

4.3 Результати виконання програми
При дослідженні ефективності роботи програми з використання чотирьох процесорного кластера процесорного (комп’ютери PIV 1.3ГГц 256Мb RAM, мережа 100 Mbit Fast Ethernet) було отримано експериментальні дані, що наведено в таблиці 4.2. З таблиці видно, що отримано прискорення рвіне 2.91. Це відрізняється від розрахункового значення, обчисленого згідно виразу 4.3, що пояснюється затратами на надсилання даних.
Таблиця 4.2
N |
Розмір матриці |
Час виконання послідовного алгоритму |
Час виконання паралельного алгоритму на 4-х процесорах |
1 |
(2000х2000) |
4.58с. |
1.61с. |
2 |
(3000х3000) |
11.42с. |
3.93с. |
4.4. Висновки
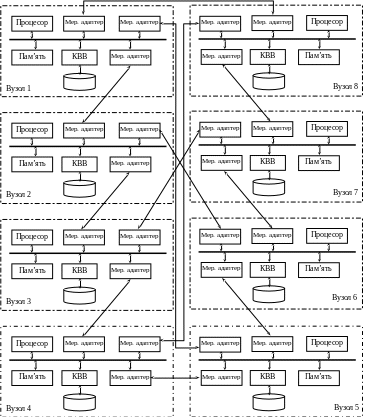
В процесі виконання курсового проекту було досягнуто кінцевої мети – спроектовано структурну схему багатопроцесорної системи та розроблено програмне забезпечення з використанням бібліотек паралельного програмування МРІ для реалізації методу Якобі для розв’язку систем лінійних рівнянь.. Виконано графічне креслення структурної схеми системи, а також блок-схеми паралельного алгоритму програми згідно діючих стандартів.
Література Основна:
1. Цилькер Б.Я., Орлов С.А. Организация ЭВМ и систем: Учебник для вузов. – СПб.: Питер, 2004. – 668с.
2. Корнеев В.В. Параллельные вычислительные системы. – М.: «Нолидж», 1999., - 320с.
3. Организация ЭВМ. 5-е изд../ К. Хамахер, З. Вранешич., С. Заки. – СПб.: Питер; Киев: изд. группа BHV, 2003. – 848с.
4. Эндрюс Г.Р. Основы многопоточного, параллельного и распределенного программирования.: Пер. с англ. – М.: Издательский дом «Вильямс», 2003. – 512с.
5. Богачёв К.Ю. Основы параллельного программирования / К.Ю. Богачёв. – М.:Бином. Лаборатория знаний, 2003. – 342с.
Додаткова:
1. Воеводин В.В., Воеводин Вл. В. Параллельные вычисления. – СПб.: БХВ-Питербург, 2004. – 608с.
2. Многопроцессорные вычислительные и паралельное программирование. Ресурс: http://oldunesco.kemsu.ru/mps/
3. Шпаковский Г.И., Серикова Н.В. Пособие по программированию матричных задач в МРІ. – Мн.: БГУ, 2002. – 44 с.
4. Антонов А.С. Параллельное программирование с использованием технологии MPI: Учебное пособие. – М.: Изд-во МГУ, 2004. – 71с.
5. Гергель В.П., Стронгин Р.Г. Основы параллельных вычислений для многопроцессорных вычислительных систем. - Н.Новгород: ННГУ им. Н.И. Лобачевского, 2001.
6. Немнюгин С., Стесик О. Параллельное программирование для многопроцессорных вычислительных систем — СПб.: БХВ-Петербург, 2002.
7. А. А. Букатов и др. Программирование многопроцессорных вычислительных систем. Ростов-на-Дону. Издательство ООО «ЦВВР», 2003, 208 с.
