

3. Классификация многопроцессорных систем. Вс с разделяемой общей памятью. Машины smp иNuma. Примеры.
См. вопрос 2.
Стандартный механизм доступа к шине позволяет любому процессору достичь любого физического адреса в системе. Как и в случае перекрестного соединения, вся память равноудалена от процессоров, поэтому все процессоры имеют одинаковое время доступа (latency) к памяти. Такая конфигурация называется symmetric multiprocessor (SMP).
Типичным примером организации многопроцессорной системы с симметричным доступом к памяти, основанной на шинной архитектуре, является компьютер Intel Pentium Pro four-processor “quad pack”, иллюстрирующий первый SMP для широкого рынка (рис. 1.4).

Сервер Sun Enterprise Server так же поддерживает симметричный доступ к памяти (SMP), не смотря на то, что она физически распределена между процессорными платами.
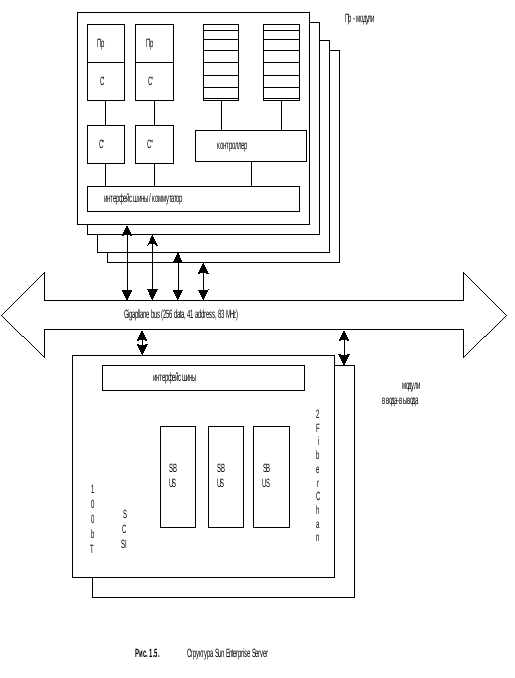
Дополнение процессоров в коммутатор – дорого, однако общая производительность системы возрастает с числом портов. Цена добавления процессоров к шине – мала, но производительность всей системы остается фиксированной (из-за скорости шины).
Один из подходов к созданию масштабируемой среды взаимодействия процессоров показан на рис 1.6. Процессор и модули памяти интегрированы между собой таким образом, что доступ к локальной памяти осуществляется существенно быстрее, чем к удаленной. Такая организация носит название несимметричного доступа к памяти - nonuniform memory access (NUMA) - при котором контроллер локальной памяти определяет, выполнять ли доступ к локальной памяти или осуществлять транзакцию сообщения к удаленной памяти.

Примером использования NUMAявляется CRAY T3E, показанный на рис. 1.7.

CRAY T3E может содержать до тысяч процессоров, работающих с глобальным общим адресным пространством. Каждый узел содержит DEC Alpha процессор (Пр), локальную память (П), интегрированный с контроллером памяти сетевой интерфейс и сетевой коммутатор. Компьютер организован как трехмерный куб, в котором каждый модуль соединяется с его соседями.
4. Классификация многопроцессорных систем. Вс с распределенной областью памяти. Примеры.
См. вопрос 2.
Message-passing architectures (MPA).
В качестве узлов для построения системы MPA используют законченные компьютеры, включающие микропроцессор, память и подсистему ввода-вывода, объединенные коммуникационной средой, обеспечивающую взаимодействие процессоров посредством простых операций ввода-вывода.
Системы с распределенной памятью имеют существенную дистанцию между программной моделью и действительными аппаратными примитивами. Коммуникации осуществляются через средства операционной системы или библиотеку вызовов, которые выполняют много акций более низкого уровня, включающих операции коммуникации.
Наиболее общие операции взаимодействия на пользовательском уровне (user-level) в MPA есть варианты посылки (SEND) и получения (RECEIVE) сообщения. Передача данных из одного локального адресного пространства к другому произойдет, если посылка сообщения со стороны процесса - отправителя будет востребована процессом - получателем сообщения.
Сочетание посылки и согласованного приема сообщения выполняет логическую связку – синхронизацию события, т.е. копирования из памяти в память. Имеется несколько возможных вариантов синхронизаии этих событий, в зависимости от того, завершиться ли SEND к моменту, когда RECEIV будет выполнен или нет (ждём или не ждём, пока сообщение получат).
В ранних системах, обычно использовалась структура гиперкуба (на 2n узлов), в которой каждый узел соединялся с n другими узлами, бинарные адреса которых отличались на один бит. Другие машины имели решетчатую структуру, где узлы соединялись с соседями по двум или трем измерениям. Такая технология для более ранних машин была важна, потому что только соседние процессоры могли быть использованы в качестве адресата в операциях приема-посылки. Процесс - отправитель посылал сообщение, а процесс – получатель получал сообщение через канал (link).
Физическая организация коммуникационной сети настолько влияла на программные модели ранних машин, что параллельные алгоритмы очень часто именовались в соответствии со спецификой внутренней топологии соединений, например, кольцо (Ring), матрица (grid), гиперкуб (hypercube). Однако для придания большей универсальности, системы стали обеспечивать поддержку взаимодействия между независимыми процессорами, а не только между соседними. Первоначально это поддерживалось перенаправлением данных внутри уровня сообщений вдоль каналов (links) в сети. Вскоре эта распределяющая функция была перенесена на уровень аппаратного обеспечения. Каждый узел стал содержать процессор с памятью и коммутатор, который мог перенаправлять сообщения. Тем не менее, в таком подходе, известным под названием store-and-forward, время передачи сообщения пропорционально числу необходимых этапов передачи в сети, поэтому, все-таки, влияние топологии внутренних соединений оставалось существенным.
Такое внимание к сетевой топологии было значительно ослаблено с появлением более универсальных сетей, которые поплайнизировалипередачу сообщения через каждый коммутатор, формирующий внутреннюю сеть.
Один из важных примеров такой машины является IBM SP-2 - масштабируемый параллельный компьютер, состоящий из узлов на базе рабочих станций RS6000, масштабируемой сети и сетевым интерфейсом. Сеть представляет собой каскадное 8x8 коммутируемое перекрестное соединение.
Другим примером является параллельный компьютер Intel Paragon. Каждая плата (узел) представляет собой SMP с двумя или более процессорами (i860) и кристалл сетевого интерфейса (NI) связанный с шиной памяти (Memory bus). Узел имеет механизм DMA для передачи блоков данных через сеть высокого уровня. Сеть представляет собой 3D куб, аналогичный структуре сети компьютера CRAY T3E.