

7 Проектирование структуры и реализация логики управления файловой системы
Файловая система спроектирована на основе FAT. Однако основное отличие в том, что так как данная система применяется только в целях эмуляции, упразднено понятие сектора. Основной единицей является кластер.
Основные структуры данных, которые используются:
Boot-сектор (Boot-кластер)
FAT-таблица
Структура данных для описания структуры каталога
7.1 Описание структур
Boot-кластер
typedef unsigned long int my_size;
typedef unsigned int fat_inf;
class CBootCluster:public CAbstractCluster
{
public:
my_size size, //размер диска (кб)
clust, //размер кластера (кб)
fat, //кол-во ФАТ
root, //кол-во кластеров на описание корневого каталога
clust_in_fat, //кол-во кластеров в ФАТ
counter, //последнее значение счетчика
first_usable_cluster, //первый используемый кластер
clustnum; //кол-во кластеров
CBootCluster(fstream& f)
{
LoadCluster(f);
}
…………………………………………………………….
};
FAT-таблица
class CFatCluster:public CAbstractCluster
{
public:
struct fat_rec //одна запись
{
fat_inf file_ID;//ID файла, записанного в данном кластере
my_size next;//ссылка на следующий кластер с продолжением файла
………………………………….
};
fat_rec* fat_sheet;//фат-таблица (массив записей)
my_size fat_size;//размер таблицы
my_size fat_real_size;//действительный размер (кол-во кластеров умноженное на размер кластера)
…………………………………
};
Структура данных для описания структуры каталога
class CDirectoryCluster:public CAbstractCluster
{
public:
struct CDirRecord//запись о структурной единице
{
bool isFree;//свободна или занята запись
char Name[12];//имя файла
int ID;//ID файла
my_size FirstClust;//первый кластер
…………………………………………
};
int NumFiles;//кол-во файлов
CDirRecord* DirFiles;//таблица файлов
………………………………..
};
7.2 Описание команд
FSemulator.exe FSfname.im /CREATE /SIZE:600 /CLUST:4 /ROOT:2 /FAT:1
создание DOS-подобной ф.с. (на основе FAT) в файле образа с именем “FSfname.im“ общим размером 600kB, размером кластера 4 kB, 1 копией FAT и корневым директорием размером 2 кластера.
получение информации о структуре и состоянии ф.с. , находящейся в файле образа.
FSemulator.exe Fsfname.im /INFO
копирование файлов
копирование файлов в образ ф.с.
FSemulator.exe Fsfname.im /COPYTO SRCfname DSTfname
где
Fsfname.im – имя файла-образа
SRCfname – имя файла-источника на диске
DSTfname – имя файла-приемника в образе ф.с.
копирование файлов из образа ф.с.
FSemulator.exe Fsfname.im /COPYFROM SRCfname DSTfname
где
Fsfname.im – имя файла-образа
SRCfname – имя файла-источника в образе ф.с.
DSTfname – имя файла-приемника на диске
удаление файла из ф.с.
FSemulator.exe Fsfname.im /DEL fname
вывод списка файлов ф.с.
FSemulator.exe Fsfname.im /DIR
вывод кол-ва байт, потраченных на «хвосты» файлов
FSemulator.exe Fsfname.im /WASTE
8 Общее описание функционирования ос
Операционная система использует простую организацию процессов, за работой которой может следить пользователь. ОС работает в соответствии с моделью, изображенной на рис. 1, согласно которой большинство программ операционной системы выполняется в среде пользовательских процессов. Таким образом, в данной ОС требуются оба режима — пользовательский режим и режим ядра. Также здесь используются две категории процессов: системные и пользовательские. Системные процессы выполняют код операционной системы в режиме ядра, осуществляя различные административные функции, такие, как выделение памяти или свопинг процессов. Пользовательские процессы выполняют код пользовательских программ, как в пользовательском режиме, а код операционной системы — в режиме ядра. Пользовательский процесс переключается в режим ядра при вызове системной функции, генерации исключения или при обработке прерывания.
8.1 Состояния процессов
Всего в данной операционной системе распознается девять состояний процессов, перечисленных в табл. 1; соответствующая диаграмма переходов состояний показана на рис. 1.
Таблица 1 - Состояния процессов
Процесс |
Описание |
Выполняющийся пользовательский |
Выполняющийся в пользовательском режиме |
Выполняющийся ядра |
Выполняющийся в режиме ядра |
Готов к выполнению, загруженный |
Готов к выполнению, как только ядро решит передать ему управление |
Спящий, загруженный |
Не может выполняться, пока не произойдёт некоторое событие; процесс находится в основной памяти (блокированное состояние) |
Готовый к выполнению, выгруженный |
Процесс готов к выполнению, но прежде чем ядро сможет спланировать его запуск, процесс свопинга должен загрузить это процесс в основную память |
Спящий, выгруженный |
Процесс ожидает некоторого события; он выгружен из основной памяти (блокированное состояние) |
Вытесненный |
В момент переключения процессора из режима ядра в пользовательский режим ядро решает передать управление другому процессу |
Созданный |
Процесс только что создан и ещё не готов к выполнению |
Зомби |
Самого процесса больше не существует, но записи о нём остались с тем, чтобы ими мог воспользоваться родительский процесс |
Для отражения того факта, что процесс может выполняться как в пользовательском режиме, так и в режиме ядра, в диаграмме имеется два состояния выполняющихся процессов.
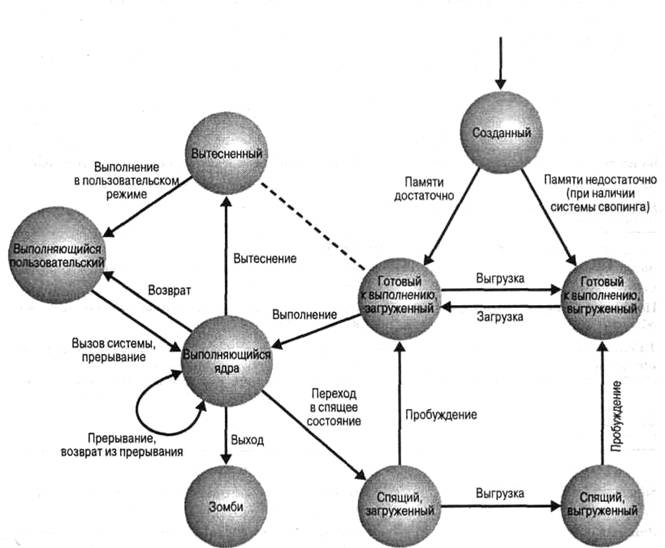
Рисунок 1 - Диаграмма переходов состояний процессов
Состояния вытесненных и загруженных в память и готовых к выполнению процессов отличаются друг от друга. По сути эти два состояния почти одинаковы (на что указывает соединяющая их пунктирная линия). Различие же делается, чтобы подчеркнуть, каким именно образом процесс может быть прерван в пользу другого. Если процесс выполняется в режиме ядра (в результате вызова диспетчера, прерывания по таймеру или прерывания по команде ввода-вывода), рано или поздно наступает момент, когда ядро завершает свою работу и готово возвратить управление пользовательской программе. В это время ядро может принять решение передать управление процессу с более высоким приоритетом, чем у выполнявшегося до этого. В таком случае текущий процесс переходит в состояние вытесненного, но с точки зрения диспетчеризации эти процессы одинаковы. Процесс, прерванный в пользу другого, и находящийся в состоянии готовности к выполнению, находятся в одной очереди.