8. Теория и практика параллельных вычислений:
http://www.intuit.ru/department/calculate/paralltp/
Архитектура параллельных вычислительных систем: http://www.intuit.ru/department/hardware/paralltech/
10. Архитектуры и топологии многопроцессорных вычислительных систем:
http://www.intuit.ru/department/hardware/atmcs/
11. Теория и практика параллельных вычислений:
http://www.intuit.ru/department/calculate/paralltp/
12. Параллельное программирование:
http://www.intuit.ru/department/se/parallprog/
13. http://www.parallel.ru
Додатки

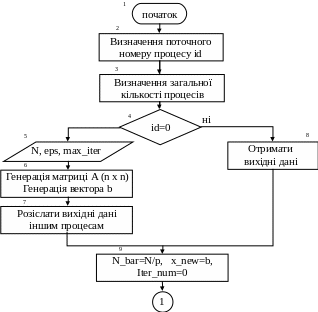
Додаток 2
Блок-схема паралельного методу Якобі
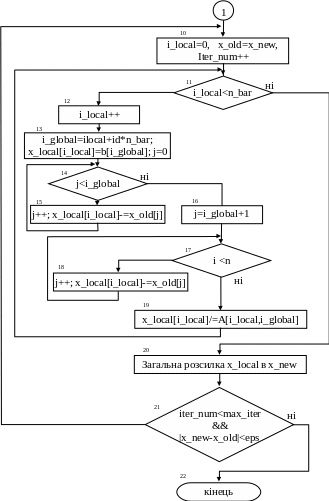
Продовження додатку 2
Додаток 3
Лістинг паралельної програми
для реалізації методу Якобі
#include <stdlib.h>
#include <stdio.h>
#include <conio.h>
#include <time.h>
#include <math.h>
#include <mpi.h>
#include <dos.h>
#pragma hdrstop
#define MAX_DIM 1000
#define MAX_PROC 10
#define tol 0.01
//--------------------------------------------------
double Distance(double x[], double y[],int n);
void main(int argc, char* argv[])
{
int n=250;
int max_iter=500000;
int **a;
int **a_local;
double *x_local;
double *b;
double *b_local;
int iter_num,p,my_rank;
int i_local,i_global,j,n_bar;
double *x_old;
double *x_new;
int gr,gr2,comm;
int ranks[MAX_PROC];
int len;
int disp[MAX_PROC];
int cnt[MAX_PROC];
double t;
int temp;
int i;
MPI_Datatype TVector;
//ініціалізація
MPI_Init(&argc,&argv);
MPI_Comm_rank(MPI_COMM_WORLD,&my_rank);
MPI_Comm_size(MPI_COMM_WORLD,&p);
len=p-n;
n_bar=n/p;
MPI_Type_vector(1,n,MAX_DIM,MPI_FLOAT,&TVector);
MPI_Type_commit(&TVector);
if (p>n)
{
MPI_Comm_group(MPI_COMM_WORLD,&gr);
for(i=0;i<len;i++)
ranks[i]=p-i-1;
MPI_Group_excl(gr,len,ranks,&gr2);
MPI_Comm_create(MPI_COMM_WORLD,gr2,&comm);
}
else comm=MPI_COMM_WORLD;
a= new int*[n]; // масив вказівників на стовбці
for (i=0;i<n;i++)
a[i]= new int [n]; // масив елементів стовбця
a_local=new int *[n_bar]; // масив вказівників на
// стовбці
for (i=0;i<n;i++)
a_local[i]= new int[n];//масив елементів стовбця
b=new double[n];
x_new=new double[n];
x_old=new double[n];
x_local=new double[n];
b_local=new double[n];
if(!my_rank){ // Якщо нульовий процесор
for (int i=0;i<n;i++){
for(int j=0;j<n;j++){
if(i==j){ a[i][j]=(rand()%89)+10;}
else {a[i][j]=(rand()%10)+10;}
};
b[i]=rand()%90;
};
};
temp=p-n*n_bar;
for (i=0;i<p;i++){
if(i>temp)
{
cnt[i]=n_bar+1;
}
else
{
cnt[i]=n_bar;
};
if (i==0)
{
disp[i]=0;
}
else
{
disp[i]=disp[i-1]+cnt[i-1];
}
}
MPI_Scatterv(a, cnt, disp, TVector,a_local,
cnt[my_rank], TVector, 0, comm);
MPI_Scatterv(b, cnt, disp, MPI_DOUBLE, b_local,
cnt[my_rank], MPI_DOUBLE, 0, comm);
t=MPI_Wtime();
iter_num=0;
for (i=0;i<n;i++)
{
x_new[i]=b[i];
x_old[i]=x_new[i];
}
do{
for (i=0;i<n;i++)
{
x_old[i]=x_new[i];
}
iter_num++;
for(i_local=0;i_local<n;i_local++)
{
i_global=i_local+disp[my_rank];
x_local[i_local]=b_local[i_local];
for(j=0;j<i_local;j++)
x_local[i_local] = x_local[i_local]-
x_old[j];
for(j=i_local+1;j<n;j++)
x_local[i_local] = x_local[i_local]- x_old[j];
x_local[i_local]= x_local[i_local] /
a_local[i_local][i_global];
}
MPI_Allgather(x_local,cnt[my_rank],MPI_FLOAT,x_new,
cnt[my_rank],MPI_FLOAT,MPI_COMM_WORLD);
} while((iter_num<max_iter)&&
(Distance(x_new,x_old,n)>=tol));
if (Distance(x_new,x_old,n)<=tol)
printf("Iteration converged\n");
else
printf("Iteration not converged\n");
printf("Time Of Computation is: %f\n",MPI_Wtime()-t);
getch();
MPI_Finalize();
}
//---------------------------------------------------
double Distance(double x[], double y[],int n)
{
int i;
double sum=0.0,t;
for (i=0;i<n;i++)
{
t=(x[i]-y[i])*(x[i]-y[i]);
sum += t;
}
return sqrt(sum);
}