

Организация ЭВМ и систем / 551-668
.pdfАссоциативные вычислительные системы 5 7 1
Объединение реализуется за счет операций арифметического и логического сложения, наложения записей, нахождения меньшего и большего из двух значений. В некоторых SIMD-системах, например МР-1, имеется возможность записать одновременно пришедшие сообщения в разные ячейки локальной памяти.
Хотя пересылки данных по сети инициируются только активными ПЭ, пассивные процессорные элементы также вносят вклад в эти операции. Если активный ПЭ инициирует чтение издругого ПЭ, операция выполняется вне зависимости от статуса ПЭ, из которого считывается информация. То же самое происходит и при записи.
Наиболее распространенными топологиями в матричных системах являются решетчатые и гиперкубические. Так, в ILLIAC IV, МРР и СМ-2 каждый ПЭ соединен с четырьмя соседними. В МР-1 и МР-2 каждый ПЭ связан с восьмью смежными ПЭ. В ряде систем реализуются многоступенчатые динамические сети соединений (МР-1, МР-2, GF11).
Ввод/вывод
Хотя программа вычислений хранится в памяти интерфейсной ВМ или иногда в КМП, входные и выходные данные процессорных элементов и КМП могут храниться также на внешних ЗУ. Такие ЗУ могут подключаться к массиву процессоров и/или КМП посредством каналов ввода/вывода или процессоров ввода/вывода.
Ассоциативные вычислительные системы
К классу SIMD относятся и так называемые ассоциативные вычислительные системы. В основе подобной ВС лежит ассоциативное запоминающее устройство (см.главу5),аточнее—ассоциативныйпроцессор,построенныйнабазетакогоЗУ. Напомним, что ассоциативная память (или ассоциативная матрица) представляет собой ЗУ, где выборка информации осуществляется не по адресу операнда, а по отличительным признакам операнда. Запись в традиционное ассоциативное ЗУ также производится не по адресу, а в одну из незанятых ячеек.
Ассоциативныйпроцессор(АП)можноопределитькакассоциативнуюпамять, допускающую параллельную запись во все ячейки, для которых было зафиксировано совпадение с ассоциативным признаком. Эта особенность АП, носящая название мулътизаписи, является первым отличием ассоциативного процессора от традиционной ассоциативной памяти. Считывание и запись информации могут производиться по двум срезам запоминающего массива — либо это все разряды одного слова, либо один и тот же разряд всех слов. При необходимости выделения отдельных разрядов среза лишние позиции допустимо маскировать. Каждый разряд среза в АП снабжен собственным процессорным элементом, что позволяет между считыванием информации и ее записью производить необходимую обработку, то есть параллельно выполнять операции арифметического сложения, поиска, а также эмулировать многие черты матричных ВС, таких, например, как ILLIAC IV.
Такимобразом,ассоциативныеВСилиВСсассоциативным процессором есть не что иное, как одна из разновидностей параллельных ВС, в которых п процес-

5 7 2 Глава 13. Вычислительные системы класса SIMD
сорных элементов ПЭ (вертикальный разрядный срез памяти) представляют собой простые устройства, как правило, последовательной поразрядной обработки. При этом каждое слово (ячейка) ассоциативной памяти имеет свое собственное устройство обработки данных (сумматор). Операция осуществляется одновременно всеми п ПЭ. Все или часть элементарных последовательных ПЭ могут синхронно выполнять операции над всеми ячейками или над выбранным множеством слов ассоциативной памяти.
Время обработки Nm-разрядных слов в ассоциативной ВС определяется выражением:
где t — время цикла ассоциативной памяти; п — число ячеек ассоциативной системы; К — коэффициент сложности выполнения элементарной операции (количество последовательных шагов, каждый из которых связан с доступом к памяти).
Вычислительные системы с систолической структурой
В фон-неймановских машинах данные, считанные из памяти, однократно обрабатываются в процессорном элементе, после чего снова возвращаются в память (рис. 13.14 а). Авторы идеи систолической матрицы Кунг и Лейзерсон предложили организовать вычисления так, чтобы данные на своем пути от считывания из памяти до возвращения обратно пропускались через как можно большее число ПЭ (рис. 13.14,6).
а |
6 |
Рис. 13.14. Обработка данных в ВС: а — фон-неймановского типа; б — систолической структуры
Если сравнить положение памяти в ВС со структурой живого организма, то по аналогии ей можно отвести роль сердца, множеству ПЭ — роль тканей, а поток данных рассматривать как циркулирующую кровь. Отсюда и происходит название систолическаяматрица (систола — сокращение предсердий и желудочков сердца при котором кровь нагнетается в артерии). Систолические структуры эффективны при выполнении матричных вычислений, обработке сигналов, сортировке данных и т. д. В качестве примера авторами идеи был предложен линейный массив для алгоритма матричного умножения, показанный на рис. 13.15.
В основе схемы лежит ритмическое прохождение двух потоков данных xi и уi, навстречу друг другу. Последовательные элементы каждого потока разделены одним тактовым периодом, чтобы любой из них мог встретиться с любым элементом встречного потока. Если бы они следовали в каждом периоде, то элемент xi никогда

