

Лекция №3 Непараметрическое (независящее от распределения) обучение дискриминантных функций
3.1. Пространство весов
Мы уже обсуждали тот факт, что вектор образа X представляется как точка в пространстве образов и что пространство может быть разбито на подобласти для образов, принадлежащих различным категориям. Решающая поверхность, которая делит пространство может быть линейной, кусочно-линейной или нелинейной и может быть в общем виде представлена как:
![]()
где
![]() и
и
![]()
представляют
собой образ и весовой вектор. Проблема
обучения системы состоит в том, чтобы
найти вектор W,
показанный на рис.3.1 на основе априорной
информации, полученной от обучающей
выборки. Возможно и даже более удобно
исследовать поведение обучающих
алгоритмов в пространстве весов.
Пространство весов есть (n+1)
- размерности Эвклидова пространства,
в котором координаты 1
2
... n+1.
Для каждого прототипа
![]() ,
k=1,2,...,M,
m=1,2,...,Nk
(где M
представляет число категорий и Nk
представляет собой число прототипов,
принадлежащих к категории K,
в пространстве W
(пространство
весов) имеется гиперплоскость, в которой
,
k=1,2,...,M,
m=1,2,...,Nk
(где M
представляет число категорий и Nk
представляет собой число прототипов,
принадлежащих к категории K,
в пространстве W
(пространство
весов) имеется гиперплоскость, в которой
![]()
любой
весовой вектор W
на
положительной стороне гиперплоскости
дает wТz..
0. Т.е., если прототип
![]() принадлежит категории 1,
любой весовой вектор W
на
этой стороне гиперплоскости будет
вероятно классифицировать
принадлежит категории 1,
любой весовой вектор W
на
этой стороне гиперплоскости будет
вероятно классифицировать
![]() .
Аналогичные аргументы могут быть
рассмотрены для любого весового вектора
на другой стороне гиперплоскости, где
wТz..
0.
.
Аналогичные аргументы могут быть
рассмотрены для любого весового вектора
на другой стороне гиперплоскости, где
wТz..
0.
Возьмем 2-х классовую проблему для иллюстрации. Предположим, что мы имеем последовательность N1 образов, принадлежащих 1 с общим числом образов N = N1 + Nl. Предположим также, что 1 и 2 -два линейно разделяемых класса. Тогда может быть найден вектор , такой,что:
![]()
и

где
.![]() и
и
![]() представляют собой категории 1
и 2
соответственно.
представляют собой категории 1
и 2
соответственно.
В общем, для N образов имеется N гиперплоскостей в весовом пространстве. Область решения для категории 1 в W - пространстве это область, которая лежит на положительной стороне N1 гиперплоскостей для категории 1 и на отрицательной для N2 гиперплоскостей для категории 2. Предположим, что мы имеем три прототипа Z1, Z2, Z3 и знаем, что все они принадлежат категории 1 . Три гиперплоскости могут быть нарисованы в W - пространстве, как показано на Рис.3.1а, заштрихованная область на Рис.3.1а показывает решающие области в двухклассовой проблеме. В этой области
![]()
![]() и
и
![]()

Т.е.
любое
![]() в этом районе будет вероятно классифицировать
прототипы Z1,
Z2,
Z3
как принадлежащие 1
, в то время как поперечно заштрихованные
области, показанные на рис.3в
в этом районе будет вероятно классифицировать
прототипы Z1,
Z2,
Z3
как принадлежащие 1
, в то время как поперечно заштрихованные
области, показанные на рис.3в
d1![]()
d2![]()
но
d3![]()
любой
из этой области будет классифицировать
Z1
и Z2
как принадлежащий категории 1
и классифицировать Z3
как
относящийся к категории 2
.
любой
из этой области будет классифицировать
Z1
и Z2
как принадлежащий категории 1
и классифицировать Z3
как
относящийся к категории 2
.