Такое вытеснение процесса может произойти только в момент переключения режима выполнения из режима ядра в пользовательский режим. При выполнении процесса в режиме ядра он не может быть вытеснен, поэтому операционная система не приспособлена для работы в режиме реального времени.
В данной операционной системе есть два процесса: процесс 0 — это специальный процесс, который создается при загрузке системы. В сущности, он предопределен как структура данных, которая загружается вместе с системой. Этот процесс является процессом свопинга. Кроме того, процесс 0 порождает процесс 1, который называется инициализирующим процессом (init process). Этот процесс является родительским по отношению ко всем остальным. Когда в систему входит новый интерактивный пользователь, именно процесс 1 создает новый процесс для этого пользователя. Далее пользовательский процесс может создавать ветвящиеся дочерние процессы. Таким образом, каждое приложение может состоять из ряда взаимосвязанных процессов.
8.2 Описание процессов
В данной операционной системе процессы представлены структурами данных, которые предоставляют операционной системе всю необходимую для управления и диспетчеризации процессов информацию. В табл. 2 приведены элементы образа процесса, разделенные на три части: контекст пользовательского уровня, контекст регистров и контекст системного уровня.
Таблица 2 - Образ процесса
Элементы |
Описание |
Совместно используемая память |
Область памяти, используемая совместно с другими процессами; применяется для обмена информацией между процессами |
Контекст регистров |
|
Счётчик команд |
Адрес очередной команды, которая будет выполняться, она может находиться как в пользовательском пространстве, так и в пространстве ядра |
Регистр состояния процессора |
Содержит данные по состоянию аппаратного обеспечения в момент передачи управления; содержимое и формат этих данных зависят от конкретного аппаратного обеспечения |
Указатель стека |
Указывает положение вершины стека ядра (или пользовательского стека, в зависимости от режима работы процессора) |
Регистры общего назначения |
Зависят от используемого аппаратного обеспечения |
Контекст системного уровня |
|
Запись таблицы процессов |
Определяет состояние процесса; эта информация всегда доступна операционной системе |
Пользовательская область |
Информация по управлению процессом, необходимая только в контексте данного процесса |
Таблица областей процесса |
Задаёт отображение виртуальных адресов в физические; содержит также поле полномочий, в котором указывается тип доступа, на который процесс имеет право: только для чтения, для чтения и записи или для записи и выполнения |
Стек ядра |
Содержит кадр стека процедур ядра при работе процесса в режиме ядра |
В контекст пользовательского уровня (user-level context) входят основные элементы пользовательских программ; он может генерироваться непосредственно из скомпилированных объектных файлов. Каждая пользовательская программа разделена на две части, одна из которых размещается в текстовой области, а другая — в области данных. Текстовая область предназначена только для чтения; в ней хранятся команды пользовательских программ. Во время выполнения процессор использует пользовательский стек для вызовов и возвратов из процедур, а также для передачи параметров. Совместно используемая область памяти — это область данных, доступ к которой одновременно предоставляется различным процессам. Хотя в системе имеется только одна физическая копия совместно используемой области памяти, при использовании виртуальной памяти эта область находится в адресном пространстве каждого процесса, который ее использует.
Когда процесс не выполняется, соответствующая информация по состоянию процессора хранится в области контекста регистров (register context).
В контексте системного уровня (system-level context) находится остальная информация, которая нужна операционной системе для управления процессом. Эта информация состоит из статической части фиксированного размера, который остается неизменным на протяжении всего времени жизни процесса, и динамической части, размер которой меняется. Одним из компонентов статической части является запись таблицы процессов, которая фактически является частью таблицы процессов, поддерживаемой операционной системой, в которой каждому процессу соответствует одна запись. Запись таблицы процессов содержит информацию по управлению процессом, доступную ядру в любой момент времени. Таким образом, в системе виртуальной памяти все записи таблицы процессов постоянно остаются в основной памяти. В табл. 3 перечислены компоненты записи таблицы процессов. Пользовательская область содержит дополнительную управляющую информацию, которая нужна ядру при работе в контексте этого процесса; эта информация используется также при загрузке и выгрузке страниц процесса из основной памяти. В табл. 4 приведено содержимое этой таблицы.
Таблица 3 - Элемент таблицы процессов
Элемент таблицы процессов |
Описание |
Состояние процесса |
Текущее состояние процесса |
Указатели |
Пользовательская область и область памяти процесса (текст, данные, стек) |
Размер процесса |
Даёт возможность операционной системе определить, сколько памяти потребуется процессу |
Идентификаторы пользователя |
Реальный идентификатор пользователя (real user ID) указывает, кто из пользователей несёт ответственность за выполняющийся процесс. Фактический идентификатор пользователя (effective user ID) может использоваться процессом для предоставления временных привилегий, связанных с определённой программой; на время выполнения этой программы в составе процесса последний использует фактический идентификатор пользователя |
Идентификаторы процесса |
Идентификатор данного и родительского процессов. Эти идентификаторы присваиваются процессу в состоянии создания |
Дескриптор событий |
Используется, когда процесс находится в спящем состоянии; с наступлением события процесс переходит в состояние готовности |
Приоритет |
Используется при планировании процессов |
Сигнал |
Перечисляет отправленные, но ещё не обработанные сигналы |
Таймеры |
Включают время выполнения процесса, использование ресурсов ядром, а также пользовательские таймеры для отправки сигналов в определённое время |
Р-связь |
Указатель на следующий элемент в очереди готовых к выполнению процессов (используется, когда процесс находится в состоянии готовности) |
Статус памяти |
Указывает, находится ли образ процесса в основной памяти или выгружен из неё. Если процесс загружен в память, в этом поле также указывается, можно ли его выгрузить или он временно блокирован в основной памяти |
Таблица 4 - Пользовательская область операционной системы
Информация |
Описание |
Указатель таблицы процесса |
Указывает запись, соответствующую области пользователя |
Идентификаторы пользователя |
Реальный и фактический идентификаторы пользователя. Используются для определения пользовательских привилегий |
Таймеры |
Записывают время, затраченное на выполнение данного и дочерних процессов в пользовательском режиме и в режиме ядра |
Массив обработчиков сигналов |
Указывает, как будет реагировать процесс на каждый из пяти типов сигналов, заданных в системе (выходить из системы, игнорировать сигнал, выполнять заданную пользователем функцию) |
Различия между записью таблицы процессов и пользовательской областью отражают тот факт, что ядро данной операционной системы всегда выполняется в контексте какого-нибудь процесса. Большую часть времени ядро работает с контекстом текущего процесса, однако иногда ядру нужен доступ к информации и о других процессах, например при работе планировщика.
Третьей статической частью, входящей в контекст системного уровня, является таблица областей процесса, которая используется системой управления памятью. И, наконец, стек ядра — это динамическая часть контекста системного уровня. Этот стек используется при выполнении процесса в режиме ядра и содержит информацию, которую нужно сохранять и восстанавливать во время вызовов процедур и прерываний.
8.3 Управление процессами
В данной операционной системе процессы создаются с помощью вызова системной функции ядра под названием fork (). При вызове этой функции процессом операционная система выполняет следующие действия.
Выделяет в таблице процессов место для нового процесса.
Назначает этому процессу уникальный идентификатор.
Создает копию образа родительского процесса, за исключением совместно используемых областей памяти.
Увеличивает показания счетчиков всех файлов, принадлежащих родительскому процессу, что отражает тот факт, что новый процесс также владеет этими файлами.
