

деталей определения данных. Предоставляя доступ к множеству общих данных и поддерживая мощные языки управления данными, информационные системы, использующие базы данных, позволяют значительно сократить объем работ по созданию и поддержке программного обеспечения.
1.5. Информационные системы, использующие базы данных
Информационные системы, использующие базы данных, позволили преодолеть ограничения файловых систем. Поддерживая целостную, централизованную структуру данных, информационные системы, использующие базы данных, позволили избавиться от проблем избыточности и слабого контроля данных. Доступ к централизованной базе данных имеет вся компания, и если, например, необходимо внести изменение в имя клиента, это изменение будет известно всем пользователям. Данные контролируются посредством словаря/каталога данных (data dictionary/directory, DD/D), которым, в свою очередь, управляет группа сотрудников компании, называемых администраторами базы данных (АБД). Новые методы обращения к данным сильно упростили процесс связывания элементов данных, что привело к расширению возможностей работы с данными. Все эти характеристики систем управления базами данных упрощают процесс программирования и уменьшают необходимость программной поддержки.
В настоящее время процесс создания максимально мощных систем управления базами данных идет полным ходом. За несколько десятилетий последовательно появлялись системы, основанные на трех базовых моделях данных, или концептуальных методах структурирования данных: иерархическая, сетевая и реляционная.
1.6. Иерархические и сетевые модели систем
Индексно-последовательные файлы решили проблему прямого обращения к определенной записи в файле. Для примера посмотрим снова на рис. 1.2. Если мы прочли первую запись о продажах в файле SALE и хотим узнать имя и адрес клиента, с которым была заключена эта сделка, мы можем просто воспользоваться идентификатором клиента (100), чтобы посмотреть соответствующую запись в файле CUSTOMER. Таким образом, мы выясним, что заказ был сделан компанией братьев Уотэйб.
Теперь предположим, что нам требуется обратный процесс. Вместо того чтобы выяснять, с каким клиентом заключена сделка, мы хотим найти все продажи данному клиенту. Мы начнем с записи «Братья Уотэйб» в файле CUSTOMER, а затем найдем все продажи этой компании. В файловой системе мы не сможем напрямую получить ответ на наш вопрос. Именно для подобных прикладных задач и были придуманы системы управления базами данных.
Первая информационная система, использующая базы данных, появившаяся в середине шестидесятых годов, была основана на иерархической модели, что означает, что отношения между данными имеют иерархическую структуру. Для того чтобы пояснить это, слегка изменим базу данных, приведенную на рис. 1.2. Вместо продаж, записанных в виде одной строки, у нас будут счета-фактуры, которые, в свою очередь, состоят из нескольких строк. К каждому клиенту может относиться несколько таких счетов, и каждый счет может состоять из нескольких строк. Каждая строка обозначает продажу одного товара. На рис. 1.7 представлен пример. Теперь вместо файла SALE у нас есть файлы INVOICE (СЧЕТ) и INVOICE LINE (СТРОКА-СЧЕТА).
Иерархическая модельмодель данных, в которой связи между данными имеют вид иерархий.
|
CUSTOMER | |||||||
|
CUST-ID |
CUST-NAME |
ADDRESS |
COUNTRY |
BALANCE | |||
|
100 101 105 110 |
Уотэйб Мальтц Джефф Гомес |
П/я 241 П/я 102 П/я 98 П/я 76 |
Япония Австрия США Чили |
45 551 75 314 49 333 27 400 | |||
|
INVOICE | |||||||
|
INVOICE-# |
ДАТА |
CUST-ID |
SALREP-ID | ||||
|
1012 1015 1020 |
10.02 14.02 20.02 |
100 110 100 |
39 37 14 | ||||
|
INVOICE LINE | |||||||
|
INVOICE-# |
LINE-# |
PROD-ID |
QTY |
TOTAL-PRICE | |||
|
1012 1012 1012 1015 1015 1020 1020 |
01 02 03 01 02 01 02 |
1035 2241 2518 1035 2518 2241 2518 |
100 200 300 150 200 10 150 |
2200.00 6650.00 6360.00 3300.00 4240.00 3325.00 3180.00 | |||
Рис. 1.7. Файлы IPD, имеющие иерархическую структуру
На рис. 1.8 показано, как выглядит иерархия отношений между клиентами, счетами и строками счетов. Клиенту «подчинены» счета, которым, в свою очередь, «подчинены» строки. В иерархической базе данных эти три файла будут связаны между собой физическими указателями, или полями данных, добавленными к отдельным записям. Указатель это физический адрес, означающий, где запись находится на диске. Каждая запись о клиенте будет содержать указатель первой записи счета этого клиента. В свою очередь, записи счетов будут содержать указатели на другие записи счетов и на записи строк счетов. Таким образом, система легко сможет извлечь все записи счетов и строк счетов, относящихся к данному клиенту.
Указательфизический адрес, обозначающий место хранения записи на диске.
Предположим, что мы хотим добавить в нашу иерархическую базу данных информацию о клиентах. Например, если наши клиенты торговые компании, нам может понадобиться список магазинов каждой компании. В этом случае мы расширим диаграмму, приведенную на рис. 1.8, придав ей вид, представленный на рис. 1.9. Файл CUSTOMER по-прежнему находится над файлом INVOICE, который находится над файлом INVOICE LINE. Но в то же время с файлом CUSTOMER связан файл STORE (МАГАЗИН), а с ним — файл CONTACT (ПРЕДСТАВИТЕЛЬ). Под представителем мы подразумеваем закупщика, которому продаем товары для конкретного магазина. Из этой диаграммы мы видим, что клиент является вершиной иерархии, из которой мы можем извлечь немало информации.
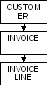
Рис. 1.8. Иерархическая модель отношений между файлами CUSTOMER, INVOICE и INVOICE LINE
На этих диаграммах показаны те разновидности связей между файлами, которые могут быть легко реализованы в иерархической модели. Однако быстро стало ясно, что у такой модели есть некоторые существенные ограничения, поскольку не все отношения можно представить в виде иерархии. Например, вернемся к нашему примеру и сделаем следующий шаг. Очевидно, что нас могут интересовать связи не только между клиентами и счетами, но и между торговыми агентами и счетами. То есть мы хотим иметь список всех счетов на продажи, произведенные определенным торговым агентом, чтобы подсчитать сумму причитающихся ему комиссионных. Новые связи представлены на рис. 1.10.

