

Организация ЭВМ и систем / 551-668
.pdfКонтрольные вопросы |
6 1 1 |
массива завершает свои вычисления и готов передатьданные соседу, он может это сделать, лишь когда последний будет готов к их приему. Для проверки готовности соседа передающий процессор сначала направляет ему запрос, а данные посылает только после получения подтверждения о готовности их принять. Такой механизм обеспечивает соблюдение заданной последовательности вычислений и делает прохождение фронта вычислений через массив плавным, причем задача соблюдения последовательности вычислений решается непосредственно, в то время как в систолических ВС для этого требуется строгая синхронизация.
Концепцию массива процессоров волнового фронта проиллюстрируем на примере матричного умножения (рис. 14.19).
Вычислительная система в примере состоит из процессорных элементов, имеющих на каждом входе данных буфер на один операнд. Всякий раз, когда буфер пуст, а в памяти, являющейся источником данных, содержится очередной операнд, производится немедленное его считывание в буфер соответствующего процессора. Операнды из других ПЭ принимаются на основе протокола связи с подтверждением.
Рисунок 14.19, а фиксирует ситуацию после первоначального заполнения входных буферов. Здесь ПЭ(1,1) суммирует произведение а х е с содержимым своего аккумулятора и транслирует операнды а и е своим соседям. Таким образом, первый волновой фронт вычислений (см. рис. 14.19,6) перемещается в направлении от ПЭ(1,1) к ПЭ(1,2) иПЭ(2,1).Рисунок 14.19, в иллюстрирует продолжение распространения первого фронта и исход от ПЭ(1,1) второго фронта вычислений.
По сравнению с систолическими ВС массивы волнового фронта обладают лучшей масштабируемостью, проще в программировании и характеризуются более высокой отказоустойчивостью.
Контрольные вопросы
1.По какому признаку вычислительную систему можно отнести к сильно связанным или слабо связанным ВС?
2.Какие уровни параллелизма реализуют симметричные мультипроцессорные системы?
3.Какими средствами поддерживается когерентность кэш-памяти в SMP-систе- мах?
4.Оцените достоинства и недостатки различных SMP-архитектур.
5.В чем состоит принципиальное различие между матричными и симметричными мультипроцессорными вычислительными системами?
6.Какие две проблемы призвана решить кластерная организация вычислительной системы?
7.Существуют ли ограничения на число узлов в кластерной ВС? И если существуют, то чем они обусловлены?
8.Какие задачи в кластерной вычислительной системе возлагаются на специализированное (кластерное) программное обеспечение?

6 1 2 Глава 14. Вычислительные системы класса MIMD
9.Каким образом может быть организовано взаимодействие между узлами кластерной ВС?
10.При каком количестве процессоров ВС можно отнести к системам с массовой параллельной обработкой?
11.Как организуется координация процессоров и распределение между ними заданий в МРР-системах?
12.Какие топологии можно считать наиболее подходящимидля МРР-систем и почему?
13.Поясните назначениесправочникав вычислительныхсистемах типа CC-NUMA.
14.Какие протоколы когерентности, на ваш взгляд, наиболее подходят для ВС, построенных на технологии CC-NUMA?
15.Какие черты транспьютера отличают его от стандартной однокристальной ВМ?
16.Какими аппаратными и программными средствами поддерживается взаимодействие соседних транспьютеров в вычислительной системе?
17.Сколько линий поддерживает канал связи транспьютера, какони используются и в каком режиме осуществляется ввод/вывод?
18.Какие особенности транспьютеров облегчает реализовать язык Occam?
19.Опишите структуру пакета данных и пакета подтверждения, передаваемых в транспьютерных ВС.
20.Какие из рассмотренных типов вычислительных систем могут быть построены на базе транспьютеров и в каких случаях это наиболее целесообразно?
21.В чем состоят сходство и различие между систолическими ВС и вычислительными системами с обработкой по принципу волнового фронта?
22.Как организуется межпроцессорный обмен в массивах волнового фронта?