Назначает процессу состояние готовности к выполнению.
Возвращает родительскому процессу идентификатор дочернего процесса, а дочернему процессу — значение 0.
Все перечисленные выше действия выполняются в рамках родительского процесса в режиме ядра. После того как ядро закончит выполнение этих функций, оно может перейти к выполнению одного из следующих действий как части программы диспетчера.
Оставаясь в рамках родительского процесса, переключить процессор в пользовательский режим; процесс будет продолжен с той команды, которая следует после вызова функции fork().
Передать управление дочернему процессу. Дочерний процесс начинает выполняться с того же места кода, что и родительский: с точки возврата после вызова функции fork ().
Передать управление другому процессу. При этом и родительский и дочерний процессы переходят в состояние готовности к выполнению.
Возможно, такой метод создания процессов трудно изобразить наглядно, потому что и родительский и дочерний процессы в момент создания выполняют один и тот же проход по коду. Различаются они возвращаемым функцией fork () значением: если оно равно нулю, то это дочерний процесс. Таким образом, можно выполнить команду ветвления, которая приведет к выполнению дочерней программы или продолжению выполнения основной ветви.
В каждой записи таблицы процессов есть поле приоритета, используемое планировщиком процессов. Приоритет процесса в режиме задачи зависит от того, как этот процесс перед этим использовал ресурсы ЦП. Можно выделить два класса приоритетов процесса (Рисунок 2): приоритеты выполнения в режиме ядра и приоритеты выполнения в режиме задачи. Каждый класс включает в себя ряд значений, с каждым значением логически ассоциирована некоторая очередь процессов. Приоритеты выполнения в режиме задачи оцениваются для процессов, выгруженных по возвращении из режима ядра в режим задачи. Приоритеты выполнения в режиме задачи имеют верхнее пороговое значение, приоритеты выполнения в режиме ядра имеют нижнее пороговое значение. Среди приоритетов выполнения в режиме ядра далее можно выделить высокие и низкие приоритеты: процессы с низким приоритетом возобновляются по получении сигнала, а процессы с высоким приоритетом продолжают оставаться в состоянии приостанова.
Ядро стремится производить пересчет приоритетов всех активных процессов ежесекундно, однако интервал между моментами пересчета может слегка варьироваться. Если прерывание по таймеру поступило тогда, когда ядро исполняло критический отрезок программы (другими словами, в то время, когда приоритет работы ЦП был повышен, но, очевидно, не настолько, чтобы воспрепятствовать прерыванию данного типа), ядро не пересчитывает приоритеты, иначе ему пришлось бы надолго задержаться на критическом отрезке. Вместо этого ядро запоминает то, что ему следует произвести пересчет приоритетов, и делает это при первом же прерывании по таймеру, поступающем после снижения приоритета работы ЦП. Периодический пересчет приоритета процессов гарантирует проведение стратегии планирования, основанной на использовании кольцевого списка процессов, выполняющихся в режиме задачи. При этом, конечно же, ядро откликается на интерактивные запросы таких программ, как текстовые редакторы или программы форматного ввода: процессы, их реализующие, имеют высокий коэффициент простоя (отношение времени простоя к продолжительности использования ЦП) и поэтому естественно было бы повышать их приоритет, когда они готовы для выполнения. В других механизмах планирования квант времени, выделяемый процессу на работу с ресурсами ЦП, динамически изменяется в интервале между 0 и 1 сек. в зависимости от степени загрузки системы. При этом время реакции на запросы процессов может сократиться за счет того, что на ожидание момента запуска процессам уже не нужно отводить по целой секунде; однако, с другой стороны, ядру приходится чаще прибегать к переключению контекстов.
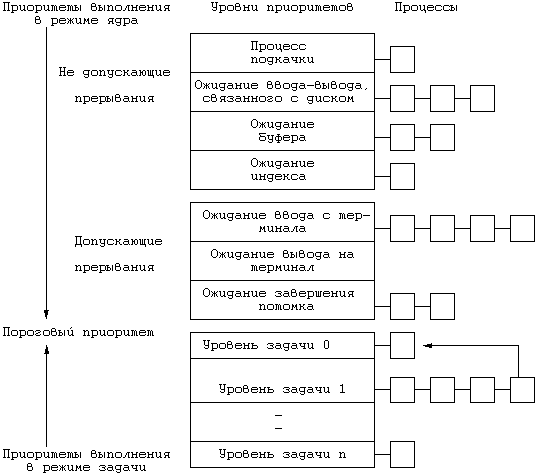
Рисунок 2 - Переход процесса из одной очереди в другую
Ядро вычисляет приоритет процесса в следующих случаях:
- непосредственно перед переходом процесса в состояние приостанова ядро назначает ему приоритет исходя из причины приостанова. Приоритет не зависит от динамических характеристик процесса (продолжительности ввода-вывода или времени счета), напротив, это постоянная величина, жестко устанавливаемая в момент приостанова и зависящая только от причины перехода процесса в данное состояние. Процессы, приостановленные алгоритмами низкого уровня, имеют тенденцию порождать тем больше узких мест в системе, чем дольше они находятся в этом состоянии; поэтому им назначается более высокий приоритет по сравнению с остальными процессами. Например, процесс, приостановленный в ожидании завершения ввода-вывода, связанного с диском, имеет более высокий приоритет по сравнению с процессом, ожидающим освобождения буфера, по нескольким причинам. Прежде всего, у первого процесса уже есть буфер, поэтому не исключена возможность, что когда он возобновится, он успеет освободить и буфер, и другие ресурсы. Чем больше ресурсов свободно, тем меньше шансов для возникновения взаимной блокировки процессов. Системе не придется часто переключать контекст, благодаря чему сократится время реакции процесса и увеличится производительность системы. Во-вторых, буфер, освобождения которого ожидает процесс, может быть занят процессом, ожидающим в свою очередь завершения ввода-вывода. По завершении ввода-вывода будут возобновлены оба процесса, поскольку они были приостановлены по одному и тому же адресу. Если первым запустить на выполнение процесс, ожидающий освобождения буфера, он в любом случае снова приостановится до тех пор, пока буфер не будет освобожден; следовательно, его приоритет должен быть ниже.
- по возвращении процесса из режима ядра в режим задачи ядро вновь вычисляет приоритет процесса. Процесс мог до этого находиться в состоянии приостанова, изменив свой приоритет на приоритет выполнения в режиме ядра, поэтому при переходе процесса из режима ядра в режим задачи ему должен быть возвращен приоритет выполнения в режиме задачи. Кроме того, ядро "штрафует" выполняющийся процесс в пользу остальных процессов, отбирая используемые им ценные системные ресурсы.
- приоритеты всех процессов в режиме задачи с интервалом в 1 секунду пересчитывает программа обработки прерываний по таймеру, побуждая тем самым ядро выполнять алгоритм планирования, чтобы не допустить монопольного использования ресурсов ЦП одним процессом.
8.4 Общая структура проектируемой ОС
Структуру проектируемой ОС можно представить в виде трехуровневой модели, где верхний уровень пользовательский интерфейс, средний уровень - ядро системы, к которому можно включить подсистемы управления памятью и процессами, подсистему управления устройствами и файловую подсистему. Третий уровень - это непосредственно оборудования. Подробная схема проектируемой ОС представлена на рисунке 3.
