

Модель доски объявлений (Модель классной доски)
Впервые была предложена для задачи распознавания речи. Эта методология расширяет возможности систем, основанных на правилах, т.к. позволяет организовать работу самой системы в виде отдельных модулей.
Каждый такой модуль соответствует подмножеству продукционных правил, предназначенных для выполнения конкретной цели.
Сама классная доска интегрирует эти отдельные наборы правил в единые структуры и координирует решение задачи в пределах этой структуры.
Рассмотрим в качестве примера задачу распознавания речи, которая вводится в систему в виде сигнала некоторой оцифрованной волны. Из этой волны программа в начале выделяет отдельные фонемы, то есть возможные звуковые сегменты этого акустического сигнала. Фонемы затем преобразуются программой последовательно в слоги, слова, части предложения и окончательные фразы. Такой подход был реализован в системе HEARSAY-II (Слух, молва). Схема системы имеет вид:
ИЗ – источник знания
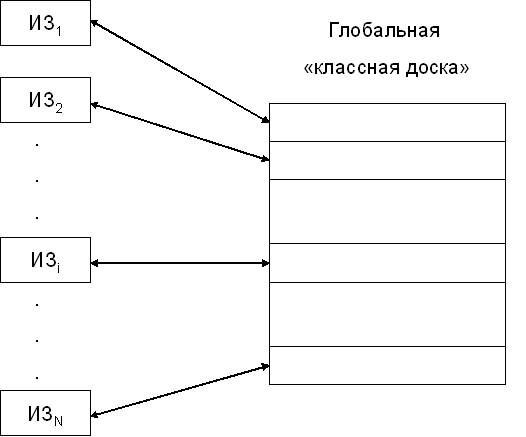
Каждый из ИЗ отвечает здесь за свой собственный уровень сигнала, поступившей информации. Для анализа (распознавания) речи таких ИЗ семь (как минимум)
ИЗ1 – анализ формы волны акустического сигнала и его временная диаграмма.
ИЗ2 – анализ фонемы, группировка правил для анализа фонемы.
ИЗ3 – анализ слогов, которые могут быть найдены из фонемы.
Анализ возможных
слов, каждый ИЗ получит при этом
информацию из различных частей данных.
И З4
З4
ИЗ5
ИЗ6 - анализ возможных последовательностей слов.
ИЗ7 – связь последовательностей слов в фразы.
Каждый ИЗ получал свои данные от глобальной классной доски, обрабатывал их и возвращал данные опять в глобальную классную доску для их дальнейшего использования другими ИЗ.
Таким образом, каждый ИЗ отвечал за изолированный вычислительный процесс и все процессы участвовали в решении общей задачи независимо, то есть система была асинхронной: каждый ИЗ работал только тогда, когда он активизировался, а результаты возвращались в общую систему.
Разрабатывалась эта система как интерфейс для БД публикаций по теории вычислительных систем. В системе на английском языке пользователь мог задать, например, вопрос «Есть ли у вас какие-либо работы Фельдмана?», компьютер распознавал речь и выдавал список из БД. Для того, чтобы реализовать такую методологию, необходимо глобальную доску объявлений спроектировать как информационный канал, в котором возможны два потока информации: нисходящий и восходящий. Это соответствует следующей так называемой концептуальной схеме.
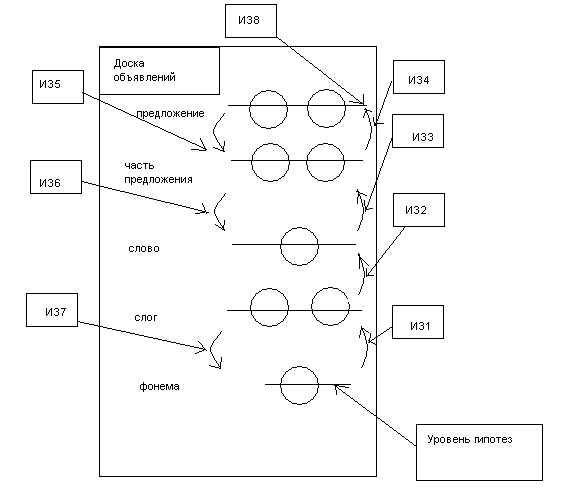
На доске объявлений иерархически определены гипотезы, которые выдвигает система на базе введенной ситуации. На нижнем уровне находятся фонемы, которые она распознала, а далее группируются последовательно полученные слоги, слова, части предложения и сами предложения. Переход от гипотезы к гипотезе и их анализ осуществляется с помощью источников знаний, которые могут действовать как между уровнями гипотез (например ИЗ1 или ИЗ7), так и на уровне самой гипотезы (например ИЗ8).
Если бы задача была идеальной, то решение, принимаемое на каждом уровне было бы единственным, но распознавание речи – классический пример задачи с неопределенными, размытыми исходными данными, поэтому на каждом уровне (например, при синтезе фонем в слога) работают конфликтующие между собой гипотезы. Система должна разрешить этот конфликт с помощью других источников знаний и может, например, даже потребовать повторного цикла при работе с гипотезой этого уровня. Например, если слог не удалось синтезировать, ИЗ7 возвращает анализ к уровню фонем. Далее окончательное предложение тоже подвергается анализу, что производиться ИЗ8 и может привести так же к повторному циклу синтеза предложения, что осуществляется с помощью ИЗ5 и ИЗ4. Таким образом, и осуществляется два потока данных: восходящий (при синтезе более сложных) и нисходящий (который появляется, когда не удаётся разрешить конфликт гипотез и требуется повторная работа на более низком уровне).
Такая модель имеет преимущества с точки зрения систематизации знаний и повышения эффективности вывода, так как функции каждого ИЗ и ситуации, в которых они используются , четко определены, так как ИЗ работают только, когда они активны для системы. Очень важно, в каком порядке эти ИЗ будут активизироваться.
Здесь используются два метода:
метод планировщика;
метод отправителя.
В первом методе основная роль принадлежит доске объявлений. С неё директивно на ИЗ поступают сообщения о том, какой из них активен и сама доска имеет такой алгоритм управления.
В втором методе каждый ИЗ имеет дополнительный блок, который определяет и называет «отправителя», следовательно ИЗ, который будет работать следующим за этим активным.
Программа распознавания речи HEARSAY имела несколько версий. HEARSAY II работала по методу планировщика и при этом планировщик был реализован, как отдельный ИЗ. Он анализировал введенную речь (исходные данные) и составлял приоритетную очередь из других ИЗ. При таком подходе, когда нет ни одного активного ИЗ, получен окончательный вывод и система прекращает работу. Пока система работала с БД, включающей около 1000 слов, она функционировала достаточно хорошо, хотя и медленно. Большие объемы данных она обрабатывать не могла. Следующая версия HEARSAY-III была уже разработана как оболочка для проектирования экспертных систем. Её планировщик был реализован в виде контроллера, как бы второй классной доски, которая управляла работой классной доски, соответствующей предметной области, упрощенно показанной на первом рисунке.
В таком контроллере за разные аспекты процедуры решения отвечают свои собственные ИЗ. Это позволяет более эффективно сравнивать различные гипотезы, выдвигаемые системой, и как результат - повысить производительность.
Следует отметить, появление альтернативной структуры классной доски. В ней наиболее важные знания не выносятся в ИЗ, а хранятся на самой мобильной классной доске.
Кроме того, существует тенденция совместного комбинированного использования рассмотренной модели классной доски и модели, основанной на фреймах.