Глава15
Потоковые и редукционные вычислительные системы
В традиционных ВМ команды в основном выполняются в естественной последовательности, то есть в том порядке, в котором они хранятся в памяти. То же самое можно сказать и о традиционных многопроцессорных системах, где одновременно могут выполняться несколько командных последовательностей, но также в порядке размещения каждой из них в памяти. Это обеспечивается наличием в каждом процессоре счетчика команд. Выполнение команд в каждом процессоре — поочередное и потому достаточно медленное. Для получения выигрыша программист или компилятор должны определить независимые команды, которые могут быть поданы на отдельные процессоры, причем так, чтобы коммуникационные издержки были не слишком велики.
Традиционные (фон-неймановские) вычислительные системы, управляемые с помощью программного счетчика, иногда называют вычислительными системами,управляемымипоследовательностью команд(control flowcomputer).Данный термин особенно часто применяется, когда нужно выделить этот тип ВС из альтернативных типов, где последовательность выполнения команд определяется не центральным устройством управления со счетчиком команд, а каким-либо иным способом. Если программа, состоящая из команд, хранится в памяти, возможны следующие альтернативные механизмы ее исполнения:
-команда выполняется, после того как выполнена предшествующая ей команда последовательности;
-команда выполняется, когда становятся доступными ее операнды;
-команда выполняется, когда другим командам требуется результат ее выполнения.
Первый метод соответствует традиционному механизму с управлением последовательностью команд; второй механизм известен какуправляемый данными (data driven) илипотоковый (dataflow);третий метод называютмеханизмомуправления по запросу (demand driven).

6 1 4 Глава 15. Потоковые и редукционные вычислительные системы
Общие идеи нетрадиционных подходов к организации вычислительного процесса показаны на рис. 15.1, а их более детальному изложению посвящен текущий раздел-
Рис.15.1.Возможныевычислительныемодели:а—фон-неймановская;б—потоковая; в — макропотоковая; г—редукционная
Вычислительныесистемысуправлением вычислениямиотпотокаданных
Идеология вычислений, управляемых потоком данных (потоковой обработки), была разработана в 60-х гадах Карпом и Миллером. В начале 70-х годов Деннис, а позже и другие начали разрабатывать компьютерные архитектуры, основанные на вычислительной модели с потоком данных.
Вычислительная модель потоковой обработки
В потоковой вычислительной модели для описания вычислений используется ориентированный граф, иногда называемый графом потоков данных (dataflow graph). Этот граф состоит из узлов или вершин, отображающих операции, и ребер или дуг, показывающихпотокиданныхмеждутеми вершинами графа, которыеонисоединяют.
Узловые операции выполняются, когда по дугам в узел поступила вся необходимая информация. Обычно узловая операция требует одного или двух операндов, а для условных операции необходимо наличие входного логического значения. По выполнении операции формируются один или два результата. Таким образом, у каждой вершины может быть от одной до трех входящих дуг и одна или две выходящих. После активации вершины и выполнения узловой операции (это иногда называют инициированием вершины) результаты передаются по ребрам к ожидающим вершинам. Процесс повторяется, пока не будут инициированы все вершины и получен окончательный результат. Одновременно может быть инициировано несколько узлов, при этом параллелизм в вычислительной модели выявляется автоматически.

Вычислительные системы суправлением вычислениями отпотокаданных 6 1 5
Рис.15.2. ГрафпотоковданныхдлявыраженияА/B+ВхС
Нарис. 15.2 показан простой потоковый графдля вычисления выражения f=А/В+ + В x С. Входами служат переменные А, В и С, изображенные вверху графа. Дуги между вершинами показывают тракты узловых операций. Направление вычислений — сверху вниз. Используются три вычислительные операции: сложение, умножение и деление. Заметим, что В требуется в двух узлах. Вершина «Копирование»- предназначена для формирования дополнительной копии переменной В.
Данные (операнды/результаты), перемещаемые вдоль дуг, содержатся в опознавательных информационных кадрах, маркерах специального формата — «токенах» (иначе «фишках»- или маркерах доступа). Рисунок 15.3 иллюстрирует движение токенов между узлами. После поступления на граф входной информации маркер, содержащий значение А, направляется в вершину деления; токен с переменной В — в вершину копирования; токен с переменной С — в вершину умножения. Активирована может быть только вершина «Копирование», поскольку у нее лишь один вход и на нем уже присутствует токен. Когда токены из вершины «Копирование*' будут готовы, узлы умножения и деления также получат все необходимые маркеры доступа и могут быть инициированы. Последняя вершина ждет завершения операций умножения и деления, то есть когда на ее входе появятся все необходимые токены.
Практические вычисления требуют некоторых дополнительных возможностей, например при выполнении команд условного перехода. По этой причине в потоковых графах предусмотрены вершины-примитивы нескольких типов (рис. 15.4):