Пользовательский интерфейс предназначен для работы операционной системы с пользователем. На него возлагаются все внешние команды для работы с файловой системой, процессами и устройствами. То есть уровень пользователя является внешней оболочкой проектируемой операционной системы. На уровне пользователя находится графическая оболочка и интерпретатор.
Ядро - это сердце ОС. Ядро реализует основные системные вызовы управления процессами и оперативной памятью, а также функции обмена информацией с внешними устройствами на физическом уровне (драйверы).
Условно ядро можно разделить на следующие составляющие:
управление процессами, распределение ресурсов системы;
управление стандартными устройствами ввода и вывода;
управление памятью, обеспечение выделения и освобождения памяти
управление ФС, обеспечения обмена данными с диском.
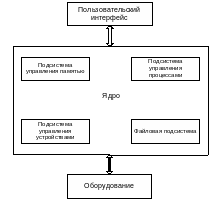
Рисунок 3 – Структура проектируемой ОС
Уровень оборудования представляет собой собственно саму аппаратуру, на которой функционирует ОС.
ВЫВОДЫ
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ
Ахо Альфред, Сети Рави, Ульман Джеффри Компиляторы: принципы, технологии и инструменты: [пер. с англ.] – М.: Вильямс, 2001. – 768с.ил.
Вильямс А. Системное программирование в Windows 2000 для профессионалов – СПб: Питер, 2001. – 624 с., ил.
Ивановский С. Операционная система. – М.: Познавательная книга плюс, 2000. - 512 с.
Мешков А., Тихонов Ю. Visual C++ и MFC. Программирование для Windows NT и Windows 95: в 3 т. – СПб.: BHV- Санкт-Петербург,1997. – Т.1. – 464 с., ил.
Минаси М., Камарда Б. и др. OS/2 Warp изнутри; [пер. с анг.] – СПб: Питер,1996. – Т.1. – 528 с.
Немнюгин С., Чаунин М., Кололкин А. Эффективная работа: UNIX. – СПб.: Питер,2001 – 688 с., ил.
Олифер Н. А., Олифер В. Г. Компьютерные сети. Принципы, технологии, протоколы: Учебник для вузов, 4-е изд. – СПб.: Питер, 2011. – 944 с., ил.
Олифер Н. А., Олифер В. Г. Сетевые операционные системы – СПб.: Питер, 2007. – 864 с., ил.
Таненбаум Э. Современные операционные системы. 3-е изд. – СПб.: Питер, 2010. – 1120 с., ил.
Харт, Джонсон М. Системное программное обеспечение в среде Windows; [пер.с англ.] – М.: Вильямс, 2005. – 592 с., ил.
П риложение
А
риложение
А
ТЕХНИЧЕСКОЕ ЗАДАНИЕ
А.1 Общие сведения
Название проекта: «Проектирование операционной системы с заданными характеристиками».
Программный продукт проектируется студенткой 3-го курса Донецкого национального технического университета, факультета Институт информатики и искусственного интеллекта, группы ПОС-09б, Магдайчук Екатериной Александровной.
Основанием для разработки данного проекта является задание, выданное кафедрой Программного обеспечения интеллектуальных систем (ПОИС) ИиИИ ВУЗ ДонНТУ.
Дата выдачи задания: 26.01.2012
Срок сдачи проекта: 18.04.2012
А.2 Назначение и цели создания проекта
Целью создания проекта является приобретение практических навыков проектирования операционных систем и комплексного инженерного проектирования программного обеспечения. Проект предназначен для демонстрации работы алгоритмов, связанных с операционными системами.
Проектируемая операционная система может быть использована в учебных заведениях в качестве наглядного пособия при обучении приемам и правилам построения интерактивной операционной системы.
А.3 Требования к КП
Необходимо спроектировать компьютерную операционную систему.
А.3.1 Требования к задачам КП
В КП должны быть решены следующие задачи:
Сформулировать цели проектирования ОС.
Провести анализ требований к системе и выбрать способ их реализации.
Разработать архитектуру аппаратных средств компьютера для реализации ОС.
Определить состав и общую структуру ОС: перечень и внешние спецификации модулей.
Разработать интерфейс пользователя (командный язык архитектуры ОС: интерактивные команды ОС; системные вызовы; язык пакетных файлов).
Спроектировать базу данных ОС: перечень и описание управляющих блоков и очередей.
Описать общее функционирования ОС:
состояние процесса;
схему работы ядра ОС;
алгоритмы управления процессами для реализации многозадачности и средств взаимодействия процессов.
Спроектировать структуру и реализовать логику управления заданной файловой системы.
Выполнить оценку работоспособности системы и ее эксплуатационных характеристик.
Сформулировать выводы по результатам проектирования.
А.3.2 Требования к функциональности КП
Разрабатываемый в рамках данного проекта программный продукт должен удовлетворять следующим требованиям к его функциональности:
реализация особенностей аппаратных платформ: персональные компьютеры;
реализация особенностей алгоритмов управления ресурсами: многозадачные, многопользовательские, невытесняющая многозадачность и многопроцессорная обработка;
реализация особенности областей использования: системы пакетной обработки и системы разделения времени;
организация оперативной памяти: без использования внешней памяти: фиксированными разделами;
выполнение средств взаимодействия процессов: события(events);
управление процессами: свопинг процессов;
выполнение организации файловой системы: MS DOS.
А.3.3 Требования к видам обеспечения
А.3.3.1 Требования к программному обеспечению
Программный продукт должен проектироваться как операционная система.
При разработке проекта должен использоваться объектно-ориентированный язык программирования С++.
А.3.3.2 Требования к техническому обеспечению
К техническому обеспечению предъявляются следующие требования:
Процессор с тактовой частотой 1000 MHz и выше, системой команд, включающей команды микропроцессора Pentium.
Объём оперативной памяти 1 Гб.
Клавиатура.
Мышь.
А.3.3.3 Требования к организационному обеспечению
Организационным обеспечением по данному проекту составляет пояснительная записка. Она должна включать в себя следующие элементы:
Техническое задание на курсовой проект.
Руководство пользователя.
Экранные формы.
Листинг программы.
А.4 Порядок защиты проекта
При защите проекта должны соблюдаться следующие требования:
Защита проекта проводится в присутствии соответствующей приемной комиссии.
Для защиты проекта необходимо в оговоренные сроки представить:
задание на курсовой проект;
пояснительную записку на курсовой проект;
исполняемый файл программы.
А.5 Сроки выполнения курсового проекта
Стадии и этапы разработки КП представлены в таблице 5.1.