К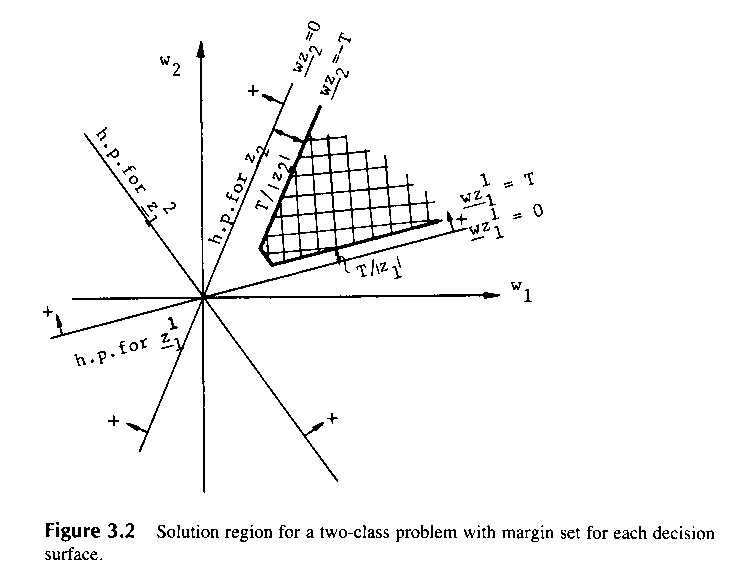 ак
обсуждалось в части 2 решающая поверхность
для двухклассовой задачи предполагает,
что d(w,x)
будет больше 0 для всех образов из одного
класса и меньше 0 для образов, принадлежащих
к другому классу. Но если все
ак
обсуждалось в части 2 решающая поверхность
для двухклассовой задачи предполагает,
что d(w,x)
будет больше 0 для всех образов из одного
класса и меньше 0 для образов, принадлежащих
к другому классу. Но если все
![]() заменить на их отрицательные значения
-
заменить на их отрицательные значения
-
![]() , то решающая поверхность может быть
обобщена как часть
пространства, в котором:
, то решающая поверхность может быть
обобщена как часть
пространства, в котором:
Tz0
![]() =
=![]() -
-
![]()
наша проблема становится в нахождении , которое обеспечивает положительность всех неравенств.
Иногда может быть желательно иметь ограничение (порог) в дискриминантной функции, такой что:
![]() ,
(3.6)
,
(3.6)
где
T0
ограничение (порог). Любой
![]() ,
удовлетворяющий неравенству (3.6) является
весовым вектором решения. Решающая
область теперь изменяется так, как
показано на рис.3.2.
,
удовлетворяющий неравенству (3.6) является
весовым вектором решения. Решающая
область теперь изменяется так, как
показано на рис.3.2.
В
заштрихованной области: оба
![]() и
и
![]() - положительные, в то время как
- положительные, в то время как
![]() отметим,
что вдоль исходной гиперплоскости
образа
отметим,
что вдоль исходной гиперплоскости
образа
![]() ,
(3.7)
,
(3.7)
и
что вектор Z
(расширенный
Z)
является перпендикулярным к гиперплоскости
![]() и направлен в ее положительную сторону.
Тогда линия
и направлен в ее положительную сторону.
Тогда линия
![]() отстоит от
отстоит от
![]() на расстояние
на расстояние
![]() .
Доказательство этого оставим читателю.
.
Доказательство этого оставим читателю.
3.2. Процедура обучения с коррекцией ошибок
Очевидно,
что для случая двух классов ошибка может
существовать, если
![]()
![]() .
.
Тогда
нам необходимо подвинуть весовой вектор
в положительную сторону гиперплоскости
для
![]() ,
другими словами передвигаем вектор W
в
область правильного решения. Наиболее
прямой путь сделать это - передвинуть
W
в
направлении перпендикулярном к
гиперплоскости (т.е. в направлении от
,
другими словами передвигаем вектор W
в
область правильного решения. Наиболее
прямой путь сделать это - передвинуть
W
в
направлении перпендикулярном к
гиперплоскости (т.е. в направлении от
![]() или -
или -![]() ).
Вообще коррекция W
может
быть сформулирована следующим образом:
).
Вообще коррекция W
может
быть сформулирована следующим образом:
заменить W(k) на W(k+1) , так что
![]() ,
если
,
если
![]()
![]() ,
если
,
если
![]()
![]() ,
если
классифицировано
правильно,
,
если
классифицировано
правильно,
где
![]() и
и
![]() - весовые вектора на k-ом
и (k+1)-ом
шагу коррекции, соответственно. Добавление
корректирующего члена
- весовые вектора на k-ом
и (k+1)-ом
шагу коррекции, соответственно. Добавление
корректирующего члена
![]() заставляет вектор
заставляет вектор
![]() двигаться
в направлении
двигаться
в направлении
![]() .
