имеет вес +1.
Алгоритм функционирования:
1. На входы сети подается неизвестный вектор X = {xi:i=0...n-1}, исходя из которого рассчитываются состояния нейронов первого слоя:
![]() ,
j=0...m-1 (7)
,
j=0...m-1 (7)
После полученными значениями инициализируются значения аксонов второго слоя:
yj(2) = yj(1), j = 0...m-1 (8)
2. Вычислить новые состояния нейронов второго слоя:
![]() (9)
(9)
и значения их аксонов:
![]() , f имеет вид
порога (рис. 1б) (10)
, f имеет вид
порога (рис. 1б) (10)
3. Проверить, изменились ли выходы нейронов второго слоя за последнюю итерацию. Если да – перейди к шагу 2. Иначе – конец.
Известные алгоритмы обучения
|
Парадигма |
Обучающее правило |
Архитектура |
Алгоритм обучения |
Задача |
|
С учителем |
Коррекция ошибки |
Однослойный и многослойный перцептрон |
Алгоритмы обучения перцептрона Обратное распространение Adaline и Madaline |
Классификация образов Аппроксимация функций Предскащание, управление |
|
Больцман |
Рекуррентная |
Алгоритм обучения Больцмана |
Классификация образов |
|
|
Хебб |
Многослойная прямого распространения |
Линейный дискриминантный анализ |
Анализ данных Классификация образов |
|
|
Соревнование |
Соревнование |
Векторное квантование |
Категоризация внутри класса Сжатие данных |
|
|
Сеть ART |
ARTMap |
Классификация образов |
||
|
Без учителя |
Коррекция ошибки |
Многослойная прямого распространения |
Проекция Саммона |
Категоризация внутри класса Анализ данных |
|
Хебб |
Прямого распространения или соревнование |
Анализ главных компонентов |
Анализ данных Сжатие данных |
|
|
Сеть Хопфилда |
Обучение ассоциативной памяти |
Ассоциативная память |
||
|
Соревнование |
Соревнование |
Векторное квантование |
Категоризация Сжатие данных |
|
|
SOM Кохонена |
SOM Кохонена |
Категоризация Анализ данных |
||
|
Сети ART |
ART1, ART2 |
Категоризация |
||
|
Смешанная |
Коррекция ошибки и соревнование |
Сеть RBF |
Алгоритм обучения RBF |
Классификация образов Аппроксимация функций Предсказание, управление |
Created
by