

Алгоритмы распознавания речевых сигналов с использованием признаков, основанных на линейном предсказании.
Существуют различные методы распознавания речи, однако, в последнее время основным стал метод сравнения с эталоном. Главным образом это связано с прогрессом в области производства электронных компонентов, в частности, с увеличением вычислительной мощности процессоров и объемов памяти. В методе сопоставления с эталоном сигнал сравнивается заранее записанным эталонным образом и вычисляется степень его подобия. Результатом распознавания является наиболее похожий эталонный образ.
При распознавании путем сопоставления возникают некоторые проблемы, наиболее типичными из которых являются следующие:
временные изменения характерных речевых сигналов. Причиной изменения является различная скорость произнесения одних и тех звуков, то есть непостоянство длительности. Даже одни и те же слова, произнесенные одним и тем же человеком, каждый раз имеют разную длительность.
Влияние размеров органов речи. Размеры органов речи у разных людей различны. Поэтому слова которые произносятся голосовыми органами одинаковой формы, но разного размера имеют различные резонансные частоты.
Первая проблема связана с необходимостью подстраивать временные интервалы при сопоставлении (временная нормализация). Известно много способов согласования длительностей которые сильно различаются по эффективности и объему вычислений. В некоторых методах допускаются пропуски элементов реализации, иногда накладывается ограничение на множество вариантов растяжения реализации и эталона, позволяющие учесть ограничения на вариации темпа произнесения слова.
Проблема изменений, связанных с диктором, чрезвычайно сложна. В настоящее время наметился ряд путей ее частичного решения. Некоторые из них будут рассмотрены ниже.
4.1. Меры сходства.
Выбор
меры сходства
![]() зависит от применяемого описания речевых
сигналов и в значительной мере определяется
удобствами вычислений. В[6]рассмотрены наиболее употребительные
меры сходства.
зависит от применяемого описания речевых
сигналов и в значительной мере определяется
удобствами вычислений. В[6]рассмотрены наиболее употребительные
меры сходства.
 -
Хэммингово расстояние (количество
несовпадающих компонент), еслиxi
иeiимеют двоичные компоненты, например,
знаки разности энергий в соседних
спектральных полосах.
-
Хэммингово расстояние (количество
несовпадающих компонент), еслиxi
иeiимеют двоичные компоненты, например,
знаки разности энергий в соседних
спектральных полосах.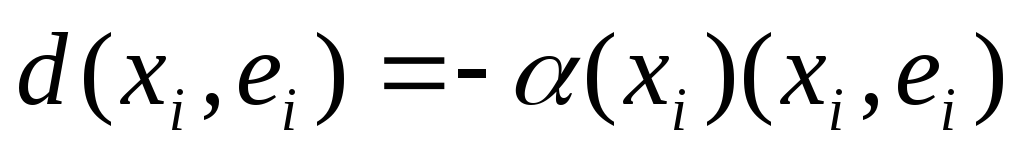 ,
, -
скалярное произведение векторовxi
иei,а(xi)
– некоторый скаляр, зависящий отxi
. Эта мера сходства используется,
если речевые сигналы описываются
посредством авторегрессионной модели.
Тогда элементxi
имеет смысл вектора автокорреляции,ei– смыслb-параметров, а(xi)может быть энергией элементаxi
, взятой в степени (-3/4)
-
скалярное произведение векторовxi
иei,а(xi)
– некоторый скаляр, зависящий отxi
. Эта мера сходства используется,
если речевые сигналы описываются
посредством авторегрессионной модели.
Тогда элементxi
имеет смысл вектора автокорреляции,ei– смыслb-параметров, а(xi)может быть энергией элементаxi
, взятой в степени (-3/4) ,
, - евклидово расстояние между векторами.
- евклидово расстояние между векторами. ,
гдеxiv
иeiv,v=1,…,m
– компоненты наблюдаемогоxi
и эталонногоeiэлементов,iv- дисперсияv-й
компоненты эталонного элементаei.
Эта мера удобна при использовании
элементов, компоненты которых имеют
различную физическую природу.
,
гдеxiv
иeiv,v=1,…,m
– компоненты наблюдаемогоxi
и эталонногоeiэлементов,iv- дисперсияv-й
компоненты эталонного элементаei.
Эта мера удобна при использовании
элементов, компоненты которых имеют
различную физическую природу. .
Эта мера подобна рассмотренной в
предыдущем пункте. Ее удобно использовать
в случае когда распознаваемые элементыxiсостоят только из двоичных компонент
0 и 1, а эталонные элементыeiзаданы частотами встречаемостиpivзначения 1 вv-й
компоненте.
.
Эта мера подобна рассмотренной в
предыдущем пункте. Ее удобно использовать
в случае когда распознаваемые элементыxiсостоят только из двоичных компонент
0 и 1, а эталонные элементыeiзаданы частотами встречаемостиpivзначения 1 вv-й
компоненте. ,
где
,
где -
энергия эталонного элемента и сигнала
в общей полосе частот;
-
энергия эталонного элемента и сигнала
в общей полосе частот;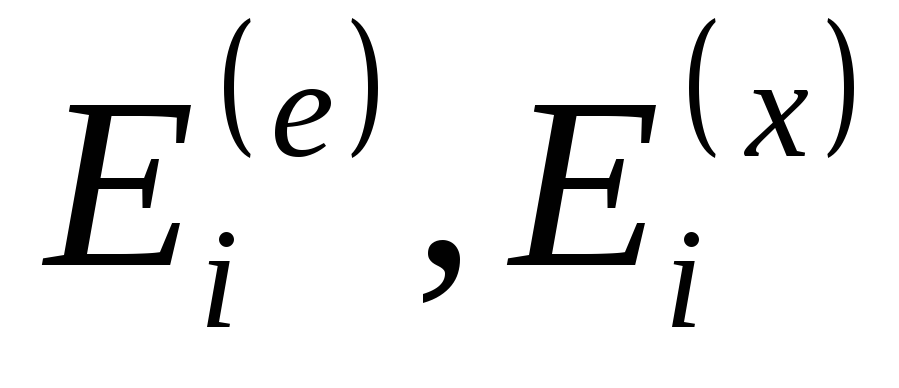 -энергия
на выходеi-го
фильтра;N – число
спектральных полос[7].
-энергия
на выходеi-го
фильтра;N – число
спектральных полос[7].
Окончательным критерием качества выборки является минимум числа ошибок распознавания контрольной выборки.