

2. «Информационные сети»
16. Архитектура Token Ring (компоненты, топология, характеристики).
Token Ring — архитектура и технология построения сети, разработанная фирмой IBM, в соответствии с которой включенные в ЛВС станции могут производить передачу данных, только когда они владеют маркером, непрерывно циркулирующим по кольцу.
Топология типичной сети Token Ring - кольцо. Однако в версии IBM это топология «звезда-кольцо»: компьютеры в сети соединяются с центральным концентратором, а маркер передается по логическому кольцу. Физическое кольцо реализуется в концентраторе. Пользователи - часть кольца, но соединяются они с ним через концентратор (Token Ring).
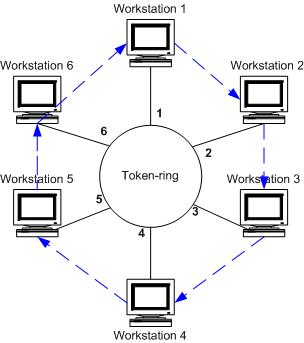
Когда в сети Token Ring начинает работать первый компьютер, сеть генерирует маркер. Маркер проходит по кольцу от компьютера к компьютеру, пока один из них не сообщит о готовности передать данные и не возьмет управление маркером на себя. Маркер - это предопределенная последовательность битов (поток данных), которая позволяет компьютеру отправить данные по кабелю. Когда маркер захвачен каким-либо компьютером, другие компьютеры передавать данные не могут. Захватив маркер, компьютер отправляет кадр данных в сеть. Кадр проходит по кольцу, пока не достигнет узла с адресом, соответствующим адресу приемника в кадре. Компьютер-приемник копирует кадр в буфер приема и делает пометку в поле статуса кадра о получении информации. Кадр продолжает передаваться по кольцу, пока не достигнет отправившего его компьютера, который и удостоверяет, что передача прошла успешно. После этого компьютер изымает кадр из кольца и возвращает туда маркер. В сети одномоментно может передаваться только один маркер, причем только в одном направлении. Передача маркера - детерминистический процесс, это значит, что самостоятельно начать работу в сети (как, например, в среде CSMA/CD) компьютер не может. Он будет передавать данные лишь после получения маркера.
Характеристики:
физическая топология: "звезда";
логическая топология: "кольцо";
метод доступа: с передачей маркера;
кабельная система: экранированная и неэкранированная витая пара (IBM тип 1, 2 или 3);
скорость передачи данных: 4 и 16 Мбит/с;
тип передачи: узкополосная;
Преимущества сетей топологии Token Ring:
- топология обеспечивает равный доступ ко всем рабочим станциям;
- высокая надежность, так как сеть устойчива к неисправностям отдельных станций и к разрывам соединения отдельных станций.
Недостатки сетей топологии Token Ring: большой расход кабеля и соответственно дорогостоящая разводка линий связи.
3. «Управление данными»
16. Методы обработки и оптимизации запросов.
Запрос - это языковое выражение, которое описывающее данные, подлежащие выборке из базы данных. Выполнение запросов – основная функция систем управления базами данных. Качество и стоимость СУБД определяются ее способностью выполнять запросы на больших объемах данных и зависят главным образом от характеристик обработчика запросов.
Обработка запроса - процесс трансляции декларативного определения запроса в операции манипулирования данными низкого уровня.
Оптимизация запроса - это 1) функция СУБД, осуществляющая поиск оптимального плана выполнения запросов из всех возможных для заданного запроса, 2) процесс изменения запроса и/или структуры БД с целью уменьшения использования вычислительных ресурсов при выполнении запроса. Один и тот же результат может быть получен СУБД различными способами (планами выполнения запросов), которые могут существенно отличаться как по затратам ресурсов, так и по времени выполнения. Задача оптимизации заключается в нахождении оптимального способа.
В реляционной СУБД оптимальный план выполнения запроса — это такая последовательность применения операторов реляционной алгебры к исходным и промежуточным отношениям, которое для конкретного текущего состояния БД (её структуры и наполнения) может быть выполнено с минимальным использованием вычислительных ресурсов.
В настоящее время известны две стратегии поиска оптимального плана:
1) грубой силы путём оценки всех перестановок соединяемых таблиц;
2) на основе генетического алгоритма путём оценки ограниченного числа перестановок.
Планы выполнения запроса сравниваются исходя из следующих факторов:
-- потенциальное число строк, извлекаемое из каждой таблицы, получаемое из статистики;
-- наличие индексов;
-- возможность выполнения слияний (merge-join).