Таблица А.5.1 - Стадии и этапы разработки КП
№ |
Этапы работы |
Срок выполнения |
1 |
Выбор исходных элементов из классификатора для изучение проектного решения. |
|
2 |
Разработка архитектуры аппаратных средств компьютера для реализации ОС |
2-3 недели |
3 |
Разработка интерфейса пользователя (командного языка) |
3-4 недели |
4 |
Проектирование основных структур данных и базы данных ОС |
5-8 недели |
5 |
Программирование и отладка средства взаимодействия процессов |
9-10 недели |
6 |
Программирование и отладка логики управления файловой системы |
11-12 недели |
7 |
Написание программной документации и оформление пояснительной записки |
13 неделя |
8 |
Защита КП. |
14 неделя |
П риложение Б
ЛИСТИНГ 1
#include <windows.h>
#include <math.h>
#include <stdio.h>
HANDLE T1,T2,T3,T4,T5,T6,T7,T8,T;
HANDLE hQuit=NULL;
HANDLE hEv[8],hFl;
FILE *log_file;
DWORD id1,id2,id3,id4,id5,id6,id7,id8,id;
double res,rez[8];
const int VAR=35;
/******************************************/
double IT(double arg){
double step=arg/100,res=0,left,right;
for(double x = -arg; x<arg; x+=step){
left=fabs(cos(x)*sin(x));
right=fabs(cos(x+step)*sin(x+step));
res+=(left+right)*step/2;
}
return res;
}
/******************************************/
double IR(double arg){
double step=arg/100,res=0,right;
for(double x = -arg; x<arg; x+=step){
right=(double)fabs(cos(x+step));
res+=right*step;
}
return res;
}
/******************************************/
double SC(double arg)
{
double res=0;
for (double i=0;i<fabs(arg);i++) res+=fabs(cos(i));
return res;
}
/******************************************/
DWORD WINAPI t1(LPVOID){
WaitForSingleObject(hFl, INFINITE);
ResetEvent(hFl);
fprintf(log_file, "1 поток создан.\n");
SetEvent(hFl);
rez[0]=SC(VAR*1);
MessageBox(NULL,"1 поток завершен","",MB_OK);
WaitForSingleObject(hFl, INFINITE);
ResetEvent(hFl);
fprintf(log_file,"1 поток завершен. Результат: %f\n",rez[0]);
SetEvent(hFl);
SetEvent(hEv[0]);
return 0;
}
/******************************************/
DWORD WINAPI t2(LPVOID){
WaitForSingleObject(hFl, INFINITE);
ResetEvent(hFl);
fprintf(log_file, "2 поток создан.\n");
//EnterCriticalSection
SetEvent(hFl);
rez[1]=IT(VAR*2);
MessageBox(NULL,"2 поток завершен","",MB_OK);
WaitForSingleObject(hFl, INFINITE);
ResetEvent(hFl);
fprintf(log_file,"2 поток завершен. Результат: %f\n",rez[1]);
SetEvent(hFl);
SetEvent(hEv[1]);
return 0;
}
/******************************************/
DWORD WINAPI t3(LPVOID){
WaitForSingleObject(hFl, INFINITE);
ResetEvent(hFl);
fprintf(log_file, "3 поток создан.\n");
SetEvent(hFl);
rez[2]=IT(VAR*3);
MessageBox(NULL,"3 поток завершен","",MB_OK);
WaitForSingleObject(hFl, INFINITE);
ResetEvent(hFl);
fprintf(log_file,"3 поток завершен. Результат: %f\n",rez[2]);
SetEvent(hFl);
SetEvent(hEv[2]);
return 0;
}
/******************************************/
DWORD WINAPI t4(LPVOID){
WaitForSingleObject(hFl, INFINITE);
WaitForSingleObject(hEv[2], INFINITE);
ResetEvent(hFl);
fprintf(log_file, "4 поток создан.\n");
SetEvent(hFl);
rez[3]= SC(rez[2]*VAR*4);
MessageBox(NULL,"4 поток завершен","",MB_OK);
WaitForSingleObject(hFl, INFINITE);
ResetEvent(hFl);
fprintf(log_file,"4 поток завершен. Результат: %f\n",rez[3]);
SetEvent(hFl);
SetEvent(hEv[3]);
return 0;
}
/******************************************/
DWORD WINAPI t5(LPVOID){
WaitForSingleObject(hFl, INFINITE);
WaitForSingleObject(hEv[2], INFINITE);
ResetEvent(hFl);
fprintf(log_file, "5 поток создан.\n");
SetEvent(hFl);
rez[4]= IR(rez[2]*VAR*5);
MessageBox(NULL,"5 поток завершен","",MB_OK);
WaitForSingleObject(hFl, INFINITE);
ResetEvent(hFl);
fprintf(log_file,"5 поток завершен. Результат: %f\n",rez[4]);
SetEvent(hFl);
SetEvent(hEv[4]);
return 0;
}
/******************************************/
DWORD WINAPI t6(LPVOID){
WaitForSingleObject(hFl, INFINITE);
WaitForSingleObject(hEv[2], INFINITE);
ResetEvent(hFl);
fprintf(log_file, "6 поток создан.\n");
SetEvent(hFl);
rez[5]= IT(rez[2]*VAR*6);
MessageBox(NULL,"6 поток завершен","",MB_OK);
WaitForSingleObject(hFl, INFINITE);
ResetEvent(hFl);
fprintf(log_file,"6 поток завершен. Результат: %f\n",rez[5]);
SetEvent(hFl);
SetEvent(hEv[5]);
return 0;
}
/******************************************/
DWORD WINAPI t7(LPVOID){
WaitForSingleObject(hEv[0], INFINITE);
// WaitForSingleObject(hEv[1], INFINITE);
// WaitForSingleObject(hEv[5], INFINITE);
WaitForSingleObject(hFl, INFINITE);
ResetEvent(hFl);
fprintf(log_file, "7 поток создан.\n");
SetEvent(hFl);
rez[6]= IT(rez[0]*VAR*7);
MessageBox(NULL,"7 поток завершен","",MB_OK);
WaitForSingleObject(hFl, INFINITE);
ResetEvent(hFl);
fprintf(log_file,"7 поток завершен. Результат: %f\n",rez[6]);
SetEvent(hFl);
SetEvent(hEv[6]);
return 0;
}
/******************************************/
DWORD WINAPI t8(LPVOID){
WaitForSingleObject(hEv[3], INFINITE);
WaitForSingleObject(hEv[4], INFINITE);
WaitForSingleObject(hEv[5], INFINITE);
WaitForSingleObject(hFl, INFINITE);
ResetEvent(hFl);
fprintf(log_file, "8 поток создан.\n");
SetEvent(hFl);
rez[7]= IT((rez[3]+rez[4]+rez[5])*VAR*8);
MessageBox(NULL,"8 поток завершен","",MB_OK);
WaitForSingleObject(hFl, INFINITE);
ResetEvent(hFl);
fprintf(log_file,"8 поток завершен. Результат: %f\n",rez[7]);
SetEvent(hFl);
SetEvent(hEv[7]);
return 0;
}
/******************************************/
DWORD WINAPI t(LPVOID){
WaitForSingleObject(hEv[1], INFINITE);
WaitForSingleObject(hEv[6], INFINITE);
WaitForSingleObject(hEv[7], INFINITE);
WaitForSingleObject(hFl, INFINITE);