Аналогично,
вычитание корректирующего члена
передвигает вектор
.
Аналогично,
вычитание корректирующего члена
передвигает вектор
![]() направлении
-
направлении
-![]() .
.
В течение этой обучающей процедуры образы представляются по одному, всего N=N1 + N2 прототипов (обучающих образов). После одной итерации все образы представляются снова в той же последовательности, чтобы получить новую итерацию.
Существует несколько правил выбора величины С:
- правило с фиксированной коррекцией,
- правило абсолютной коррекции,
- правило частичной коррекции.
3.2.1. Правило с фиксированной коррекцией
В
этом алгоритме С - выбирается как
фиксированная положительная константа.
Этот алгоритм начинается с любого w(0)
и выражение (3.10) применяется к обучающей
последовательности P,
P
=
![]() .
.
В целом процесс настройки весов будет закончен за конечное число шагов. Выбор С для этого процесса не очень важен. Если теорема сходимости справедлива для С=1, то она будет справедлива для любого С 1, так как изменение С фактически масштабирует все образы без изменения их разделимости.
3.2.2. Правило абсолютной коррекции
В
этом алгоритме С
выбирается
как наименьшее целое
число,
которое передвигает
![]() поперек гиперплоскости образа в область
решения w
каждый раз как классификатор делает
ошибку. Пусть
поперек гиперплоскости образа в область
решения w
каждый раз как классификатор делает
ошибку. Пусть
![]() - среднее из векторов, которые не
удовлетворяют неравенству w
z
T
. Константа С выбирается
так,
что
- среднее из векторов, которые не