Рис. 1.9. Иерархическая модель отношений между файлами CUSTOMER, INVOICE и STORE
Однако эта диаграмма не является иерархической. В иерархии у каждого потомка может быть только один предок. На рис. 1.9 INVOICE потомок, CUSTOMERего предок. Однако на рис. 1.10 у INVOICE имеется два предкаSALES-REPRESENTATIVE и CUSTOMER. Такого рода диаграммы называются сетевыми. В связи с очевидной необходимостью обрабатывать такие отношения в конце шестидесятых появились сетевые системы управления базами данных. Как и в иерархических, в сетевых системах баз данных для связывания файлов использовались физические указатели.

Рис. 1.10. Сетевая модель отношений между файлами SALESREP, CUSTOMER и INVOICE
Потомокподчиненная запись в иерархии.
Предокподчиняющая запись в иерархии.
Сетьотношения между данными, когда каждая подчинена записям более, чем из одного файла.
Основная иерархическая СУБД система IMS фирмы IBM, созданная в середине шестидесятых годов. В конце шестидесятыхначале семидесятых были созданы и завоевали рынок несколько сетевых СУБД; стандартом для такой модели, в конце концов, стал CODASYL. В последующих главах мы обсудим обе эти модели данных, требуемые для них определения данных и возможности управления данными.