6 1 6 Глава 15. Потоковые и редукционные вычислительные системы
Рис.15.3.ДвижениемаркеровпривычисленииА/В+ВхС:а—послеподачивходныхданных; б—послекопирования;в—послеумноженияиделения;г—послесуммирования
-двухвходовая операционная вершина — узел с двумя входами и одним выходом. Операции производятся над данными, поступающими с левой и правой входных дуг, а результат выводится через выходную дугу;
-одновходовая операционная вершина — узел с одним входом и одним выходом. Операции выполняются над входными данными, результат выводится через выходное ребро;
-вершина ветвления — узел с одним входом и двумя выходами. Осуществляет копирование входных данных и их вывод через две выходные дуги. Путем комбинации таких узлов можно строить вершины ветвления на т выходов;
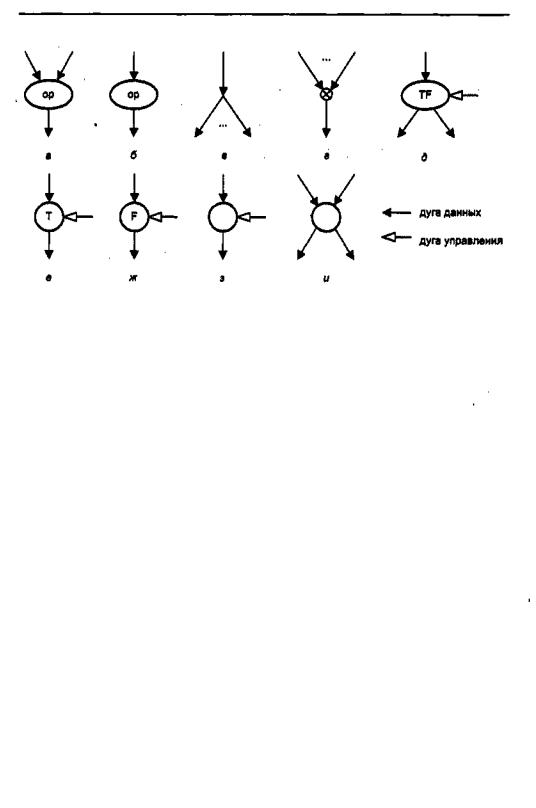
Вычислительные системы с управлением вычислениями от потока данных 6 1 7
Рис. 15.4. Примитивы узлов: а — двухвходовая операционная вершина; б — одновходовая операционная вершина; в— вершинаветвления; г— вершинаслияния; д — TF-коммутатор;
е— Т-коммутатор; ж — F-коммутатор; з — вентиль; и — арбитр
-вершина слияния — узел с двумя входами и одним выходом. Данные поступают только с какого-нибудь одного из двух входов. Входные данные без изменения подаются на выход. Комбинируя такие узлы, можно строить вершины слияния
ст входами;
-вершина управления — существует в перечисленных ниже трех вариантах:
-TF-коммутатор — узел с двумя входами и одним выходом. Верхний вход — это дуга данных, а правый — дуга управления (логические данные). Если значение правого входа истинно (Т — True), то входные данные выводятся через левый выход, а при ложном значении на правом входе (F — False) данные следуют через правый выход;
D вентиль — узел сдвумя входами и одним выходом. Верхний вход — дугаданных, а правый — дуга управления. При истинном значении на входе управления данные выводятся через выходную дугу;
-арбитр — узел с двумя входами и двумя выходами. Все дуги являются дугами данных. Первые поступившие от двух входов данные следуют через левую дугу, а прибывшие впоследствии — через правую выходную дугу. Активация вершины происходит в момент прихода данных с какого-либо одного входа.
Процесс обработки можетвыполняться аналогично конвейерному режиму: после обработки первого набора входных сигналов на вход графа может быть подан второй и т. д. Отличие состоит в том, что промежуточные результаты (токены) первого вычисления не обрабатываются совместно с промежуточными результатами второго и последующих вычислений. Результаты обычно требуются в последовательности использования входов.
Существует множество случаев, когда определенные вычисления должны повторяться с различными данными, особенно в программных циклах. Программ-

