

2.2.Бинарный поиск
Для работы данного метода нужен предварительно отсортированный массив. Этот метод особенно интересен, если исходный массив в ходе программы уже был отсортирован и нужно быстро найти в нем нужное значение, т.к. его работа, по сравнению с методом прямого перебора значительно эффективнее, особенно для больших массивов.
Суть метода заключается в разделении (заранее отсортированного) массива на две равные части, а сравнение искомого значениея происходит с центральным элементом между этими частями. В зависимости от выполнения условия сравнения, например, если искомое значение меньше центрального элемента, то дальнейший поиск будет производиться только в левой части, повторяя аналогичные шаги. Таким образом в результате каждой последующей проверки, мы вдвое сужаем область поиска и т.д.
Таким образом, пример алгоритма бинарного поиска выглядит так:
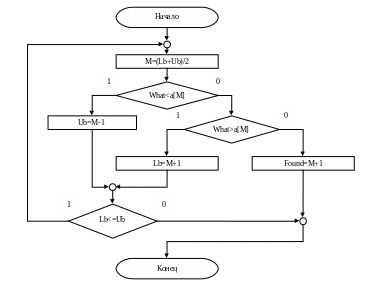
Рис. 2.5. Блок-схема Бинарного поиска
long BinaryFind(long array[], long size, long What)
{
long i;
long M; // вспомогательная переменная для определения принадлежности к тому или иному
// диапазону поиска
long Found = -1; // найденная позиция
short Lb = 0; // нижняя граница диапазона поиска
short Ub = size-1; // верхняя граница диапахона поиска
// цикл поиска бинарным методом
do {
M = (Lb + Ub)/2; //находим середину диапазона поиска
// искомое число находится в первой половине диапазона поиска ?
if (What < array [M])
Ub = M - 1; //если да, то присваиваем новую верхнюю границу нового
//диапазона поиска
else { //если нет, то
//искомое число находится во второй половине диапозона поиска ?
if (What > array[M])
Lb = M + 1; //если да, то присваиваем новую нижнюю границу нового
//диапазона поиска
else { //если нет, т.е. если число совпало с искомым, то ..
Found = M+1; //выводим на экран позицию,
//в которой было найдено искомое число
break; //выходим из цикла поиска
}
}
} while (Lb<=Ub);
return Found;
}
2.3.Интерполяционный поиск
Данный метод рассчитан на поиск в отсортированном массиве. Этот метод очень похож на бинарный по реализации. Алгоритм метода: Если известно, что К лежит между Kl и Ku, то следующую пробу делаем на расстоянии (u-l)(K-Kl)/(Ku-Kl) от l, предполагая, что ключи являются числами, возрастающими приблизительно в арифметической прогрессии.
Если все элементы исходного массива являются (или достаточно близки к ним) членами арифметической прогрессии, то поиск может пройти за одно сравнение. Если не удалось найти нужный ключ с первого раза, то исходный отрезок поиска сужается и делается следующее сравнение с ключом расположенным на новом расстоянии (u-l)(K-Kl)/(Ku-Kl) от l.
Интерполяционный поиск работает за log log N операций, если данные распределены равномерно. Как правило, он используется лишь на очень больших таблицах, причем делается несколько шагов интерполяционного поиска, а затем на малом подмассиве используется бинарный или последовательный варианты.
По описанию метода, получим блок-схему и код ниже:
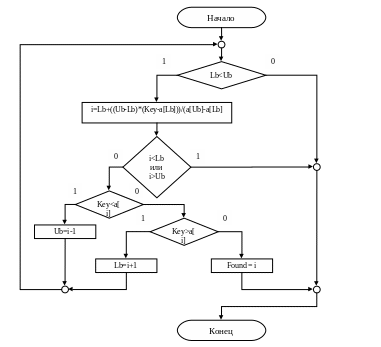
Рис. 2.6. Блок-схема Интерполяционного поиска
long IntFind(long array[], long size, long What)
{
long i;
long Found = -1; // найденная позиция
short Lb = 0; // нижняя граница диапазона поиска
short Ub = size-1; // верхняя граница диапахона поиска
while(Lb<Ub) // если верхняя граница станет меньше нижней, то выйдем из цикла
{
// расстояние следующей пробы от Lb
i = Lb + (double)((Ub - Lb)*(Key - array [Lb])) / (double)(array [Ub] - array [Lb]);
if (i<Lb || i>Ub)
break; // выйдем из цикла, если расчитанное расстояние вышло за рамки
if(Key<array [i]) //если ключ меньше текущей позиции
Ub = i-1; //то устанавливаем новую верхнюю границу
else
if(Key>array [i]) //если ключ больше текущей позиции
Lb=i+1; // то устанавливаем новую нижнюю границу
else { // если не больше и не меньше, т.е. равно
Found = i; // запоминаем, найденную позицию
break; // и выходм из цикла
}
}
return Found;
}