

1.2.7. Выделение начала и конца слова
Проблема определения начала и конца речевого сообщения является актуальной для многих областей обработки речи. В частности, точное определение границ слова является одним из наиболее важных моментов в распознавании изолированных слов, т.к. большой процент ошибок возникает именно вследствие неправильного определения граничных точек. Проблема определения границ может быть тривиально решена, когда отношение сигнал/шум достаточно велико (порядка 60дБ), например, когда запись слов производится в звукоизолированной комнате с помощью высококачественного микрофона. В этом случае энергия звуков речи с самым низким уровнем (таких, как слабые фрикативы) превышает энергию фонового шума, поэтому граничные точки достаточно легко определить с помощью простого измерения энергии или амплитуды сигнала.
Совсем другая картина наблюдается в случае, когда система распознавания речи работает в реальной обстановке, где отношение сигнал/шум составляет 15-20дБ.
В работе [15] сравнивались три алгоритма определения границ изолированных слов: Word, Word1, Word2. Эксперименты производились непосредственно в машинном зале, где уровень шумов составляет примерно 60дБ.
Алгоритм Word.
Предположим, что s(N) - отсчеты речевого сигнала. Для нахождения границ слова оцениваются абсолютные значения амплитуд сигнала |s(i)|, где i=1,2,...,N.
Устанавливаются следующие пороги:
P1 порог по абсолютному значению амплитуды начала слова;
P2 порог по абсолютному значению амплитуды конца слова;
P3 число отсчетов в начале слова, где сигнал превышает порог Р1;
P4 максимально допустимая величина паузы внутри слова;
P5 минимально допустимая длина слова.
Поиск границ производится в прямом направлении, т.е. от i=1...N.
Алгоритм Word1.
Используется оценка абсолютного значения амплитуды сигнала|s(i)|. Вводится ограничение на количество слов в s(N). Если алгоритм Word может выделить границы нескольких слов, расположенных в s(N) с паузами, превышающими величину P4, то алгоритм Word1 допускает наличие в массиве s(N) только одного слова. Начальная граница ищется точно так же, как в предыдущем алгоритме. Поиск конечной точки производится в обратном направлении (i=N,N-1,...,1).
Количество просматриваемых отсчетов сигнала в данном алгоритме значительно сокращается по сравнению с предыдущим, что существенно повышает его быстродействие. В целях дополнительного повышения скорости работы алгоритма предварительная оценка граничных точек производится с некоторым шагом , где=100 отсчетам (5мс). После получения грубых оценок граничных точек производится возврат на-1 отсчет и уточнение границ с шагом=1.
Алгоритм Word2.
Используются измерения кратковременной энергии и числа переходов через нуль речевого сигнала. Алгоритм Word2 является модифицированным вариантом алгоритма определения граничных точек, описанного в [16]. Обладает способностью самоадаптации к фоновой акустической обстановке. Пороги для решающего правила автоматически настраиваются в соответствии с характеристиками фонового шума, присутствующего в момент записи слова.
Предполагается, что в течение первых 100мс интервала ввода речевой сигнал отсутствует. На этом участке измеряются статистические характеристики фоновой паузы, включающие в себя среднее значение и дисперсию числа переходов через нуль, а также среднее значение кратковременной энергии. На основании этих измерений выбирается порог по числу переходов через нуль. Затем вычисляются два энергетических порога. Для этого используется среднее значение кратковременной энергии паузы и максимальное значение кратковременной энергии речевого сигнала, которое в отличие от значения максимальной энергии, вычисляемого для каждого нового слова в алгоритме, приведенном в [16], фиксировано и задается заранее. Это значительно увеличивает быстродействие алгоритма.
Предварительная оценка граничных точек производится по энергетическим порогам с грубым шагом (где=10 сегментам длительностью 10мс). Уточнение положения границ производится с помощью оценки числа переходов через нуль.
Экспериментальная проверка описанных выше алгоритмов проводилась на словарях из 63хи 125ислов. Оценка точности определения граничных точек осуществлялась по картинкам видимой речи. Лучшие результаты показал алгоритм Word2, который допустил наименьшее число ошибок в определении границ.
В [17] предложен другой способ выделения границ, обеспечивающий высокую точность и возможность функционирования в реальном масштабе времени.
В качестве характеристики сигнала используется функция:
![]() ,
где S(i,l) - iйотсчет в lмкадре.
,
где S(i,l) - iйотсчет в lмкадре.
Эта функция информативна как для озвученных, так и для шумовых элементов речи. Сформированный таким образом сигнал далее приводится к уровню шумового фона. Для этого перед началом работы определяется усредненный размах и минимальное значение контура функции на фоне. Сумма этих значений дает порог р, который может адаптироваться к изменениям акустической обстановки. Затем функция Flпреобразуется согласно условию
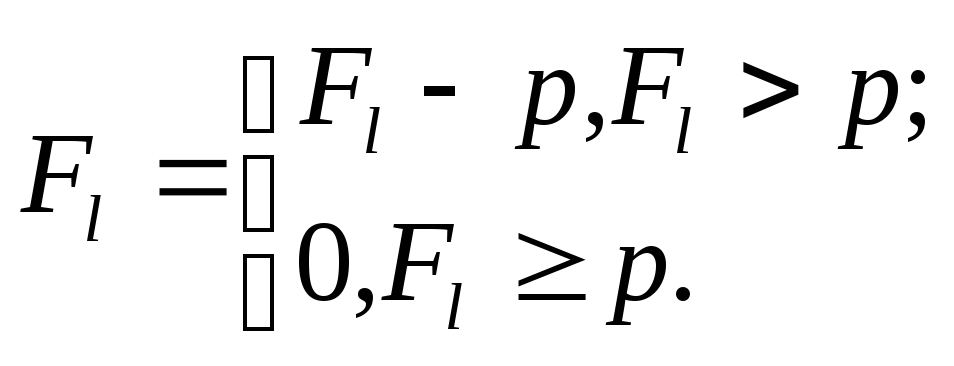
В результате получается сигнал нулевого (при отсутствии речевого сигнала) уровня или приведенный контур функции в противном случае. Далее обработка ведется в два этапа. На первом производится определение множеств точек, соответствующих границам. На втором выделяются "всплески" функции Flи упорядочиваются гипотезы, согласно которым граничные точки объединяются в пары.
В проведенном эксперименте из нескольких сотен слов со сложным с точки зрения выделения границ фонетическим составом было зафиксировано 2% ошибок.
Проблема выделения граничных точек становится особенно важной при распознавании не изолированных слов, а слитной речи.
Вышеописанные методы в ряде случаев способствуют распознаванию слитной речи. В [18] установлено, что в прочитанных текстах прозы паузы совпадают с границами синтаксических единиц, однако, в спонтанной речи одна треть пауз не совпадает с членением речевого потока.