

Метод вложенных циклов (nlj – Nested Loop Join)
При этом методе каждая запись первой таблицы сравнивается с каждой записью второй таблицы (Рис. 1 .13, сравнение выполняется по номеру счёта). В общем случае условие сравнения может быть произвольным.

Рис. 1.13. Метод соединения NLJ.
Формулы оценки стоимости соединения при использовании метода NLJ зависят от:
1) используемого дерева соединений; в дальнейшем будем полагать, что используются левосторонние деревья и применяются каналы,
2) назначения буферов ввода-вывода (Рис. 1 .14).

Рис. 1.14. Схема назначения буферов ввода-вывода.
В этом случае формулы для вычисления стоимости соединения NLJ следующий вид:
 (5.8)
(5.8)
где
T(Q1), T(Q2) – число кортежей в таблицах подзапросов Q1 и Q2;
B(Q1) – число блоков в таблице Q1;
СI/O(Q2) – время ввода-вывода для получения таблицы Q2;
b – число блоков в буфере для Q1;
Ccomp – время соединения (сравнения) двух кортежей из таблиц Q1 и Q2 в оперативной памяти (ОП);
![]() - округление с
недостатком.
- округление с
недостатком.
Во второй формуле учитывается возможность многопроходного варианта соединения таблицы Q2, если таблица Q1 не умещается в "b" блоках буфера оперативной памяти. Округление берётся с недостатком, так как одно чтение таблиц с диска учитывается в стоимости выбора записей из исходных таблиц.
Метод сортировки-слияния (smj – Sort Merge Join)
Соединение таблиц включает следующие шаги:
1. Соединяемые таблицы сортируются по атрибуту соединения (обозначим его через "а").
2. Организуется вложенный цикл, где выполняется сравнение значений атрибутов соединения.
Условием соединения может быть только равенство атрибутов соединения.
Пример выполнения соединения методом сортировки-слияния приведен на Рис. 1 .15.
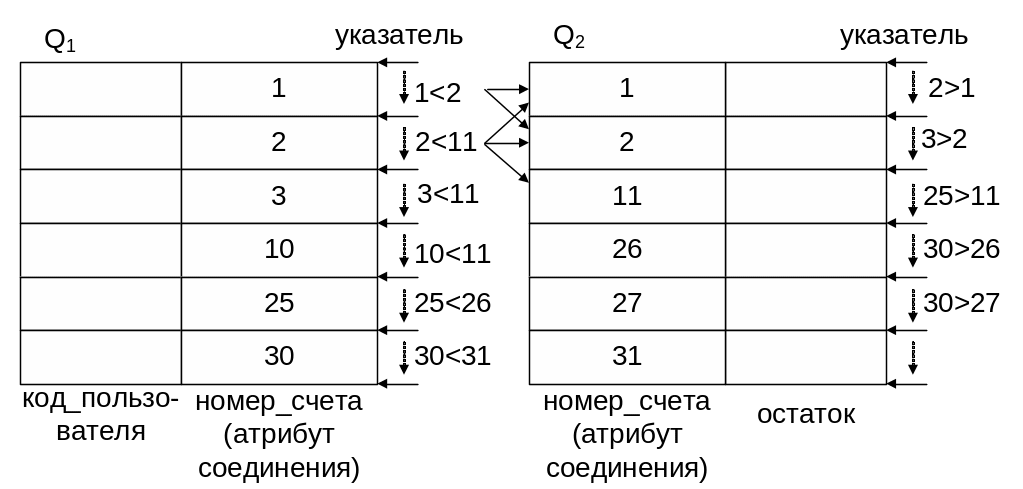
Рис. 1.15. Метод соединения SMJ.
Выполняется сравнение записей, на которые указывают указатели таблиц Q1 и Q2 . Перемещение указателей выполняется следующим образом: если выполняется условие "<", то осуществляется перемещение указателя Q1 к следующей записи; если выполняется условие ">", то к следующей записи перемещается указатель Q2 ; при "=" указатели не перемещается и выполняется сравнение со следующей записью таблицы Q2.
Будем полагать, что используются левосторонние деревья и каналы. Схема назначения буферов приведена на Рис. 1 .16.

