

21. Організація довідника. Сс-нума.
Ограничение на число процессоров в архитектуре SMP служит побудительным мотивом для развития кластерных систем, В последних же каждый узел имеет локальную основную память, то есть приложения «не видят» глобальной основной памяти. В сущности, когерентность поддерживается не столько аппаратурой, сколько программным обеспечением, что не лучшим образом сказывается на продуктивности. Одним из путей создания крупномасштабных вычислительных систем является технология CC-NUMA. Например, NUMA-система Silicon Graphics Origin поддерживает до 1024 процессоров R10000 [223], a Sequent NUMA-Q объединяет 252 процессора Pentium II [157].
На рис. 14.15 показана типичная организация систем типа CC-NUMA [36]. Имеется множество независимых узлов, каждый из которых может представлять собой, например, SMP-систему. Таким образом, узел содержит множество процессоров, у каждого из которых присутствуют локальные кэши первого (L1) и второго (L2) уровней. В узле есть и основная память, общая для всех процессоров этого узла, но рассматриваемая как часть глобальной основной памяти системы, В архитектуре CC-NUMA узел выступает основным строительным блоком. Например, каждый узел в системе Silicon Graphics Origin содержит два микропроцессора MIPS R10000, а каждый узел системы Sequent NUMA-Q включает в себя четыре процессора Pentium II. Узлы объединяются с помощью какой-либо сети соединений, которая представлена коммутируемой матрицей, кольцом или имеет иную топологию.
Согласно технологии CC-NUMA, каждый узел в системе владеет собственной основной памятью, но с точки зрения процессоров имеет место глобальная адресуемая память, где каждая ячейка любой локальной основной памяти имеет уникальный системный адрес. Когда процессор инициирует доступ к памяти и нужная ячейка отсутствует в его локальной кэш-памяти, кэш-память второго уровня (L2) процессора организует операцию выборки. Если нужная ячейка находится в локальной основной памяти, выборка производится с использованием локальной шины. Если же требуемая ячейка хранится в удаленной секции глобальной памяти, то автоматически формируется запрос, посылаемый по сети соединений на нужную локальную шину и уже по ней к подключенному к данной локальной шине кэшу. Все эти действия выполняются автоматически, прозрачны для процессора и его кэш-памяти,
23. Приклад2. Звернення до пам»яті іншого вузла.
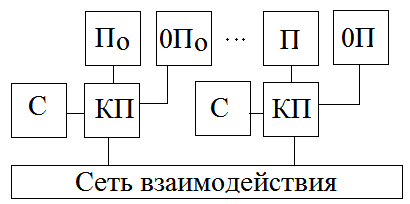
По-0По –узел0
П-0П-узел255
Обращение к справочнику выполняется при выполнении каждой адресной команды. Проблема когерентности отсутствует.
С-справочник, в нем ведется учет использования строк памяти в каждом узле
КП - контроллер памяти
Структура функционального адреса обращения к памяти
31 23 20 0
Узел |
Ряд |
А |
24. Архітектура масово-паралельних систем
Mасово-паралельна обробка (Мassively Parallel Рrocessing − МРР) виникає в зв′язку з такими трьома тенденціями в паралельних обчисленнях:
1) досягнення надвисокої продуктивності;
2) надання мультипроцесорній системі властивості масштабованості −тобто лінійної залежності продуктивності від кількості процесорів; до того ж це надає їм гнучкості у виборі потрібної конфігурації та ціни;
3) здешевлення обчислень.
Неформально МРР вважають такою при кількості процесорів р ≥ 100. Характерною ознакою системи основної пам′яті для МРР є її розподіленість (хоча б фізична) і різноманітність система комунікацій, що оптимізує кількість кроків передач між процесорами. Нижче розглядаються три
приклади організації систем масового паралелізму, від Cray та IBM, що порізному вирішують проблему досягнення високої продуктивності обчислень. CRAY T3D.Система з’явилась усередині 90-х років. CRAY T3D має від 32 до 2048 процесорів Alpha 21264, що зв′язані через комунікаційну мережу у вигляді тривимірного тора. Архітектурними елементами CRAY T3D є обчислювальні вузли, що кожен складається з 2-х процесорів, комунікаційна мережа та
вузли вводу/виводу. Процесори 150Mtz, 64 розрядні RISС-архітектури, кожен має 8Мслів = 64 Мб локальної пам′яті і потужність 300 Mфлопс. Звертання до “чужої” пам′яті процесора є у 6 разів повільнішим від звертання до власної. До складу обчислювального вузла входять також контролер асинхронного доступу до локальної пам′яті без переривань процесора, та мережний інтерфейс для формування посилок передач чер комунікаційну мережу. Комунікаційна мережа являє собою три-вимірну гратку зі швидкістю обміну 140 Мб/сек, що має такі переваги невеликої кількості зв′язків при взаємодії різних процесорів (при 128 процесорах − 6 кроків, для 2048 − 12), а
також можливість вибору іншого маршруту замість пошкодженого. IBM SP2 На відміну від Cray T3D де реалізована архітектура розподіленої спільної пам′яті, в системі IBM SP2 (Scalable Processing) використаний інший підхід − архітектури розподіленої пам′яті з передачею повідомлень. Такий вибір диктувався гнучкістю архітектури, до якої прагнули розробники.