удовлетворяют неравенству w
z
T
. Константа С выбирается
так,
что
![]()
![]() ,
,
поэтому

Если
Т=0,
![]() должно быть больше 0 или
должно быть больше 0 или
![]() . Взяв абсолютную величину в (3.3) получаем
. Взяв абсолютную величину в (3.3) получаем
 .
.
Правило абсолютной коррекции также дает решающий весовой вектор за конечное число шагов.
3.2.3. Правило с частичной коррекцией
В
W
пространстве расширенный вектор образа
Z
-
перпендикулярен гиперплоскости
![]() и направлен в положительном направлении,
как показано на рис.3.3.
и направлен в положительном направлении,
как показано на рис.3.3.

Расстояние
от
![]() до желаемой гиперплоскости будет:
до желаемой гиперплоскости будет:
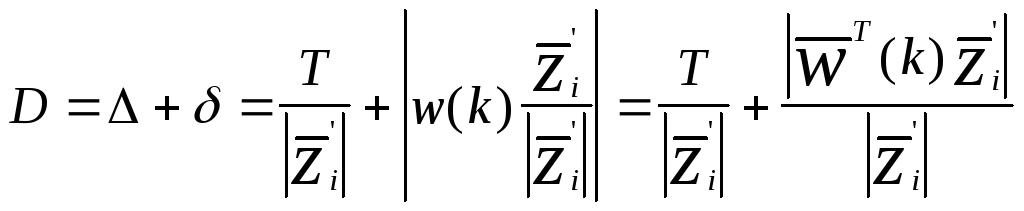 (3.15)
(3.15)
Когда
![]() находится на другой стороне гиперплоскости
находится на другой стороне гиперплоскости
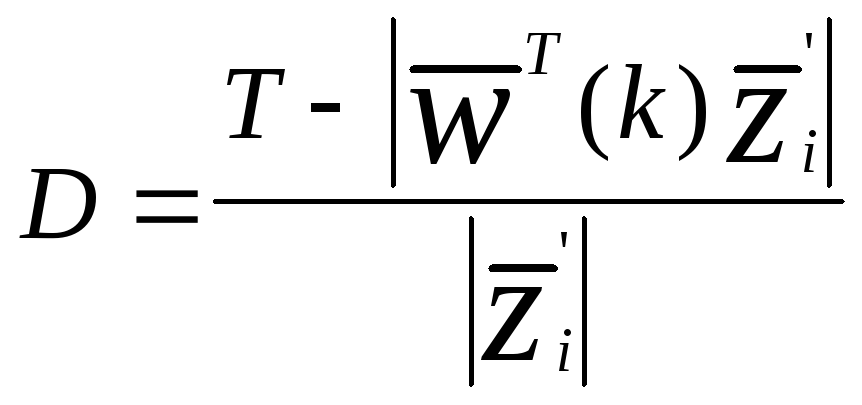
В
алгоритме с частичной коррекцией С -
выбрано так, что
![]()
![]() двигается на часть расстояния в
направлении нормали к желаемой
гиперплоскости. То есть
двигается на часть расстояния в
направлении нормали к желаемой
гиперплоскости. То есть
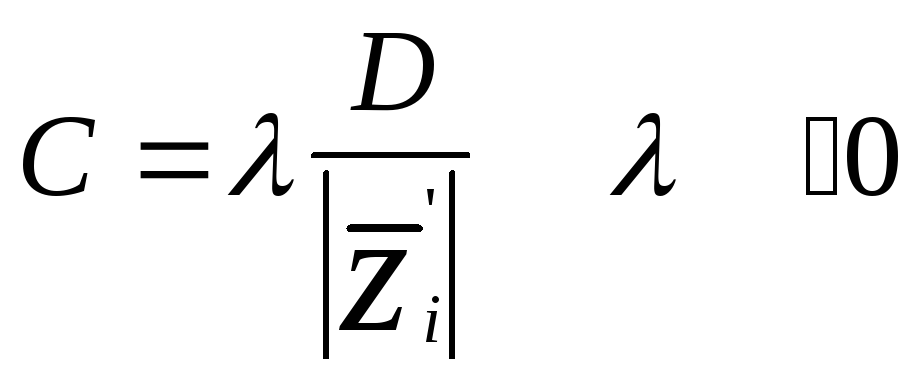
и
![]() -
-![]() =
=
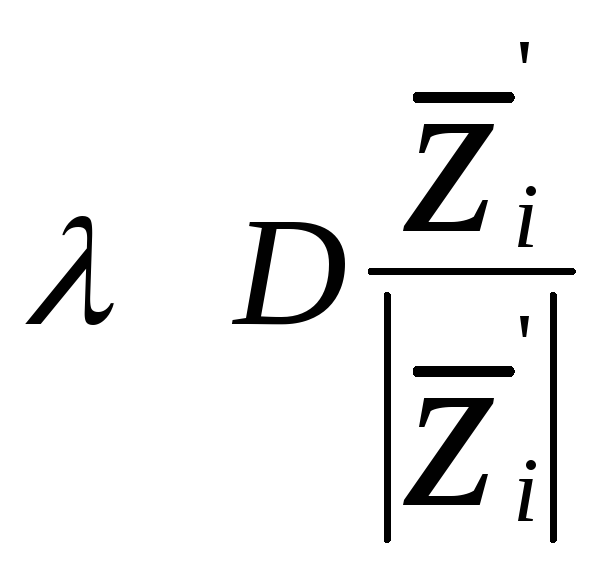
Если порог положить равным 0, то:
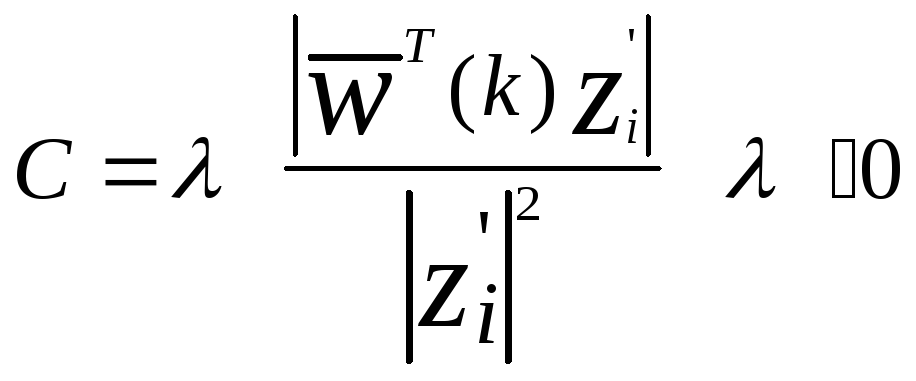

можно видеть, что когда =1 коррекция происходит до гиперплоскости (правило абсолютной коррекции) и когда 1 коррекция короче, чем до гиперплоскости (under relaxation), когда 1 коррекция больше чем до гиперплоскости, (over relaxation).