Рис. 1.16. Схема назначения буферов.
Формулы для оценки стоимости соединения SMJ имеют следующий вид.

Здесь
T(Q1), T(Q2) – число кортежей в таблицах Q1 и Q2;
B(Q1), B(Q2) – число блоков в таблицах Q1 и Q2;
I(Q1,a), I(Q2,a) – мощности атрибутов соединения "а" в таблицах Q1 и Q2;
b – число блоков в ОП, отводимых под сортировку таблицы Q1 или Q2;
Ccomp – время соединения двух кортежей из таблиц Q1 и Q2 в ОП;
Cmove – время перемещения одного кортежа в ОП при сортировке;
CB – время чтения/записи одного блока на диск;
![]() - округление с
избытком;
- округление с
избытком;
![]() - округление с
недостатком;
- округление с
недостатком;
![]() - не учитывается,
если таблицы были уже отсортированы
перед началом соединения.
- не учитывается,
если таблицы были уже отсортированы
перед началом соединения.
Некоторые формулы требуют пояснений. Рассмотрим сначала, как выполняется сортировка записей достаточно большой таблицы.
Блоки 1b таблицы R читаются в буфер (Рис. 1 .17) и записи этих блоков сортируются. Результат сортировки сохраняется в виде файла. Затем читаются следующие "b" блоков (b2b, см. Рис. 1 .17) и их записи также сортируются, результат сортировки сохраняется во втором файле и т.д.
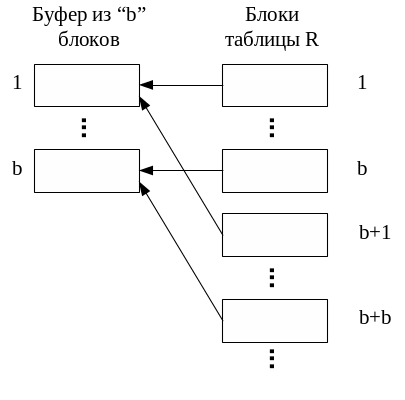
Рис. 1.17. Чтение большой таблицы в буфер из b блоков.
Сохранённые файлы представлены в виде уровня 1 на Рис. 1 .18.
Известно,
что число операций сравнений и перемещений
при сортировке пропорционально величине
![]() ,
где
,
где
![]() -
число сортируемых записей.
-
число сортируемых записей.
![]() - это количество файлов уровня 1. Поэтому
для одного файла
- это количество файлов уровня 1. Поэтому
для одного файла
 .
С учётом числа файлов получаем первое
слагаемое в формуле 3 (см. выражения
(5.9)).
.
С учётом числа файлов получаем первое
слагаемое в формуле 3 (см. выражения
(5.9)).
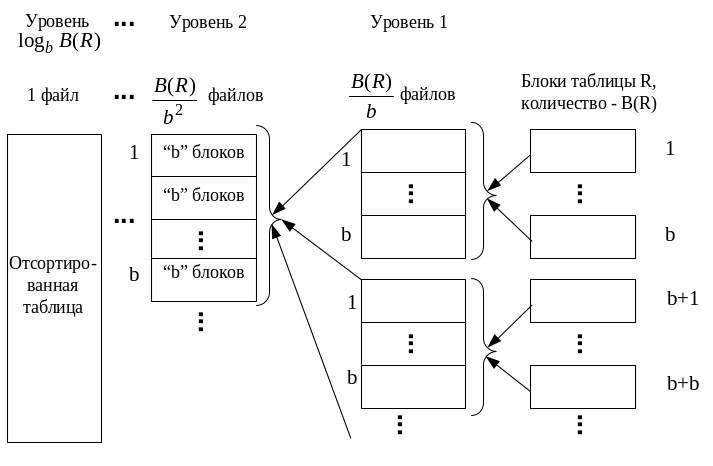
Рис. 1.18. Последовательное укрупнение отсортированных промежуточных файлов.
Далее из 1-го файла уровня 1 записи читаются в 1-й блок буфера, из 2-го файла уровня 1 записи читаются во 2-й блок и т.д., и из b-го файла уровня 1 записи читаются в b-й блок (Рис. 1 .19). В каждом блоке записи уже отсортированы на предыдущем этапе. Поэтому сравниваются первые записи этих блоков по атрибуту сортировки (b сравнений). Запись с минимальным значением атрибута перемещается в файл (одно перемещение). Остальные записи соответствующего блока сдвигаются вверх (блок работает как стек). Затем снова сравниваются первые записи b блоков по атрибуту сортировки и т.д. Если записи в каком-либо блоке исчерпаны, то в этот блок подгружаются записи из связанного с ним файла. После обработки таким способом b файлов уровня 1 будет сформирован файл уровня 2 (см. Рис. 1 .18), записи в котором отсортированы. Далее в блоки буфера подгружаются записи следующих b файлов уровня 1 и т.д.