res=(rez[1]+rez[6]+rez[7])*VAR*9;
return 0;
}
/******************************************/
int WINAPI WinMain(HINSTANCE hInstance,
HINSTANCE hPrevInstance,
LPSTR lpCmdLine,
int nCmdShow)
{
hQuit = CreateEvent(
NULL, /* используем атрибуты защиты по умолчанию */
TRUE, /* создаем события с ручным сбросом */
FALSE, /* начальное состояние - сброшен */
"OS2" /* уникальное имя */
);
/* если приложение запущено -
завершаем выполнение с кодом 1 */
if (GetLastError() == ERROR_ALREADY_EXISTS){
MessageBox(NULL,"Нельзя запустить еще одну копию приложения!","Message",MB_OK);
return (1);
}
log_file=fopen("OS2.txt","wt");
int i;
//создаем события
hEv[0] = CreateEvent(NULL,TRUE,FALSE,"MyEvent1");
hEv[1] = CreateEvent(NULL,TRUE,FALSE,"MyEvent2");
hEv[2] = CreateEvent(NULL,TRUE,FALSE,"MyEvent3");
hEv[3] = CreateEvent(NULL,TRUE,FALSE,"MyEvent4");
hEv[4] = CreateEvent(NULL,TRUE,FALSE,"MyEvent5");
hEv[5] = CreateEvent(NULL,TRUE,FALSE,"MyEvent6");
hEv[6] = CreateEvent(NULL,TRUE,FALSE,"MyEvent7");
hEv[7] = CreateEvent(NULL,TRUE,FALSE,"MyEvent8");
hFl = CreateEvent(NULL,TRUE,TRUE,"MyEventF");
//создание потоков
T1 = CreateThread(0, 0, t1, 0, 0, &id1);
T2 = CreateThread(0, 0, t2, 0, 0, &id2);
T3 = CreateThread(0, 0, t3, 0, 0, &id3);
T4 = CreateThread(0, 0, t4, 0, 0, &id4);
T5 = CreateThread(0, 0, t5, 0, 0, &id5);
T6 = CreateThread(0, 0, t6, 0, 0, &id6);
T7 = CreateThread(0, 0, t7, 0, 0, &id7);
T8 = CreateThread(0, 0, t8, 0, 0, &id8);
T = CreateThread(0, 0, t, 0, 0, &id);
DWORD ret = WaitForSingleObject(T, 20000);
if (ret == WAIT_TIMEOUT){
MessageBox(NULL,"Слишком длительное выполнение! Работа прервана","",MB_ICONERROR);
fprintf(log_file, "Слишком длительное выполнение! Работа прервана ");
TerminateThread(T1, 0);
TerminateThread(T2, 0);
TerminateThread(T3, 0);
TerminateThread(T4, 0);
TerminateThread(T5, 0);
TerminateThread(T6, 0);
TerminateThread(T7, 0);
TerminateThread(T8, 0);
TerminateThread(T, 0);
}
else
fprintf(log_file, "Результат : ");
fprintf(log_file,"%f\n",res);
//завершаем работу событий
for (i=0;i<8;i++) CloseHandle(hEv[i]);
CloseHandle(hFl);
//завершаем работу потоков
CloseHandle(T1);
CloseHandle(T2);
CloseHandle(T3);
CloseHandle(T4);
CloseHandle(T5);
CloseHandle(T6);
CloseHandle(T7);
CloseHandle(T8);
CloseHandle(T);
fclose(log_file);
MessageBox(NULL,"Работа программы завершена. Результат в файле OS2.txt","",MB_ICONASTERISK);
return (0);
}
ЛИСТИНГ 2
#include "stdafx.h"
#include <iostream>
#include <fstream>
#include <algorithm>
using namespace std;
typedef unsigned long int my_size;
typedef unsigned int fat_inf;
class CAbstractCluster
{
public:
virtual bool LoadCluster(fstream& f)=0;
virtual bool SaveCluster(fstream& f)=0;
};
class CCluster:public CAbstractCluster
{
public:
my_size size;
char* inf;
my_size LastReadSize;
CCluster(my_size pSize,fstream& f):size(pSize),inf(0)
{
LoadCluster(f);
LastReadSize=0;
}
CCluster() {inf=0;LastReadSize=0;}
CCluster(my_size pSize)
{
size=pSize;
inf=new char[size];
for(int i=0;i<size;i++) inf[i]=0;
LastReadSize=0;
}
CCluster(const CCluster& C)
{
size=C.size;
inf=new char[size];
for(int i=0;i<size;i++) inf[i]=C.inf[i];
}
virtual bool LoadCluster(fstream& f)
{
if (!inf) return false;
int i;
for(i=0;(i<size)&&(!f.eof());i++) f.read(&inf[i],sizeof(char));
if(f.eof()) inf[i-1]=EOF;
//LastReadSize=i+1;
for(i++;i<size;i++) inf[i]=0;
return true;
}
virtual bool SaveCluster(fstream& f)
{
if (!inf) return false;
int i;
//f.write(inf,sizeof(char)*LastReadSize);
for(i=0;(i<size)&&(inf[i]!=EOF);i++) f.write(&inf[i],sizeof(char));
f.write(&inf[i],sizeof(char));
return true;
}
virtual bool OuternSaveCluster(fstream& f)
{
if (!inf) return false;
int i;
//f.write(inf,sizeof(char)*LastReadSize);
for(i=0;(i<size)&&(inf[i]!=EOF);i++) f.write(&inf[i],sizeof(char));
//f.write(&inf[i],sizeof(char));
return true;
}
};
class CBootCluster:public CAbstractCluster
{
public:
my_size size, //размер диска (кб)
clust, //размер кластера (кб)
fat, //кол-во ФАТ
root, //кол-во кластеров на описание корневого каталога
clust_in_fat, //кол-во кластеров в ФАТ
counter, //последнее значение счетчика
first_usable_cluster, //первый используемый кластер
clustnum; //кол-во кластеров
CBootCluster(fstream& f)
{
LoadCluster(f);
}
CBootCluster(){size=clust=fat=root=clust_in_fat=counter=first_usable_cluster=0;}
CBootCluster(
my_size p_size,
my_size p_clust,
my_size p_fat,
my_size p_root,
my_size p_clust_in_fat,
my_size p_clustnum,
my_size p_counter=1):
size(p_size),clust(p_clust),fat(p_fat),root(p_root),clust_in_fat(p_clust_in_fat),counter(p_counter),
clustnum(p_clustnum)
{}
CBootCluster(const CBootCluster& C)
{
size=C.size;
clust=C.clust;
fat=C.fat;
root=C.root;
clust_in_fat=C.clust_in_fat;
counter=C.counter;
clustnum=C.clustnum;
}
bool LoadCluster(fstream& f)
{
f.read((char*) &size,sizeof(my_size));
f.read((char*) &clust,sizeof(my_size));
f.read((char*) &fat,sizeof(my_size));
f.read((char*) &root,sizeof(my_size));
f.read((char*) &clust_in_fat,sizeof(my_size));
f.read((char*) &counter,sizeof(my_size));
f.read((char*) &first_usable_cluster,sizeof(my_size));
f.read((char*) &clustnum,sizeof(my_size));
f.seekg(1024*clust,ios::beg);
return true;
}
bool SaveCluster(fstream& f)
{
if(!size) return false;
f.write((char*) &size,sizeof(my_size));
f.write((char*) &clust,sizeof(my_size));
f.write((char*) &fat,sizeof(my_size));
f.write((char*) &root,sizeof(my_size));
f.write((char*) &clust_in_fat,sizeof(my_size));
f.write((char*) &counter,sizeof(my_size));