Вычислительныесистемы с систолическойструктурой 5 7 3
Рис. 13.15. Процесс векторного умножения матриц (n = 4)
бы не встретился с элементамиy yi+l, yi+3... Вычисления выполняются параллельно в процессорных элементах, каждый из которых реализует один шаг в операции вычисления скалярного произведения (IPS, Inner Product Step) и носит название
IPS-элемента(рис.13.16).
Рис. 13.16. Функциональная схема IPS-элемента
Значение унх, поступающее на вход ПЭ, суммируется с произведением входных
значений хвх и aвх. Результат выходит из ПЭ как уВЪ1Х. Значение хвх, кроме того, для возможного последующего использования остальной частью массива транслиру-
ется через ПЭ без изменений и покидает его в виде хвых.
Таким образом, систолическая структура — это однородная вычислительная среда из процессорных элементов, совмещающая в себе свойства конвейерной и матричной обработки и обладающая следующими особенностями:
-вычислительный процесс в систолических структурах представляет собой непрерывную и регулярную передачу данных от одного ПЭ к другому без запоминания промежуточных результатов вычисления;

5 7 4 Глава 13. Вычислительные системы класса SIMD
-каждый элемент входных данных выбирается из памяти однократно и используется столько раз, сколько необходимо по алгоритму, ввод данных осуществляется в крайние ПЭ матрицы;
-образующие систолическую структуру ПЭ однотипны и каждый из них может быть менее универсальным,чем процессоры обычных многопроцессорных систем;
-потоки данных и управляющих сигналов обладают регулярностью, что позволяет объединять ПЭ локальными связями минимальной длины;
-алгоритмы функционирования позволяют совместить параллелизм с конвейерной обработкой данных;
-производительность матрицы можно улучшить за счет добавления в нее определенногочислаПЭ,причемкоэффициентповышенияпроизводительностипри этом линеен.
Внастоящее время достигнута производительность систолических процессоров порядка 1000 млрд операций/с.
Классификация систолических структур
Анализ различных типов систолических структур и тенденций их развития позволяет классифицировать эти структуры по нескольким признакам.
По степени гибкости систолические структуры могут быть сгруппированы на:
-специализированные;
-алгоритмически ориентированные;
-программируемые.
Специализированныеструктуры ориентированы на выполнение определенного алгоритма. Эта ориентация отражается не только в конкретной геометрии систолической структуры, статичности связей между ПЭ и числе ПЭ, но и в выборе типа операции, выполняемой всеми ПЭ. Примерами являются структуры, ориентированные на рекурсивную фильтрацию, быстрое преобразование Фурье для заданного количества точек, конкретные матричные преобразования.
Алгоритмически ориентированные структуры обладают возможностью программирования либо конфигурации связей в систолической матрице, либо самих ПЭ. Возможность программирования позволяет выполнять на таких структурах некоторое множество алгоритмов, сводимых к однотипным операциям над векторами, матрицами и другими числовыми множествами.
В программируемых систолических структурах имеется возможность программирования как самих ПЭ, так и конфигурации связей между ними. При этом ПЭ могут обладать локальной памятью программ, и хотя все они имеют одну и ту же организацию, в один и тот же момент времени допускается выполнение различных операций изнекоторогонабора. Команды илиуправляющиеслова, хранящиеся в памяти программ таких ПЭ, могут изменять и направление передачи операндов.
Поразрядностипроцессорныхэлементовсистолическиеструктурыделятсяна:
-одноразрядные;
-многоразрядные.