Для 02 правило частичной коррекции будет или заканчиваться на весовом векторе в конечное число шагов или сходиться к точке на границе решающего пространства весов.
Процедура обучения для всех перечисленных 3-х алгоритмов выглядит следующим образом:
1)
Взять любой
![]() из обучающей последовательности и
проверить d(z),
для определения класса (предполагается
М=2).
из обучающей последовательности и
проверить d(z),
для определения класса (предполагается
М=2).
2)
Если получен правильный ответ, переходим
к следующему
![]()
3) Если имеет место ошибочная классификация, изменяем w(k) на w(k+1).
4)
После того, как будут проверены все
![]() из
обучающей последовательности, повторяем
все процедуры заново в том же порядке.
Если
из
обучающей последовательности, повторяем
все процедуры заново в том же порядке.
Если
![]() линейно
разделимы , все три алгоритма будут
сходиться к правильному
линейно
разделимы , все три алгоритма будут
сходиться к правильному
![]() .
.
На рис 3.4. показаны шаги коррекции для трех различных алогритмов. Абсолютная коррекция заканчивается за 3 шага, в то время как частичная за 4 шага.

Рис 3.4.
Для количества классов больше 2 (M2) может быть предложена подобная процедура. Предположим, что мы имеем обучающую последовательность для всех образов классов wi i=1,2,...,M.
Вычислим дискриминантные функции
di(![]() )=
)=![]()
![]() ,
i=1,2,...,M
,
i=1,2,...,M
Очевидно, мы желаем:
di(![]() )dj(
)dj(![]() )
)
![]()

3.3. Градиентные методы
3.3.1. Общий метод градиентного спуска
Метод градиентного спуска является другим приближением к обучающим системам. Градиентный вектор обладает важным свойством указывающий максимальную скорость увеличения функции по мере увеличения аргумента. Процедура настройки весов может быть сформулирована как:
![]() =
=![]() (3.25)
(3.25)
где
J(w)
- критерий качества, который минимизируется
настройкой
![]() .
Минимум J(w)
может быть достигнут передвижением
.
Минимум J(w)
может быть достигнут передвижением
![]() в
направлении отрицательного градиента.
Процедура может быть описана следующим
образом:
в
направлении отрицательного градиента.
Процедура может быть описана следующим
образом:
1.
Начать с некоторого произвольно
выбранного вектора w(1)
и вычислить градиентный вектор
![]()
2. Получаем следующую величину w(2) передвигаясь на некоторое расстояние от w(1) в направлении наиболее крутого спуска.
k в уравнении (3.25) - положительный скалярный множитель, который устанавливает размер шага. Для его оптимального выбора предполагаем, что J(w) может быть аппоксимирован как:
![]() (3.26)
(3.26)
где
![]()
подставляя (3.25) в (3.26) получим:
![]() (3.27)
(3.27)
Полагая
 для минимизации
для минимизации
![]() мы получим
мы получим
![]() (3.28)
(3.28)
или
 ,
(3.29)
,
(3.29)
которое эквивалентно алгоритму Ньютона для оптимального спуска, в котором
k = D -1.
Некоторые проблемы могут возникнуть с этим оптимальным k ; D -1 в (3.29) может не существовать; используемые матричные операции требуют значительных временных затрат; предположение поверхности второго порядка может быть некорректным. Исходя из этих соображений лучшим выходом будет положить k равным константе.
3.3.2. Персептронная функция критерия
Пусть функция критерия будет:
(3.31)
где суммирование осуществляется по неправильно классифицированным векторам образов. Геометрически Jp(w) пропорционально сумме расстояний неправильно классифицированных образов от гиперплоскости.
Возьмем производную от Jp(w) по w(k) :
(3.32)
где w(k) означает величину w на k-ой итерации. Персептронный обучающий алгоритм может быть сформулирован как
w(k+1)
= w(k)
-
![]() (3.33)
(3.33)
w(k+1) = w(k) + k (3.34)
где Р - последовательность неправильно классифицированных образов при данном w(k) . Уравнение (3.34) может быть затем интерпретировано в том смысле, что (k+1) весовой вектор может быть получен добавлением умноженной на некоторый множитель сумму неправильно классифицированных образов для
k-ого весового вектора.