f.write((char*) &first_usable_cluster,sizeof(my_size));
f.write((char*) &clustnum,sizeof(my_size));
f.seekp(1024*clust,ios::beg);
return true;
}
};
class CFatCluster:public CAbstractCluster
{
public:
struct fat_rec
{
fat_inf file_ID;
my_size next;
fat_rec()
{
file_ID=0;
next=0;
}
bool operator==(int pID)
{
return file_ID==pID;
}
};
fat_rec* fat_sheet;
my_size fat_size;
my_size fat_real_size;
CFatCluster()
{fat_sheet=0;}
CFatCluster(my_size p_fat_size,my_size p_fat_real_size,fstream* f=0)
{
fat_real_size=p_fat_real_size;
fat_size=p_fat_size;
fat_sheet=new fat_rec[fat_size];
if(f) LoadCluster(*f);
}
CFatCluster(const CFatCluster& C)
{
fat_size=C.fat_size;
fat_real_size=C.fat_real_size;
fat_sheet=new fat_rec[fat_size];
copy(C.fat_sheet,C.fat_sheet+C.fat_size,fat_sheet);
}
bool LoadCluster(fstream& f)
{
//if(!fat_sheet) return false;
f.read((char*) &fat_size,sizeof(fat_size));
f.read((char*) &fat_real_size,sizeof(fat_size));
if(!fat_sheet) fat_sheet=new fat_rec[fat_size];
f.read((char*) fat_sheet,sizeof(fat_sheet[0])*fat_size);
f.seekg(fat_real_size-sizeof(fat_sheet[0])*fat_size,ios::cur);
return true;
}
bool SaveCluster(fstream& f)
{
if(!fat_sheet) return false;
f.write((char*) &fat_size,sizeof(fat_size));
f.write((char*) &fat_real_size,sizeof(fat_size));
f.write((char*) fat_sheet,sizeof(fat_sheet[0])*fat_size);
f.seekp(fat_real_size-sizeof(fat_sheet[0])*fat_size,ios::cur);
return true;
}
CFatCluster& operator =(const CFatCluster& C)
{
this->fat_size=C.fat_size;
fat_real_size=C.fat_real_size;
if(fat_sheet) delete [] fat_sheet;
fat_sheet=new fat_rec[fat_size];
copy(C.fat_sheet,C.fat_sheet+fat_size,fat_sheet);
return *this;
}
~CFatCluster()
{delete [] fat_sheet;}
};
class CDirectoryCluster:public CAbstractCluster
{
public:
struct CDirRecord
{
bool isFree;
char Name[12];
int ID;
my_size FirstClust;
CDirRecord(){isFree=1;}
CDirRecord& operator =(const CDirRecord& C)
{
isFree=C.isFree;
strcpy(&Name[0],&C.Name[0]);
ID=C.ID;
}
void Read(fstream& f)
{
f.read((char*) &isFree,sizeof(bool));
f.read((char*) &Name[0],12);
f.read((char*) &ID,sizeof(ID));
f.read((char*) &FirstClust,sizeof(FirstClust));
}
void Write(fstream& f)
{
f.write((char*) &isFree,sizeof(bool));
f.write((char*) &Name[0],12);
f.write((char*) &ID,sizeof(ID));
f.write((char*) &FirstClust,sizeof(FirstClust));
}
bool operator ==(const char* fName)
{
return !strcmp(fName,&Name[0]);
}
};
int NumFiles;
CDirRecord* DirFiles;
CDirectoryCluster()
{DirFiles=0;}
CDirectoryCluster(int pNumFiles,fstream* f=0)
{
NumFiles=pNumFiles;
DirFiles=new CDirRecord[NumFiles];
if(f) LoadCluster(*f);
}
CDirectoryCluster(const CDirectoryCluster& C)
{
NumFiles=C.NumFiles;
DirFiles=new CDirRecord[NumFiles];
copy(C.DirFiles,C.DirFiles+C.NumFiles,DirFiles);
}
~CDirectoryCluster()
{delete [] DirFiles;}
bool LoadCluster(fstream& f)
{
if(!DirFiles) return false;
for(int i=0;i<NumFiles;i++) DirFiles[i].Read(f);
return true;
}
bool SaveCluster(fstream& f)
{
if(!DirFiles) return false;
for(int i=0;i<NumFiles;i++) DirFiles[i].Write(f);
return true;
}
};
void info(const char* FName);
void Create(int argc,char** argv,char* filename)
{
unsigned long int size=0,clust=1,root=2;
size_t fat=2;
for(int i=0;i<argc;i++)
{
if(!strncmp(argv[i],"/SIZE",5))
size=atoi(&argv[i][6]);
if(!strncmp(argv[i],"/CLUST",6))
clust=atoi(&argv[i][7]);
if(!strncmp(argv[i],"/ROOT",5))
root=atoi(&argv[i][6]);
if(!strncmp(argv[i],"/FAT",4))
fat=atoi(&argv[i][5]);
}
if(!size || !clust || !root || !fat) throw ("Invalid parameter");
if(clust*(root+fat+2)>size) throw ("Invalid cluster size or disc value");
int clustnum=size/clust;
size=clust*clustnum*1024;
fstream f(filename,ios::binary|ios::out|ios::trunc);
char t=0;
for(int i=0;i<size;i++)
f.write(&t,sizeof t);
f.seekp(0,ios_base::beg);
CFatCluster::fat_rec temp_rec;
int clust_in_fat=(clustnum*sizeof(temp_rec)+2*sizeof(my_size))/(clust*1024)+1;
CBootCluster Boot(size,clust,fat,root,clust_in_fat,clustnum);
CFatCluster FAT(clustnum,clust_in_fat*1024);
CDirectoryCluster::CDirRecord temp_dir_rec;
CDirectoryCluster RootDir(root*clust*1024/sizeof(temp_dir_rec));
Boot.first_usable_cluster=(1+root+clust_in_fat*fat);
Boot.SaveCluster(f);
for(int i=0;i<fat;i++) FAT.SaveCluster(f);
RootDir.SaveCluster(f);
f.close();
info(filename);
}
void info(const char* FName)
{
fstream f(FName,ios::binary|ios::in);
if(!f.is_open()) throw("Invalid image name");
CBootCluster Boot;
f.seekg(0,ios::beg);
Boot.LoadCluster(f);
CFatCluster FAT(Boot.clustnum,Boot.clust_in_fat*Boot.clust*1024);
FAT.LoadCluster(f);
cout<<"Disc size: "<<Boot.size<<" bytes\n"
<<Boot.clust<<" KBytes in cluster\n"
<<Boot.clustnum<<" clusters in disc\n"
<<Boot.clust_in_fat*Boot.fat<<" clusters in "
<<Boot.fat<<" FAT's\n"
<<Boot.first_usable_cluster<<" clusters in serv information\n";
for(int i=0;i<Boot.first_usable_cluster;i++) cout<<"I";
for(int i=Boot.first_usable_cluster;i<Boot.clustnum;i++)
if(FAT.fat_sheet[i].file_ID) cout<<"U";
else cout<<"E";
cout<<"\nE - empty cluster\n"
<<"I - info cluster\n"
<<"U - used cluster\n";
}
void copy_to(int argc,char** argv,char* filename)
{
if(argc<2) throw("Invalid arguments");
if(strlen(argv[1])>11) throw("Invalid destination filename");
fstream i_f(argv[0],ios::binary|ios::in);
fstream f(filename,ios::binary|ios::out|ios::in);
if((!i_f.is_open())||(!f.is_open())) throw("Invalid filename");
f.seekp(0,ios::beg);
CBootCluster Boot;
Boot.LoadCluster(f);
CFatCluster* FAT=new CFatCluster[Boot.fat];