По
аналогичной схеме (см. Рис. 1 .19) объединяются
файлы уровня 2 и т.д. В конце концов, будет
сформирован один отсортированный
результирующий файл (см. Рис. 1 .18).
Количество уровней L
может быть получено из уравнения
![]() (число файлов на самом нижнем уровне
равно 1), т.е.
(число файлов на самом нижнем уровне
равно 1), т.е.
![]() .
.
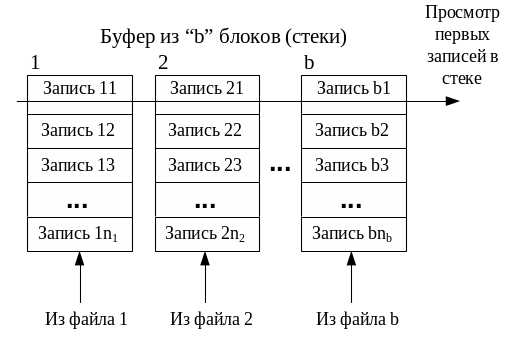
Рис. 1.19. Сортировка записей из b промежуточных файлов.
На каждом уровне (кроме последнего) по описанной выше схеме (см. Рис. 1 .19) обрабатываются все записи таблицы R (их число равно T(R)). Это объясняет второе слагаемое в формуле 3. В файлах каждого уровня хранятся B(R) блоков. Это объясняет формулу 4. Здесь коэффициент 2 учитывает, что каждый файл каждого уровня записывается на диск, а потом читается.
Чтение блоков таблицы R с диска (см. Рис. 1 .17) учитывается в стоимости выбора записей из исходной таблицы.
В
формуле 5 первое слагаемое определяет
процессорное время сравнения соединяемых
записей. Если
![]() ,
то каждая запись из
,
то каждая запись из
![]() (их число равно
(их число равно
![]() )
сравнивается и соединяется с
)
сравнивается и соединяется с
![]() записями из
записями из
![]() (т.е. с числом записей из
,
приходящихся на одно значение атрибута
соединения). Константа 2 учитывает
сравнения записей при перемещении
указателей. Второе слагаемое в формуле
5 связано с холостыми проверками.
Количество таких сравнений равно числу
записей в
,
у которых значение атрибута соединения
отличается от всех значений атрибута
"а" в
(мощность таких значений атрибута "а"
в
равно
(т.е. с числом записей из
,
приходящихся на одно значение атрибута
соединения). Константа 2 учитывает
сравнения записей при перемещении
указателей. Второе слагаемое в формуле
5 связано с холостыми проверками.
Количество таких сравнений равно числу
записей в
,
у которых значение атрибута соединения
отличается от всех значений атрибута
"а" в
(мощность таких значений атрибута "а"
в
равно
![]() ).
).
В формуле 6 учитывается возможное чтение таблиц и после сортировки (первые два слагаемых), а также многопроходной вариант соединения, если не все блоки с одинаковыми значениями атрибута связи помещаются в буфере из b блоков (третье слагаемое).