Вычислительные системы с систолической структурой 5 7 5
В одноразрядных матрицах ПЭ в каждый момент времени выполняет операцию над одним двоичным разрядом; а в многоразрядных — над словами фиксированной длины.
По характерулокально-пространственных связей систолические структуры бывают:
-одномерные;
-двухмерные;
-трехмерные.
Выбор структуры зависит от вида обрабатываемой информации. Одномерные схемы применяются при обработке векторов, двухмерные — матриц, трехмерные — множеств иного типа.
Топология систолических структур
В настоящее время разработаны систолические матрицы с различной геометрией связей: линейные, квадратные, гексагональные, Трехмерные и др. Перечисленные конфигурации систолических матриц приведены на рис. 13.17.
Рис. 13.17. Конфигурация систолических матриц: а — линейная; б— прямоугольная; в — гексагональная; г — трехмерная
Каждая конфигурация матрицы наиболее приспособлена для выполнения определенных функций, например линейная матрица оптимальна для реализации фильтров в реальном масштабе времени; гексагональная — для выполнения операций обращения матриц, а также действий над матрицами специального вида (Теплица-Генкеля); трехмерная — для нахождения значений нелинейных дифференциальных уравнений в частных производных или для обработки сигналов антенной решетки. Наиболее универсальными и наиболее распространенными, тем не менее, можно считать матрицы с линейной структурой.
Для решения сложных задач конфигурация систолической структуры может представлять собой набор отдельных матриц, сложную сеть взаимосвязанных мат-

5 7 6 Глава 13. Вычислительные системы класса SIMD
рицлибообрабатывающуюповерхность. Подобрабатывающей поверхностьюпонимается бесконечная прямоугольная сетка ПЭ, где каждый ПЭ соединяется со своими четырьмя соседями (или большим числом ПЭ). Одним из наиболее подходящих элементов для реализации обрабатывающей поверхности является матрица простых ПЭ или транспьютеров.
Учитывая то, что матрицы ПЭ обычно реализуются на основе сверхбольших интегральных схем, возникающие при этом ограничения привели к тому, что наиболее распространены матрицы с одним, двумя и тремя трактами данных и с одинаковым либо противоположным направлением передачи, обозначаемые как ULA, BLA и TLA соответственно.
ULA(Unidirectional Linear Array) — это однонаправленный линейный процессорный массив, где потоки данных перемещаются в одном направлении. ПЭ в массиве могут быть связаны одним, двумя или тремя трактами.
Рис. 13.18. Поток данных при векторном перемножении матрице ULA (n = 4)
При реализации алгоритма векторного произведения матриц один из потоков данных перемещается вправо, в то время как второй резидентно расположен в массиве (рис. 13.18). Используемый ПЭ представляетсобоймодифицированный IPSэлемент, поскольку имеется только один тракт данных, а элементы второго потока хранятся в ПЭ массива.
BLA (Bidirectional Linear Array) — это двунаправленный линейный процессорный массив, в котором два потока данных движутся навстречу друг другу. BLA, где один из потоков является выходным, называется регулярным.
Рис. 13.19. Поток данных при векторном перемножении матриц в BLA(n= 4)
Реализация рассмотренной ранее операции с применением BLA показана на рис. 13.19. В версии ULA процессоры используются более эффективно, поскольку в них элементы потока следуют в каждом такте, а не через такт, как в BLA.
TLA (Three-path communication Linear Array) — линейный процессорный массив с тремя коммуникационными трактами, в котором по разным направлениям перемещаются три потока данных. На рис. 13.20 показан пример фильтра ARMA, предложенного Кунгом и построенного по схеме TLA. Возможны несколько вариантов такого фильтра, в зависимости от числа выходных потоков данных и от зна-