for(int i=0;i<Boot.fat;i++) FAT[i].LoadCluster(f);
CDirectoryCluster::CDirRecord temp_dir_rec;
CDirectoryCluster RootDir(Boot.root*Boot.clust*1024/sizeof(temp_dir_rec));
RootDir.LoadCluster(f);
CFatCluster tempFAT(FAT[0]);
CCluster Clust(Boot.clust*1024);
CFatCluster::fat_rec* PrevClust=0;
my_size firstClust;
while(!i_f.eof())
{
my_size i=Boot.first_usable_cluster;
for(;(tempFAT.fat_sheet[i].file_ID)&&(i<tempFAT.fat_size);i++);
if(i==tempFAT.fat_size) throw("Not enough space");
if(PrevClust) PrevClust->next=i;
else firstClust=i;
Clust.LoadCluster(i_f);
f.seekp(i*Boot.clust*1024,ios::beg);
Clust.SaveCluster(f);
PrevClust=&tempFAT.fat_sheet[i];
PrevClust->file_ID=Boot.counter;
}
int j=0;
for(;(j<RootDir.NumFiles)&&(!RootDir.DirFiles[j].isFree);j++);
if(j==RootDir.NumFiles) throw("Too many files in directory");
RootDir.DirFiles[j].ID=Boot.counter;
RootDir.DirFiles[j].isFree=0;
strcpy(RootDir.DirFiles[j].Name,argv[1]);
RootDir.DirFiles[j].FirstClust=firstClust;
for(j=Boot.fat-1;j>0;j--) FAT[j]=FAT[j-1];
FAT[0]=tempFAT;
f.seekp(0,ios::beg);
Boot.counter++;
Boot.SaveCluster(f);
for(j=0;j<Boot.fat;j++) FAT[j].SaveCluster(f);
RootDir.SaveCluster(f);
}
void copy_from(int argc,char** argv,char* filename)
{
if(argc<2) throw("Invalid arguments");
fstream f(filename,ios::in|ios::binary);
CBootCluster Boot(f);
CFatCluster* Fat=new CFatCluster[Boot.fat];
for(int i=0;i<Boot.fat;i++) Fat[i].LoadCluster(f);
CDirectoryCluster::CDirRecord temp_dir_rec;
CDirectoryCluster RootDir(Boot.root*Boot.clust*1024/sizeof(temp_dir_rec));
RootDir.LoadCluster(f);
CDirectoryCluster::CDirRecord* cur=find(RootDir.DirFiles,RootDir.DirFiles+RootDir.NumFiles,argv[0]);
if(cur==RootDir.DirFiles+RootDir.NumFiles) throw("File not found");
fstream o_f(argv[1],ios::binary|ios::out|ios::trunc);
if(!o_f.is_open()) throw("Invalid destination name");
CFatCluster::fat_rec* curFat=find(Fat[0].fat_sheet,Fat[0].fat_sheet+Fat[0].fat_size,cur->ID);
for(;curFat!=Fat[0].fat_sheet;curFat=Fat[0].fat_sheet+curFat->next)
{
CCluster CurCluster(Boot.clust*1024);
ifstream f2;
f.seekg((curFat-Fat[0].fat_sheet)*Boot.clust*1024);
CurCluster.LoadCluster(f);
CurCluster.OuternSaveCluster(o_f);
}
o_f.close();
f.close();
}
void Del(int argc,char** argv,char* filename)
{
if(argc<1) throw("Invalid arguments");
fstream f(filename,ios::in|ios::out|ios::binary);
CBootCluster Boot(f);
CFatCluster* Fat=new CFatCluster[Boot.fat];
for(int i=0;i<Boot.fat;i++) Fat[i].LoadCluster(f);
CDirectoryCluster::CDirRecord temp_dir_rec;
CDirectoryCluster RootDir(Boot.root*Boot.clust*1024/sizeof(temp_dir_rec));
RootDir.LoadCluster(f);
CDirectoryCluster::CDirRecord* cur=find(RootDir.DirFiles,RootDir.DirFiles+RootDir.NumFiles,argv[0]);
if(cur==RootDir.DirFiles+RootDir.NumFiles) throw("File not found");
CFatCluster::fat_rec* curFat=find(Fat[0].fat_sheet,Fat[0].fat_sheet+Fat[0].fat_size,cur->ID);
my_size next;
for(;curFat!=Fat[0].fat_sheet;curFat=Fat[0].fat_sheet+next)
{
next=curFat->next;
curFat->file_ID=0;
curFat->next=0;
}
cur->isFree=1;
f.seekp(0,ios::beg);
Boot.SaveCluster(f);
for(int j=0;j<Boot.fat;j++) Fat[j].SaveCluster(f);
RootDir.SaveCluster(f);
f.close();
}
void dir(char* filename)
{
fstream f(filename,ios::in|ios::binary);
CBootCluster Boot(f);
CFatCluster* Fat=new CFatCluster[Boot.fat];
for(int i=0;i<Boot.fat;i++) Fat[i].LoadCluster(f);
CDirectoryCluster::CDirRecord temp_dir_rec;
CDirectoryCluster RootDir(Boot.root*Boot.clust*1024/sizeof(temp_dir_rec));
RootDir.LoadCluster(f);
f.close();
cout<<"Root directory:\n";
for(int i=0;i<RootDir.NumFiles;i++)
{
if(RootDir.DirFiles[i].isFree) continue;
cout<<RootDir.DirFiles[i].Name<<"\n";
}
}
void waste(char* filename)
{
fstream f(filename,ios::in|ios::binary);
CBootCluster Boot(f);
CFatCluster* Fat=new CFatCluster[Boot.fat];
for(int i=0;i<Boot.fat;i++) Fat[i].LoadCluster(f);
CDirectoryCluster::CDirRecord temp_dir_rec;
CDirectoryCluster RootDir(Boot.root*Boot.clust*1024/sizeof(temp_dir_rec));
RootDir.LoadCluster(f);
my_size wasted=0;
for(int i=Boot.first_usable_cluster;i<Fat[0].fat_size;i++)
{
if((Fat[0].fat_sheet[i].file_ID!=0)&&(Fat[0].fat_sheet[i].file_ID!=0))
{
f.seekg(i*Boot.clust*1024,ios::beg);
char temp='0';
int curpos=0;
for(;temp!=EOF;curpos++)
{
f.read(&temp,1);
}
wasted+=Boot.clust*1024-curpos;
}
}
cout<<wasted<<" Bytes wasted";
}
int _tmain(int argc, char** argv)
{
/* argc=5;
if(argc<3) return 0;
argv[1]="MyDics.fs";
argv[2]="/WASTE";*/
for(int i=2;i<argc;i++) cout<<argv[i]<<" ";
cout<<"\n";
try{
if(!strncmp(argv[2],"/CREATE",7)) Create(argc-3,&argv[3],argv[1]);
if(!strncmp(argv[2],"/INFO",7)) info(argv[1]);
if(!strncmp(argv[2],"/COPYTO",7)) copy_to(argc-3,&argv[3],argv[1]);
if(!strncmp(argv[2],"/COPYFROM",9)) copy_from(argc-3,&argv[3],argv[1]);
if(!strncmp(argv[2],"/DEL",4)) Del(argc-3,&argv[3],argv[1]);
if(!strncmp(argv[2],"/DIR",4)) dir(argv[1]);
if(!strncmp(argv[2],"/WASTE",6)) waste(argv[1]);
cout<<"\nOK";
}
catch (const char* err)
{
cout<<err;
}
// cin.get();
return 0;
}
ПРИЛОЖЕНИЕ В
Файл отчета
2 поток создан.
1 поток создан.
3 поток создан.
2 поток завершен. Результат: 44.634828
1 поток завершен. Результат: 22.346290
7 поток создан.
7 поток завершен. Результат: 3495.464165
3 поток завершен. Результат: 67.351704
6 поток создан.
4 поток создан.
5 поток создан.
4 поток завершен. Результат: 6003.525983
5 поток завершен. Результат: 15104.686399
6 поток завершен. Результат: 8841.132682
8 поток создан.
8 поток завершен. Результат: 5358530.695865
Результат : 1689052300.380302