

3.10. Обработка двумерных массивов.
Массивы являются очень удобным средсвом для хранения и обработки больших групп логически связанных данных. Главным достоинством массивов является то, что они позволяют организовать обработку данных в виде компактных циклических процессов. Выше мы определили основные понятия связанные с массивами и рассмотрели примеры обработки одномерных массивов. Очень широкое распространение получили двумерные массивы. Это связано с тем, что независимо от способа хранения данных в памяти ЭВМ двумерный массив можно представить в виде плоской двумерной таблицы, состоящей из строк и столбцов. Например, двумерный массив У из шести элементов можно представить в виде таблицы, содержащей две строки и три столбца:
У11 У12 У13
У21 У22 У23 .
Элемент двумерного массива также как и в случае одномерного обозначается индексированной переменной, которая имеет два индекса, например
У(К,М),
Где К – номер строки;
М – номер столбца.
При перемещении по строке изменяется второй индекс, а при смещении по столбцу изменяется первый индекс.
Основная причина использования двумерных массивов – высокая наглядность и возможность построения компактных циклических алгоритмов для обработки этих массивов.
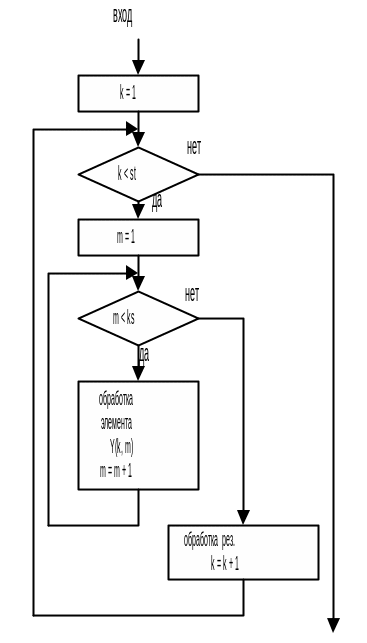
Рис.3.10.5
Для решения задач связанных с обработкой двумерных массивов возможны 4 варианта:
обработка по строкам;
обработка по столбцам,
цикл с предусловием;
цикл с постусловием.
На рис.3.10.5 приведен общий вид алгоритма обработки двумерного массива по строкам и циклом с предусловием. Алгоритм представляет собой два циклических процесса, причем один цикл вложен в другой. Параметром внутреннего цикла является переменная m. Этот цикл обеспечивает обработку элементов строки (в процессе выполнения цикла изменяется второй индекс). Параметром внешнего цикла является переменная k. Этот цикл обеспечивает переход к очередной строке.
 Пример. Составить фрагмент
Пример. Составить фрагмент
Рис.3.10.6. алгоритма вычисления сумм элементов столбцов двумерного массива Z. Значения сумм элементов стобцов накапливать в одномерном массиве Sumst.
Идея алгоритма.
Начиная с первого столбца суммируем элементы столбца и заносим полученное значение в одномерный массив. Затем переходим к следующему столбцу и снова суммируем.
Будем использовать следующие обозначения:
KS – количество столбцов; ST – количество строк;
K – счетчик строк; M – счетчик столбцов;
S – простая переменная для накопления суммы элементов столбца;
SUMST – одномерный массив для хранения сумм элементов столбцов.
Схема алгоритма решения этой задачи приведена на рис.3.10.6.