

ШинаAgp
Она имеет следующие существенные отличия от шины PCI:
шина способна передавать два блока данных за один 66 MHz цикл (AGP 2x);
устранена мультиплексированность линий адреса и данных (напомню, что в PCI для удешевления конструкции адрес и данные передавались по одним и тем же линиям);
дальнейшая конвейеризация операций чтения/записи, по мнению разработчиков, позволяет устранить влияние задержек в модулях памяти на скорость выполнения этих операций.
В результате пропускная способность шины была оценена в 500 МВ/сек, и предназначена она для того, чтобы видеокарты хранили текстуры в системной памяти, соответственно имели меньше памяти на плате, и, соответственно, дешевели (рис.3).
Р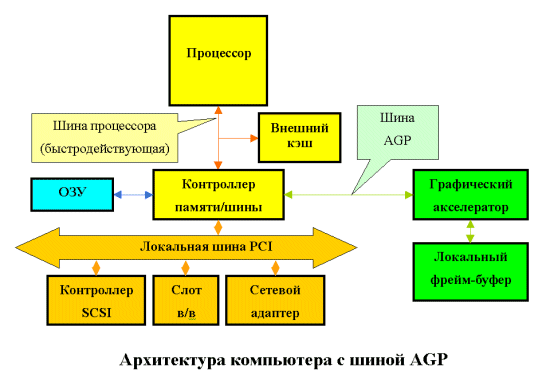 ис.
3. Архитектура компьютера с шинойAGP.
ис.
3. Архитектура компьютера с шинойAGP.
Парадокс в том, что видеокарты все-таки предпочитают иметь БОЛЬШЕ памяти, и ПОЧТИ НИКТО не хранит текстуры в системной памяти, поскольку текстур такого объема пока (подчеркиваю - пока) практически нет. При этом в силу удешевления памяти вообще, карты особенно и не дорожают.
Шина имеет два основных режима работы: Execute и DMA. В режиме DMA основной памятью является память карты. Текстуры хранятся в системной памяти, но перед использованием (тот самый execute) копируются в локальную память карты. Таким образом, AGP действует в качестве "тыловой структуры", обеспечивающей своевременную "доставку патронов" (текстур) на передний край (в локальную память). Обмен ведется большими последовательными пакетами.
В режиме Execute локальная и системная память для видеокарты логически равноправны. Текстуры не копируются в локальную память, а выбираются непосредственно из системной. Таким образом, приходится выбирать из памяти относительно малые случайно расположенные куски. Поскольку системная память выделяется динамически, блоками по 4К, в этом режиме для обеспечения приемлемого быстродействия необходимо предусмотреть механизм, отображающий последовательные адреса на реальные адреса 4-х килобайтных блоков в системной памяти. Эта нелегкая задача выполняется с использованием специальной таблицы (Graphic Address Re-mapping Table или GART), расположенной в памяти.
При этом адреса, не попадающие в диапазон GART (GART range), не изменяются и непосредственно отображаются на системную память или область памяти устройства (device specific range). На рис. 5 в качестве такой области показан локальный фрейм-буфер карты (Local Frame Buffer или LFB). Точный вид и функционирование GART не определены и зависят от управляющей логики карты.
Р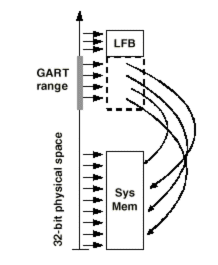 ис.
5. GART
ис.
5. GART
Шина AGP полностью поддерживает операции шины PCI, поэтому AGP-траффик может представлять собой смесь чередующихся AGP и PCI операций чтения/записи. Операции шины AGP являются раздельными (split). Это означает, что запрос на проведение операции отделен от собственно пересылки данных.
Такой подход позволяет AGP-устройству генерировать очередь запросов, не дожидаясь завершения текущей операции, что также повышает быстродействие шины.
В 1998 году спецификация шины AGP получила дальнейшее развитие - вышел Revision 2.0. В результате использования новых низковольтных электрических спецификаций появилась возможность осуществлять 4 транзакции (пересылки блока данных) за один 66-мегагерцовый такт (AGP 4x), что означает пропускную способность шины в 1GB/сек.
Однако потребности и запросы в области обработки видеосигналов все возрастают, и Intel готовит новую спецификацию - AGP Pro (в настоящее время доступен Revision 0.9) - направленную на удовлетворение потребностей высокопроизводительных графических станций. Новый стандарт не видоизменяет шину AGP. Основное направление - увеличение энергоснабжения графических карт. С этой целью в разъем AGP Pro добавлены новые линии питания.