

Краткое введение в язык ассемблера.
Ассемблер предназначен для написания программ, эффективных по времени и потреблению ресурсов. Обычно используется для написания относительно коротких программ или фрагментов программ на языках высокого уровня.
Особенностями ассемблера по сравнению с математическим языком являются:
символичные наименования операций и операндов;
отсутствие привязки к конкретным адресам памяти;
возможность специализации программ с помощью макросредств.
Дальнейшее изложение ориентировано на использование ассемблеров Intel 80X86 – MASM и TASM.
Формат оператора ассемблера.
метка: операция операнд(ы); комментарий
Имеем дело с командой, которая выполняется на этапе выполнения программы.
имя директива операнд(ы); комментарий
Директива ассемблера; выполняется на этапе трансляции в объектный файл; команд не порождает.
Метка задает адрес данной команды в исполняемом файле или директивы в исходном тексте.
Операция – дейстие, выполняемое над операндами при выполнении программы.
Директива – действие над операндами при трансляции программы и генерации объектного файла.
Комментарий – пояснение к тексту программы, при трансляции не рассматривается.
Процесс обработки ассемблерной программы можно пояснить с помощью схемы:


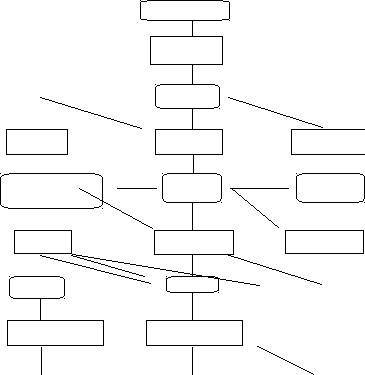
Директивы ассемблера
1. Директивы задания данных
Директива определения имен
a) имя EQU выражение
Например
N EQU 100h
TABLE EQU DS:[BP][SI]
MINS_DAY EQU 60*24
b) имя = выражение
Это имя может переопределяться и использоваться только для числовых выражений.
Директива выделения памяти
идентификатор D* список значений
где D* ода из приведенный ниже псевдокоманд:
DB- определить байт;
DW- определить слово;
DD- определить двойное слово;
DQ- определить учетверенное слово;
DT- определить десять байт;
DF- определить шесть байт.
Данная директива позволяет зарезервировать в памяти указанную область и приписать или не приписывать ей определенного значения. Например
text_string db ‘Hello world’
b_max db 255
b_min db -128
rez_w dw ?
rez_tab dw 20dup(?)
b_tab db 4dup(?),8,5,4dup(1)
fl_num dd 5.03E-2
2. Директивы сегментации программы
Два способа задания сегментов в программе.
2.1. Полное описание сегментов
2.1.1. Определение сегмента
имя_сегмента SEGMENT атрибуты
тело сегмента
имя_сегмента ENDS
Пример
dat_s1 segment byte public ‘data’
a db ?
dat_s1 ends
Атрибуты:
ReadOnly- сегмент доступен только для чтения; при попытки записи в этот сегмент MASM выдаст сообщение об ошибке.
Атрибут выравнивания- указывает ассемблеру и компоновщику, с какого адреса может начинаться сегмент.
BYTE- с любого адреса.
WORD- с четного адреса.
DWORD- с адреса, кратного 4.
PARA- с адреса, кратного 16 (установлен по умолчанию).
PAGE- с адреса, кратного 256.
Атрибут группирования, комбинирования.
PUBLIC- конкатенация (присоединение частей сегментов друг к другу).
COMMON- размещение сегментов данного класса с одного адреса (для сегментов кода и оверлейных программ).
PRIVATE- сегмент с таким атрибутом не объединяется с другими сегментами (значение по умолчанию).
Атрибут типа данных.
USE16- сегмент работает с 16 битными данными.
USE32- сегмент работает с 32 битными данными.
Атрибут класса- это любая метка, взятая в одинарные кавычки. Этот атрибут влияет на расположение сегментов в скомпонованной программе.
2.1.2. Связь сегментов с соответствующими сегментными регистрами.
ASSUME {регистр_сегментный: имя_сегмента,…}
Обычно эта директива идет вслед за сегментом кода.
Пример
assume cs: code_s, ds: d_seg,
ss: stack, es: nothing
NOTHING- не устанавливать связь или отменить ее, если она была установлена.
2.1.3.Загрузка начальных адресов сегментов в соответствующие регистры.
mov ax, seg d_seg ; seg- не обязательный оператор
mov ds, ax
2.2. Сокращенное описание сегментов.
При таком описании требуется обязательное задание модели памяти, в условиях которой используется данная программа.
.MODEL тип_модели_памяти
Эта директива накладывает ограничения на комбинирование сегментов
|
Модель |
Тип доступа к коду |
Тип доступа к данным |
Сегментные регистры |
Примечания |
|
TINY |
Near |
Near |
(cs)=DGroup (ds)=(ss)=DGroup |
.com |
|
SMALL |
Near |
Near |
(cs)=_Text (ds)=(ss)=DGroup |
.exe |
|
MEDIUM |
Far |
Near |
(cs)=<имя_сегмента>_Text (ds)=(ss)=DGroup |
|
|
LARGE |
Far |
Far |
(cs)=<имя_сегмента>_Text (ds)=(ss)=DGroup |
|
|
HUGE |
Far |
Far |
|
|
.CODE- директива описания сегмента кода; эта запись аналогична
_TEXT SEGMENT Word Public ‘CODE’
или
<имя_сегмента> _TEXT Word Public ‘CODE’
для модели памяти выше MEDIUM
.DATA
_DATA SEGMENT Word Public ‘DATA’
.STACK
STACK SEGMENT Para Public ‘STACK’
.CONST
CONST SEGMENT Word Public ‘CONST’
.DATA?
_BSS SEGMENT Word Public ‘BBS’
Отличие от полного описания сегментов заключается в отсутствии директивы ENDS. Таким образом, в результате создаются предопределенные переменные, которые содержат начальные адреса сегментов: @Code, @Data, @Stack, @Const, @BBS. Следовательно можно написать:
mov ax, @data
mov ds, ax