Это процедура, называемая "many-at-time" ("большое время"), т.к. мы определяем wTz для всех zР, только после того как все образы были классифицированы.
Если мы делаем настройку после каждого неправильно классифицированного образа (мы называем это "one-at-a-time") процедура функция критерия становится
J(w) = -wTz (3.35)
и
J(w) = -z
Алгоритм обучения будет иметь вид
w(k+1) = w(k) +kz (3.37)
Это правило с фиксированным инкрементом, если k = с (константа).
3.3.3. Релаксационная функция критерия
Функкция критерия, используемая в этом алгоритме, имеет вид
![]()
(3.38)
Р - здесь снова последовательность неправильно классифицированных образов при заданном w. То есть Р состоит из тех z , для которых -wTz +b0
или: wTz b. Градиент Jr(w) по w(k) дает
![]()
(3.39)
Базовый релаксационный обучающий алгоритм формулируется как
![]()
(3.40)
Э![]() то
также "many-at-time"
алгоритм. Соответствующий "one-at-a-time"
алгоритм будет:
то
также "many-at-time"
алгоритм. Соответствующий "one-at-a-time"
алгоритм будет:
(3.41)
который становится алгоритмом частичной коррекции с = k .
3.4. Обучение кусочно-линейных машин
В общем случае не существует теорем сходимости для для обучающих процедур коммитет или других кусочно-линейных машин. Одна процедура, которая часто бывает удовлетворительной приводится ниже. Пусть М=2 и имеется R дискриминантных функций, где R - нечетное. Тогда
![]()
(3.42)
Классификация в коммитет-машине будет затем выполняться согласно
![]() (3.43)
(3.43)
т![]() ак
что
ак
что
(3.44)
г![]() де:
де:
(3.45)
Отметим, что так как R - нечетное, d(z) не может быть равно 0 и будет всегда нечетным. Так как d(z) равно разнице между числом di(z) 0 и di(z) 0 для весового вектора wi (k) для k-ой итерации. В нашем случае мы всегда желаем иметь di(z) 0 . Другими словами мы желаем иметь больше весовых векторов, которые дают di(z) 0 .
Когда di(z) 0, имеет место неправильная классификация. Будет очевидным, что в этом случае будет [ R+d(z) ] / 2 весовых векторов среди wi (k), i=1,2,...,R, которые дают отрицательные ответы [di(z) 0] и [ R-d(z) ] / 2 весовых векторов , которые дают положительные ответы [di(z) 0]. Для получения правильной классификации нам необходимо изменить, по крайней мере n ответов wi (k) от -1 к +1, где n может быть найдено из уравнения:
![]() (3.46)
(3.46)
В первых скобках представлено число di , которое сейчас больше нуля, выражение в скобках после минуса представляет число di , которое меньше нуля. Минимальная величина n тогда будет
nmin = [d(z) + 1] / 2 , (3.47)
которое дает минимальное число векторов, необходимых для настройки.
Процедура для настройки весового вектора:
1) убираем наименьший отрицательный di(z) среди отрицательных di(z) ;
2) настраиваем [d(z) + 1] / 2 весовых векторов по следующему правилу:
wi (k+1) = wi (k) + сz, (3.48)
таким образом, что из результирующие di(z) становятся положительными. Все другие весовые векторы остаются неизменными на этой стадии;
3) если на k-ой стадии машина неправильно классифицирует образ, принадлежащий w2 , делаем классифицирующие коэффициенты с отрицательной величиной, так что
wi (k+1) = wi (k) - сz.
3.5. Практические соображения, касающиеся метода обучения с коррекцией ошибок
Поскольку правила коррекции ошибок никогда не допускают ошибки при классификации шаблонов без коррекции дискриминантной функции, некоторые выборки могут сказаться. Например, для случая двух нормально распределенных классов с перекрытием всегда будет присутствовать ошибка, даже при выборе оптимума в одном из классов. Правило коррекции ошибок будет влиять на оптимум постоянно, он будет меняться и никогда не стабилизируется.