618 Глава 15. Потоковые и редукционные вычислительные системы
мые циклические процессы в типовых языках программирования могут быть воспроизведены путем подачи результатов обратно на входные узлы. При формировании итерационного кода часто применяются переменные цикла, увеличиваемые после каждого прохода тела цикла. Последний завершается, когда переменная цикла достигает определенного значения. Метод применим и при потоковой обработке, как это показано на рис. 15.5.
Рис. 15.5.Циклыприпотоковойобработке
Все известные потоковые вычислительные системы могут быть отнесены к двум основным типам: статическим и динамическим. В свою очередь, динамические потоковые ВС обычно реализуются по одной из двух схем: архитектуре с помеченнымитокенамииархитектуресявноадресуемымитокенами.
Архитектурапотоковыхвычислительныхсистем
В потоковых ВС программа вычислений соответствует потоковому графу, который хранится в памяти системы в виде таблицы. На рис. 15.6 показаны пример графа потоковой программы и содержание адекватной ему таблицы [2].
Принципиальная схема потоковой вычислительной системы (рис. 15.7) включает в себя блок управления (CS), где хранится потоковый граф, который используется для выборки обрабатываемых команд, а также функциональный блок (FS), выполняющий команду, переданную из CS, и возвращающий результат ее выполнения в CS.
Блоки CS и FS работают асинхронно и параллельно, обмениваясь многочисленными пакетами команд и результатами их выполнения. В пакетерезультата, поступающем из блока FS, содержится значение результата (val) и адрес команды, для которой пакет предназначен (des). Наосновании этого адреса блок CS проверяет возможность обработки команды. Команда может быть однооперандной или двухоперандной. В последнем случае необходимо подтверждение наличия обоих

Вычислительные системы с управлением вычислениями от потока данных 6 1 9
Рис.15.6.Примерформыхраненияпотоковойпрограммы:а—потоковыйграф; б — память функционального блока
Рис.15.7.Структурапотоковойвычислительнойсистемы
операндов (орг 1 и орг 2), и для этого устанавливается специальный признак. Блок управления загрузкой (LC) каждый раз при активировании определенной функции загружает из памяти программ код этой функции.
Для повышения степени параллелизма блоки CS и F5 строятся по модульному принципу, а графы потоковой программы распределяются между модулями с помощью мультиплексирования [89].

6 2 0 Глава 15. Потоковыеи редукционныевычислительные системы
Статические потоковые вычислительные системы
Статическаяпотоковаяархитектура,известнаятакжеподназванием«единствен- ный-токен-на-дугу» (single-token-рег-агс dataflow), была предложена Деннисом в 1975 году [89]. В ней допускается присутствие на ребре графа не более чем одного токена. Этовыражаетсяв правилеактивацииузла [90]: вершинаактивируется,когда на всех ее входных дугах присутствуетпотокену и ни на одном из ее выходовтокенов нет. Для указания вершине о том, что ее выходной токен уже востребован последующим узлом (узлами) графа, в ВС обычно прибегают к механизму подтверждения с квитированием связи, как это показано на рис. 15.8. Здесь процессорами в ответ на инициирование узлов графа посылаются специальные контрольные токены.
Рис. 15.8. Механизмподтверждениясквитированием
Типовую статическую потоковую архитектуру иллюстрирует рис. 15.9.
Рис. 15.9, Структура процессорногоэлементетиповойстатической потоковойсистемы
Память действий (узел потоковой машины, хранящий потоковый граф и циркулирующий на нем поток данных) состоит их двух блоков памяти: команд/данных и управляющей памяти. Вершина графа представлена в памяти команд/данных кадром, содержащим следующие поля:
-код операции;
-операнд 1;