В общем случае соединение выполняется вложенными циклами. Однако этот алгоритм может оказаться менее эффективен, чем специализированные алгоритмы.
Стратегии оптимизации.
Стратегия грубой силы.
В теории, при использовании стратегии грубой силы оптимизатор запросов исследует все пространство перестановок всех исходных выбираемых таблиц и сравнивает суммарные оценки стоимости выполнения соединения для каждой перестановки. Для каждой таблицы в каждой из перестановок по статистике оценивается возможность использования индексов. Перестановка с минимальной оценкой и есть итоговый план выполнения запроса.
Стратегия на основе генетического алгоритма
При использовании генетического алгоритма исследуется только часть пространства перестановок. Таблицы, участвующие в запросе, кодируются в хромосомы. Над ними выполняются мутации и скрещивания. На каждой итерации выполняется восстановление хромосом для получения осмысленной перестановки таблиц и отбор хромосом, которые дают минимальные оценки стоимости. В результате отбора остаются только те хромосомы, которые дают меньшее, по сравнению с предыдущей итерацией, значение функции стоимости. Таким образом происходит исследование и нахождение локальных минимумов функции стоимости. Предполагается, что глобальный минимум не дает существенных преимуществ, по сравнению с лучшим локальным минимумом. Алгоритм повторяется несколько итераций, после чего выбирается наиболее эффективное решение.
Оценка альтернативных способов выполнения
Вложенные циклы
В случае вложенных циклов внешний цикл извлекает все строки из внешней таблицы и для каждой найденной строки вызывает внутренний цикл. Внутренний цикл по условиям объединения и данным внешнего цикла ищет строки во внутренней таблице. Циклы могут вкладываться произвольное количество раз. В этом случае внутренний цикл становится внешним для следующего цикла и т. д. При оценке различных порядков выполнения вложенных циклов для минимизации накладных расходов на вызов внутреннего цикла предпочтительнее чтобы внешний цикл сканировал меньшее количество строк, чем внутренний.
Выбор индекса
Для выбора индекса для каждой таблицы прежде всего находятся все потенциальные индексы, которые могут быть применены в исследуемом запросе. Поскольку ключи в индексе упорядочены, то эффективная выборка из него может выполняться только в лексикографическом порядке. В связи с этим, выбор индекса основывается на наличии ограничений для колонок, входящих в индекс, начиная с первой. Для каждой колонки, входящей в индекс, начиная с первой, ищутся ограничения из всего набора ограничений для данной таблицы, включая условия соединений. Если для первой колонки индекса не может быть найдено ни одного ограничения, то индекс не используется (в противном случае пришлось бы сканировать индекс целиком). Если для очередной колонки ограничений не может быть найдено, то поиск завершается и индекс принимается.
Слияние
Если объединяемые таблицы имеют индексы по сравниваемым полям, или одна или обе таблицы достаточно малы, чтобы быть отсортированными в памяти, то объединение может быть выполнено с помощью слияния. Оба отсортированных набора данных сканируются и в них ищутся одинаковые значения. За счёт сортировки слияние эффективнее вложенных циклов на больших объёмах данных, но план выполнения не может начинаться со слияния.
Оценка числа извлекаемых строк
Оценка числа извлекаемых из таблицы строк используется для принятия решения о полном сканировании таблицы вместо доступа по индексу. Решение принимается на том основании, что каждое чтение листовой страницы индекса с диска влечет за собой 1 или более позиционирований и 1 или более чтений страниц таблицы. Поскольку индекс содержит ещё и нелистовые страницы, то извлечение более 0.1-1 % строк из таблицы, как правило, эффективней выполнять полным сканированием таблицы.
Оптимизация параллельных сортировок
Если СУБД запущена на нескольких процессорах, то для уменьшения времени ответа сортировки могут выполняться параллельно. Необходимым условием для этого является возможность поместить все извлекаемые данные в оперативную память. Для выполнения сортировки извлекаемые данные разделяются на фрагменты, число которых равно числу процессоров. Каждый из процессоров выполняет сортировку над одним из фрагментов независимо от других. На финальном шаге выполняется слияние отсортированных фрагментов, либо слияние совмещается с выдачей данных клиенту СУБД. Если СУБД запущена на нескольких узлах, то сортировка параллельно выполняется каждым из узлов, вовлеченных в выполнение запроса. Затем каждый из узлов отправляет свой фрагмент узлу, отвечающему за выдачу данных клиенту, где выполняется слияние полученных фрагментов.