Для случая, когда классы имеют больше чем один «кластер» или «группировок» в шаблонной области, метод обучения с коррекцией ошибок снова сталкивается с проблемами. Решение состоит в добавлении правила остановки. Но это правило остановки должно быть применено соответствующее, иначе система может завершить работу с «бедным» w. Другой метод решения таких проблем состоит в использовании процедур обучения, не являющимися коррекцией ошибок, таких как кластеризация (определение только способов многорежимных проблем), стохастическая аппроксимация, функции потенциалов или процедура нахождения минимума квадратичной ошибки.
3.6. Процедуры минимума квадратичной ошибки
3.6.1. Минимум квадратичной ошибки и псевдоынверсный метод
Допустим, что мы желаем получить равенства
Zw = b (3.50)
вместо неравенств
zw>0. В таком случае нам
нужно решить
![]() линейных уравнений, где N
– общее число прототипов для всех
классов, Ni
– число прототипов для класса i,
а M – общее число классов.
Тогда z и b
могут быть определены так:
линейных уравнений, где N
– общее число прототипов для всех
классов, Ni
– число прототипов для класса i,
а M – общее число классов.
Тогда z и b
могут быть определены так:
( 3.51)
и
3.51)
и
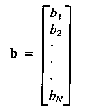
(3.52)
Если матрица Z квадратная и не сингулярная, то мы можем сказать:
w = Z-1b (3.53)
и решить это уравнение для неизвестного w. Но в основном Z – прямоугольная (то есть строк больше, чем столбцов), то есть существует много решения системы Zw=b. Определим вектор ошибок как
и![]()
![]() функцию квадратичного критерия как
функцию квадратичного критерия как
Возьмем частную производную от Js по ws, наблюдаем:
и![]() ли
в матричной форме
ли
в матричной форме
У![]() становка
Js(w)
= 0 дает
становка
Js(w)
= 0 дает
и![]() ли
ли
w = Z#b (3.59)
где Z# = (ZTZ)-1ZT называется псевдоынверсной или обобщенной инверсной матрицей Z. У Z# есть следующие свойства: (1) Z#Z = 1, однако, обычно ZZ# 1 и (2) Z# = Z-1 если Z – квадратная и несингулярная. Значение b в равенстве (3.52) может быть установлено произвольно, учитывая лишь то, что bi > i. Если нет другой информации, хорошим выбором является:
b = [1 1 1 …. 1 ] = uT
На самом деле, если b = uT, то решение минимальной квадратичной ошибки приближается к аппроксимации минимума средней квадратичной ошибки Байесовской дискриминантной функции. Заметим, что данный метод не является коррекцией ошибки, так как здесь не вычисляется новое w для каждого z. На самом деле, все z связаны вместе и нужно только одно решение; таким образом, время обучения очень мало.
3.6.2. Метод Хо-Кашьпа
Когда функциональный критерий J(w) нужно минимизировать не только по w, но и по b (то есть предположить, что b не константа), обучение производится по алгоритму, называемому методом Хо-Кашьпа. Используется тот же функциональный критерий J(w), что и в урванении (3.55), который приведен и ниже:
Ч![]() астные
производные от J(w)
по w и b
приведены ниже:
астные
производные от J(w)
по w и b
приведены ниже:
и![]()
У![]() становка
дJ/дw
= 0 дает
становка
дJ/дw
= 0 дает
w = (ZTZ)-1ZTb = Z#b (3.63)
Так как все компоненты b по определению должны быть положительными, установка b может производиться так:
b(k+1) = b(k) + b(k) (3.64)
где
г![]() де
символами k, i
и c представляются
итерационный индекс, индекс компоненты
вектора и положительный корректирующий
инкремент соответственно. Из равенства
(3.63) имеем:
де
символами k, i
и c представляются
итерационный индекс, индекс компоненты
вектора и положительный корректирующий
инкремент соответственно. Из равенства
(3.63) имеем:
w(k+1) = Z# b(k+1) (3.66)
Объединяя равенства (3.63), (3.64), (3.66), мы получаем:
w(k+1) = w(k) + Z#b(k) (3.67)
Вспоминая, что все компоненты вектора b(k) = (b1, b2, … bN)T положительны, получаем:
w(1) = Z#b(1), b(1)>0 (3.68)
e(k) = Zw(k) – b(k) (3.69)
алгоритм для нахождения весов и выбора b может быть представлен в следующей форме:
![]()