Вычислительныесистемыссистолической структурой 5 7 7
чений, хранящихся в памяти (в примере фигурирует один выходной поток). Процессорные элементы выполняют две операции IPS и обычно называются сдвоен- ными1РS-элементами,Две версии таких ПЭ представлены на рис, 13.21. ПЭ могут использовать как хранимые в памяти значения (рис. 13.21, а, б), так и внешние данные (рис. 13.21, в, г).
в г
Рис.13.21.СдвоенныеIPS-элементы:a-б—схранимымивпамятидвумязначениями; в-г—свнешнимиданными
TLA часто называют сдвоенным конвейером, поскольку он может быть разделен на два линейных конвейера типа BLA. Соответственно, TLA можно получить объединением двух BLA с одним общим потоком данных.
Представленные реализации алгоритма векторного произведения матриц выполняют эту операцию за одно и то же время, но в случае ULA в вычислениях участвуют вдвое меньше процессорных элементов. С другой стороны, ULA использует хранимые в памяти данные, на чтение и запись которых нужно какое-то время. В свою очередь, в схеме BLA требуется дополнительное время на операции ввода/ вывода.
Структура процессорных элементов
Тип ПЭ выбирается в соответствии с назначением систолической матрицы и структурой пространственных связей. Наиболее распространены процессорные элементы, ориентированные на умножение с накоплением.
На рис. 13.22 показаны ПЭ для двух типов матриц: прямоугольной (см. рис, 13.22, а) и гексагональной (см. рис. 13.22,6).

5 7 8 Глава 13. Вычислительные системы класса SIMD
а |
6 |
Рис. 13.22. Структура ПЭ:a—для прямоугольнойсистолической матрицы;
б— для гексагональной систолической матрицы
Вобоих случаях на вход ПЭ подаются два операнда Авх, Ввх, а выходят операнды Авых, Ввых, и частичная сумма Свых,. На n-м шаге работы систолической системы ПЭ выполняет операцию
на основе операндов, полученных на (n - 1)-м шаге, при этом операнды на входе и выходе ПЭ одинаковы:
Частичная сумма поступает на вход ПЭ либо с данного процессорного элемента (штриховая линия), либо с соседнего ПЭ матрицы.
Пример вычислений с помощью систолическогопроцессора
Организацию вычислительного процесса в систолических массивах различной конфигурации с использованием ПЭ, функциональная схема которого показана на рис. 13.23. удобнее всего пояснить на примере умножения матрицы А -(ay)на вектор 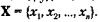
Рис. 13.23. Функциональная схема процессорного Элемента систолической матрицы

Вычислительныесистемыссистолической структурой 5 7 9
Элементы вектора произведения Y = {у1 , у2,..., уп) могут быть получены периодически повторяющимися операциями
где k - номер шага вычислений.
Пусть имеется матрица А размером пхп с шириной полосы ненулевых элементов р + q - 1 = 4. Схема умножения вектора на матрицу в этом случае представленанарис. 13.24.
Рис. 13.24. Схемаумножениявектора на матрицу
Определенная выше последовательность операций для вычисления компонентов вектора Y может быть получена за счет конвейерного прохождения хi и уi через р + q - 1 последовательно соединенных ПЭ (рис. 13.25)
Рис. 13.25. Организация вычислений в линейной систолической структуре
Компоненты yi (i - 1,...,n) вектора Y; имеющие в начальный момент нулевое значение, поступают на вход массива и продвигаются через ПЭ справа налево, в то время как компоненты вектораXдвижутсяслеванаправо. Элементы матрицыА = {aij} в порядке, указанном на рисунке, вводятся в ПЭ сверху вниз. Промежуточные результаты уi(k) накапливаются по мере продвижения от одного ПЭ к другому.

5 8 0 Глава 13. Вычислительные системы класса SIMD
В табл. 13.1 показаны первые 6 шаГов алгоритма умножения для рассматриваемой структуры.
Таблица 13.1. Последовательность умножения матрицы на вектор в систолической ВС
Заметим, что при такой организации вычислительного процесса для каждого ПЭ такты выполнения операции чередуются с тактами простоя. Таким образом,
в каждый момент времени активны только(p+q-1)/2процессорных элементов, следовательно, каждый выходной результат формируется за два такта. Для вычисления всех и элементов выходного вектора Y необходимо 2n + р + q - 1 тактов.
Вычислительные системы с командными словами сверхбольшой длины (VLIW)
Архитектураскоманднымисловамисверхбольшойдлиныилисосверхдлинными командами (VLIW, Very Long Instruction Word) известна с начала 80-х из ряда университетских проектов, но только сейчас, с развитием технологии производства микросхем она нашласвое достойное воплощение. VLIW — это набор команд, организованных наподобие горизонтальной микрокоманды в микропрограммном устройстве управления.
Идея VLIW базируется на том, что задача эффективного планирования параллельного выполнения нескольких команд возлагается на «разумный» компилятор. Такой компилятор вначале исследует исходную программу с целью обнаружить все команды, которые могут быть выполнены одновременно, причем так,