Система SP2 може мати від 2 до 512 процесорних вузлів, побудованих на базі процесора Power2 RS/6000 з локальною пам′яттю 64 Мб. Треба відзначити використання серійного процесора RS/6000 для робочих станцій, що дало змогу використати для SP2 кілька тисяч застосувань без
перепрограмування. Кожний процесор працює під управлінням власної копії операційної системи AIX. В SP2 підтримуються два основних типи вузлів: обчислювальні та серверні. ІВМ розробила гнучку конфігурацію вузлів в залежності від потреб користувача і замовника. Найбільш уживаними є конфігурації P2SC Thin, P2SC Wide і SMP High. Останній варіант − для серверного вузла на 2, 4, 6, і 8 процесорів. Вузли Thin і Wide є однопроцесорними і відрізняються
показниками обсягів пам′яті та продуктивності. При тактовій частоті усього 99,7 МГц пікова продуктивність процесора Power2 RS/6000 складає 260 Mфлопс, а “широкі” вузли типу Wide можуть мати до 2 Гб оперативної пам′яті та 2,1 Гб/сек пропускної здатності. Вузли SP2 зв′язані між собою швидкісним комутатором, щоб обмежити малопродуктивні інтерфейси операційної системи АІХ. Комутатор побудований на принципах комутації пакетів, являє собою багатокаскадну, з обхідними шляхами комутаційну мережу, що забезпечує топологію зв′язку
“кожний з кожним”. Наслідком такої конструкції є лінійне зростання пропускної здатності комутатора з ростом розмірів системи, а також постійна пропускна здатність каналу зв′язку між вузлами незалежно від їх розташування. Кожний кінець двостороннього каналу зв′язку забезпечує 40 Мб/сек. В результаті латентність зв′язку між підзадачами складає 40мкс (врежимі UDP/IP ∼ 300 мкс), а пропускна здатність в цих двох режимах, відповідно, 35 Мб/сек і 10 Мб/сек.
Intel ASCI Red Для досягнення найвищих показників паралельних систем для вирішення задач оборонної тематики міністерством енергетики США в 1995 р. була ініційована програма ASCI (Advanced Scientific Computing Intitretive) з 900 млн. фінансування на побудову масово-парарельних систем. Першою з них стала ASCI Intel Red Supercomputer, що в 1996 р. вперше перевищила рубіж середньої продуктивності 1 Терафлопс (1,06 Tфлопс). Система мала
9216 процесорів Intel Pentium Pro, організований у двопроцесорні вузли, що з′єднуються через три-вимірну сітку зв′язку 38*32*2. Система мала сумарну оперативну память 596 Гб, дві дискові дистели Raid по 1Гб; пікову потужність вузла 400 Mфлопс і 1,8 Tфлопс всієї системи.
Два процесори вузла мали спільну пам′ять і працювали при виконанні паралельних завдань таким чином, що другий процесор обробляв паралельні потоки першого процесора або був його комунікаційним співпроцесором, або зовсім не використовувався. Програмне забезпечення включало операційну систему UNIX, компілятор з паралельної версії Фортрана НPF та бібліотеку
MPI. Час напрацювання на віднову одного вузла складав більше 50 годин, а час відновлення з нейтральної точки всієї системи близько 5хв. Система проектувалась так, щоб забезпечити безперебійну роботу понад чотири тижні, тому на ній можна було розв’язувати масштабні науково-технічні задачі з широкого кола застосувань.
25. Кла́стер — це декілька незалежних обчислювальних машин, що використовуються спільно і працюють як одна система для вирішення тих чи інших задач, наприклад, для підвищення продуктивності, забезпечення надійності, спрощення адміністрування, тощо. Обчислювальний кластер потрібен для збільшення швидкості обрахунків за допомогою паралельних обчислень.
Один з перших архітекторів кластерної технології Грегорі Пфістер дав кластеру наступне визначення: «Кластер — це різновид паралельної або розподіленої системи, яка:
складається з декількох зв'язаних між собою комп'ютерів;
використовується як єдиний, уніфікований комп'ютерний ресурс».
Зазвичай розрізняють наступні основні види кластерів:
відмовостійкі кластери (High-availability clusters, HA, кластери високої доступності)
кластери з балансуванням навантаження (Load balancing clusters)
обчислювальні кластери (High perfomance computing clusters)
grid-системи.
Обчислювальний кластер, як і будь-яка система паралельних обчислень, є ефективним, коли обчислювальна задача, яку необхідно вирішити, принципово не може бути вирішена за допомогою комп'ютерів широкого вжитку (наприклад, персональних комп'ютерів), або вирішення задачі за допомогою поширених систем вимагає тривалого часу. До таких задач належать:
Задачі, що «не вміщуються» в оперативну пам'ять (вимагають десятки гігабайт і більше)
Обчислення, що вимагають значної кількості операцій і відповідно тривалого часу (дні, тижні, місяці)
Коли потрібно обрахувати велику кількість задач (десятки, сотні) за короткий проміжок часу
Кластер є ефективним не для всіх задач. Якщо задача ефективно вирішується за допомогою поширених систем, то використання кластеру може бути неефективним.
Чому потрібний кластер?
Основна мета використання кластера - забезпечення високої доступності бази даних. Сьогодні для додатків все частіше висуваються такі бізнес - вимоги, щоб був забезпечений доступ до даних в режимі 24 години на добу 7 днів на тиждень, і недоступність бази даних в зв’язку з будь-якими причинами часто просто неприпустима. Використання кластера серверів баз даних може допомогти запобігти недоступності даних через вихід з ладу сервера, викликаного збоєм у програмному забезпеченні, необхідністю виконання операцій з обслуговування сервера або через втрату мережного з'єднання з сервером. Однак кластер не гарантує, що ніколи не відбудеться відмова сервера, він допомагає зменшувати число виходів з ладу і надає адміністраторам бази даних і сервера можливості вивести сервер зі стану відмови без втрат.
Класифікація: