

Лекция 1.
Возникновение языка С


Кен Томпсон Денис Ритчи
Язык программирования Си был разработан в начале 1970-х годов сотрудниками лаборатории Bell Кеном Томпсоном и Денисом Ритчи для использования в создаваемой ими операционной системе Unix. Для выполнения работы по созданию Unix разработчики нуждались в таком языке программирования, который был бы кратким, а также мог бы обеспечивать эффективное управление аппаратными средствами, мог бы создавать компактные, быстро работающие программы.
Традиционно такие потребности программистов удовлетворял язык ассемблера, который тесно связан с внутренним машинным языком компьютера. Однако ассемблер — язык низкого уровня, т.е. он привязан к определенному типу процессора (или компьютера). Поэтому если программу на языке ассемблера необходимо перенести на компьютер другого типа, ее приходится переписывать заново на другом языке ассемблера. Это можно сравнить с ситуацией, когда при покупке нового автомобиля вы каждый раз обнаруживаете, что конструкторы решили изменить расположение и назначение органов управления, вынуждая вас заново переучиваться вождению.
Операционная система UNIX предназначалась для работы на компьютерах различных типов (или платформах). А это предполагало использование языка высокого уровня. Язык высокого уровня ориентирован на решение задач, а не на конкретное аппаратное обеспечение. Специальные программы, которые называются компиляторами, транслируют программу, написанную на языке высокого уровня, в команды внутреннего языка конкретного компьютера. Таким образом, используя отдельный компилятор для каждой платформы, одну и ту же программу на языке высокого уровня можно выполнять на разных платформах. Разработчики Unix нуждались в языке, который сочетал бы в себе эффективность и возможность доступа к аппаратным средствам, обеспечиваемые языками низкого уровня, с более общим характером и переносимостью, присущими языкам высокого уровня. Поэтому на основе имевшихся в то время более старых языков программирования Ритчи и Томпсоном был разработан язык С.
Функциональный базис языка С
Рассмотрим философию языка С. В общем случае язык программирования базируется на двух основных понятиях — это данные и алгоритмы. Данные представляют собой информацию, которую программа обрабатывает. А алгоритмы — это методы, которые программа использует (для обработки данных, см. рис.). Язык С, как и болыпинство основных языков программирования того времени, является процедурным — это означает, что основной акцент в нем делается на алгоритмах. Теоретически процедурное программирование заключается в том, что сначала определяется последовательность действий, которая должна быть выполнена компьютером, а затем эти действия реализуются с помощью языка программирования. Программа содержит набор процедур, которые компьютер должен выполнить, чтобы получить требуемый результат. Такая деятельность во многом напоминает кулинарный рецепт, который предписывает последовательность действий (процедур), необходимых для выпечки пирога. При использовании первых процедурных языков, таких как FORTRAN и BASIC, по мере увеличения объема программ пришлось столкнуться с проблемами организационного плана. Например, в программах часто используются операторы ветвления, которые в зависимости от результатов некоторой проверки направляют ход выполнения программы на тот или иной набор операторов. Во многих старых программах алгоритм настолько запутан, что его крайне сложно понять при чтении текста, а модификация такой программы чревата осложнениями. Чтобы решить эту проблему, компьютерщики разработали более упорядоченный стиль программирования, называемый структурным программированием. Язык С включает ряд элементов, облегчающих применение структурного программирования. Например, структурное программирование ограничивает возможности ветвления (выбора следующего выполняемого оператора) небольшим набором хорошо функционирующих конструкций. Эти конструкции (циклы for, while, do while и оператор if else) входят в словарь языка С.
Еще одним из новых принципов программирования было проектирование программ сверху вниз.
Идея заключается в разбиении большой программы на более мелкие, легче решаемые задачи. Если одна из этих задач по-прежнему остается слишком обширной, ее также следует разделить на более мелкие задачи. Этот процесс продолжается до тех пор, пока программа не будет разделена на маленькие, легко программируемые модули. (Рассмотрим пример. Есть просьба: наведите порядок в своем кабинете. Ой! Хорошо, наведите порядок в письменном столе, на столе и на своих книжных полках. Ох! Хорошо, начните с письменного стола и наведите порядок в каждом выдвижном ящике, начиная со среднего. Гм, с этой задачей я, пожалуй, могу справиться.) Язык С упрощает такой подход, поскольку "поощряет" программистов разрабатывать программные единицы (элементы), называемые функциями, которые представляют собой модули отдельных задач. Как можно было заметить, методика структурного программирования отражает процедурный подход, при котором программа рассматривается с точки зрения выполняемых ею действий.
Функциональный базис языка С++
Объектно-ориентированное программирование.
Хотя принципы структурного программирования позволили улучшить понятность и надежность программ, а также облегчить их сопровождение, создание программ больших размеров по-прежнему оставалось нелегкой задачей. Объектно-ориентированное программирование (ООП) предлагает новый подход к решению этой задачи. В отличие от процедурного программирования, где главное внимание уделяется алгоритмам, в ООП основной акцент делается на данных. При использовании ООП проблему решают не с помощью процедурного подхода, заложенного в языке, а приспосабливают язык для решения этой проблемы. Идея заключается в создании таких форм данных, которые соответствовали бы специфике задачи.
Спецификацией, описывающей подобную уникальную форму данных, в языке С++ является класс, а конкретной структурой данных, созданной в соответствии с этой спецификацией, — объект. Например, класс может описывать общие для всех руководящих работников корпорации свойства (имя, должность, оклад и, например, необычные способности), тогда как объект представляет конкретного руководителя (Василий Иванов, вице-президент компании, оклад 35 млн. руб. в год, знает как пользоваться программой «Блокнот»). В общем случае класс определяет, какие данные будут представлять объект и какие операции могут выполняться над этими данными. Предположим, мы разрабатываем графическую программу, способную рисовать прямоугольники. Можно создать класс, описывающий прямоугольник. Данными в спецификации этого класса могут служить: местоположение углов, высота и ширина, цвет и стиль линии границы, а также цвет и текстура заполнения площади прямоугольника. Часть спецификации этого класса, описывающая операции, может включать методы перемещения прямоугольника, изменения его размеров, вращения треугольника, изменения цветов и шаблонов, а также копирования прямоугольника в другое место. Если впоследствии использовать эту программу для рисования прямоугольника, то она создаст объект в соответствии со спецификацией класса. Данный объект будет содержать все значения данных, описывающих прямоугольник, а с помощью методов класса можно будет этот прямоугольник модифицировать. Если необходимо нарисовать два прямогольника, то программа создаст два объекта, по одному для каждого прямоугольника
Объектно-ориентированный подход к разработке программы состоит в том, что сначала разрабатываются классы, точно представляющие те вещи, с которыми имеет дело программа. В графической программе, например, можно определить классы для представления прямоугольников, линий, окружностей, кистей, перьев и т.п. После этого, используя объекты классов, можно приступать к разработке самой программы. Такой процесс продвижения от более низкого уровня организации (классы), к более высокому уровню (программа), называется программированием снизу вверх.
Объектно-ориентированное программирование — это не только объединение данных и методов в описании класса. При использовании ООП, например, упрощается создание повторно используемого кода программы, что в конечном итоге освобождает человека от большого объема работы. Сокрытие информации позволяет предохранить данные от нежелательного доступа. Полиморфизм дает возможность создавать множественные определения для операций и функций (а то, какое определение конкретно будет использоваться, зависит от контекста программы). Наследование позволяет создавать новые классы из старых. Как видим, в объектно-ориентированном программировании реализуется много новых идей и используется иной подход к созданию программ в сравнении с процедурным программированием. Основное внимание уделяется не алгоритмическому аспекту задач, а представлению понятий.
Разработка полезного и надежного класса может оказаться трудной задачей. К счастью, объектно-ориентированные языки дают возможность без особого труда включать в создаваемые программы уже существующие классы. Поставщики программного обеспечения разработали различные библиотеки классов, среди которых — библиотеки, предназначенные для упрощения создания программ в таких средах, как Windows или Macintosh. Одним из реальных преимуществ языка C++ является то, что он позволяет легко адаптировать и повторно использовать хорошо проверенные коды программ.
Язык программирования С++ также был детищем лаборатории Bell и был создан в начале 1980-х годов Бьярни Страуструпом.

Бьярни Страуструп
Методика создания программ на С++
Предположим, что вы написали программу на языке C++. Как обеспечить ее выполнение? Конкретные действия зависят от программной среды компьютера и от используемого компилятора C++. Но в общем случае вам будет необходимо выполнить следующие действия:
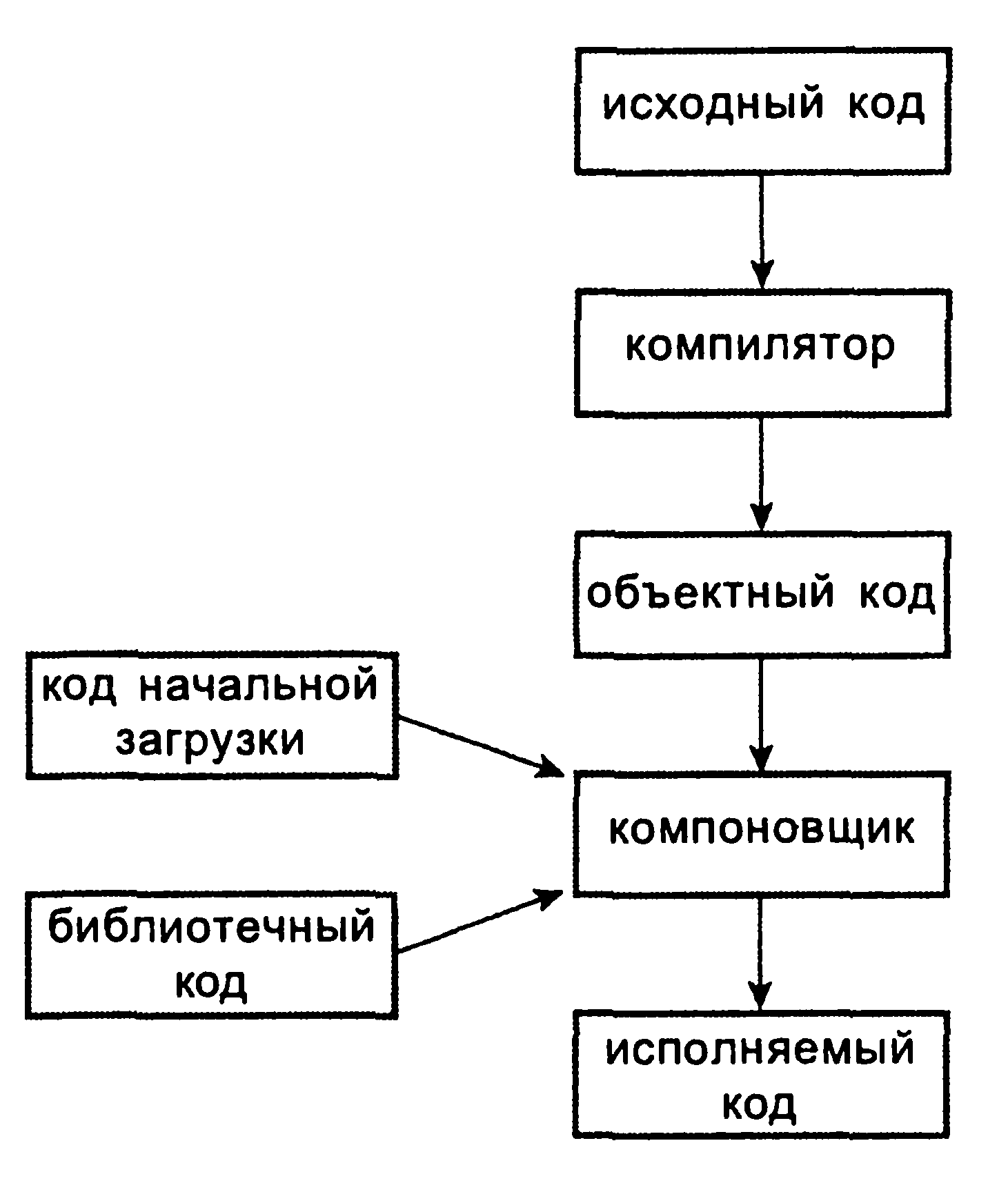
Воспользовавшись текстовым редактором, написать программу и сохранить ее в файле. Этот файл будет служить исходным кодом программы.
Скомпилировать исходный код. Это означает выполнение программы, которая транслирует исходный код во внутренний язык компьютера, называемый машинным языком. Файл, содержащий оттранслированную программу, — это объектный код программы.
Связать объектный код с дополнительным кодом и скомпоновать из них единую программу. Например, программы C++ обычно используют библиотеки. Библиотека C++ содержит совокупность объектных кодов компьютерных подпрограмм, называемых функциями, которые служат для выполнения таких задач, как отображение информации на экране или вычисление квадратного корня числа. При компоновке объектный код программы объединяется с объектными кодами функций, используемых программой, и определенным стандартным кодом начальной загрузки, в результате чего создается выполняемая версия программы. Файл, содержащий окончательный продукт, называется исполняемым кодом.
Типы данных в языке C++.
Общие понятия.
В языке С++ имеется две группы встроенных типов данных: базовые и составные или производные.
Для хранения в компьютере элемента информации программа должна отслеживать три его основных свойства; в частности, она определяет:
• где хранится информация
• какое значение там хранится
• вид хранящейся информации.
К примеру, в объявлении int i=5 имя i определяет значение переменной, равное 5. При этом это целочисленная переменная.
Правила именования переменных
Для переменных рекомендуется выбирать имена, отражающие их назначение. В именах можно использовать буквы алфавита, цифры и символ подчеркивания.
Первый символ не может быть цифрой.
Символы верхнего и нижнего регистров рассматриваются как разные.
В качестве имен нельзя использовать ключевые слова языка C++.
Не рекомендуется определять имена, начинающиеся с двух символов подчеркивания или с символа подчеркивания и следующей за ним буквы в верхнем регистре. Имена, начинающиеся с одного символа подчеркивания, зарезервированы для использования реализацией языка в качестве глобальных идентификаторов.
В языке C++ на длину имени не накладывается никаких ограничений, т.е. учитывается каждый символ имени.
Типы данных в языке C++.
Целочисленные типы данных
Целые числа — это числа без дробной части, например 2, 98, -5286 или 0. В некоторых языках, например Standard Pascal, существует только один тип целочисленных данных (один тип данных — для представления всех целых чисел), однако C++ включает несколько типов таких данных. Это позволяет программисту выбрать такой тип целочисленных данных, который лучше всего соответствует требованиям конкретной программы.
В языке C++ одни типы данных (со знаком) могут представлять и положительные, и отрицательные значения, тогда как другие типы данных (без знака) не могут представлять отрицательные значения.
Базовые типы целочисленных данных языка C++ именуются char, short, int и long. Каждый из этих типов данных подразделяется на две разновидности: со знаком и без знака. В результате программист имеет выбор из восьми различных типов целочисленных данных.
Тип |
Размерность (байт) |
Диапазон |
char |
1 |
от -128 до 127 |
unsigned char |
1 |
От 0 до 255 |
int |
2 |
от -32768 до 32767 |
unsigned int |
2 |
от 0 до 65535 |
short |
2 |
от -32768 до 32767 |
unsigned short |
2 |
от 0 до 65535 |
long |
4 |
от -2147483648 до 2147483647 |
unsigned long |
4 |
от 0 до 4294967295 |
Типы данных в языке C++
Булевский тип данных.
В программировании переменная Boolean — это переменная, которая может принимать два значения: true (истина) или false (ложь). Для представления булевских значений используется тип данных bool и предопределенные литералы true и false. Другими словами, допустимы операторы, подобные следующему:
bool bIsReady = true;
Типы данных в языке C++
Числа с плавающей точкой
Этот тип позволяет представлять числа с дробной частью.
В C++ имеется два способа записи чисел с плавающей точкой.
Первый — это стандартная запись чисел с десятичной точкой, которой мы обычно пользуемся:
12.34 // число с плавающей точкой
939001.32 // число с плавающей точкой
0.00023 // число с плавающей точкой
8.0 // также число с плавающей точкой
Даже если дробная часть равна 0, как в числе 8.0, наличие десятичной точки гарантирует, что число будет храниться в формате чисел с плавающей точкой, а не целых чисел
Второй способ записи чисел с плавающей точкой называется экспоненциальной формой записи или просто экспоненциальной записью, например: 3.45Е6. Эта запись означает, что число 3.45 умножается на 1000000; Е6 означает 10 в 6-й степени. Таким образом, запись 3.45Е6 соответствует числу 3450000. Здесь число 6 называется экспо-нентой, а 3.45 — мантиссой. Рассмотрим несколько примеров:
2.52е+8 // можно использовать Е или е, знак " + " необязателен
8.33Е-4 // экспонента может быть отрицательной
7Е5 // то же самое, что и 7.ОЕ+05
-18.32е13 // перед мантиссой может стоять знак "+" или "-"
2.857Е12 // государственный долг сша, 1989 г.
5.98Е24 // масса Земли в килограммах
9.11е-31 // масса электрона в килограммах
Экспоненциальная запись наиболее удобна для очень больших и очень маленьких чисел.
Экспоненциальная запись числа гарантирует, что число будет храниться в формате чисел с плавающей точкой, даже если десятичная точка отсутствует. Можно писать, как е, так и е, а экспонента может иметь знак "+" или "-". (см. рис.). Однако внутри числа недопустимы пробелы; так, запись является неверной: 7.2 Е6.
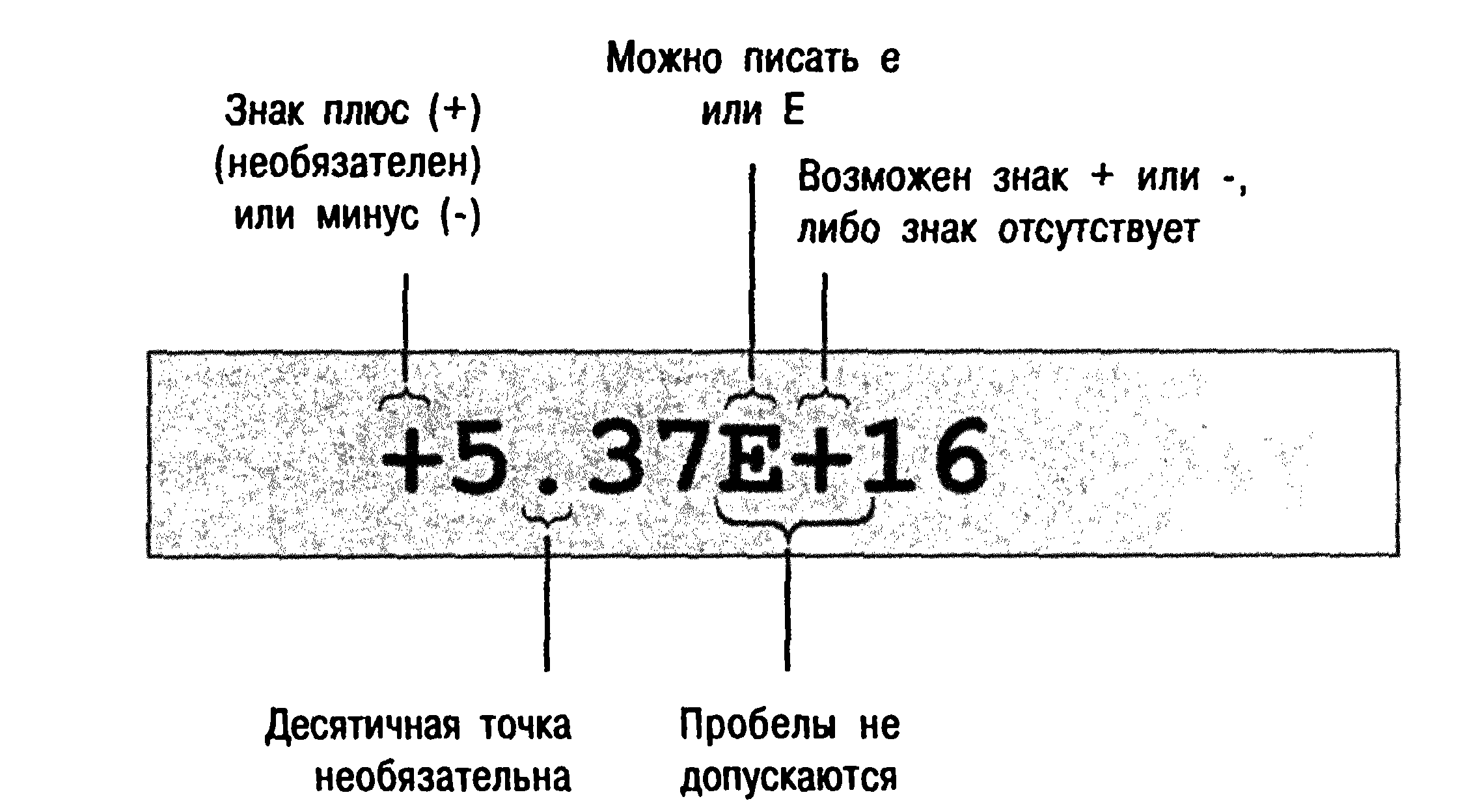
Отрицательная экспонента означает не умножение, а деление на 10 в соответствующей степени. Таким образом, 8.33Е-4 означает 8.33 разделить на 10 в степени 4, или 0.000833. Аналогично масса электрона 9.11е-31 кг означает
0,000000000000000000000000000000911 кг
Существует три типа данных для хранения чисел с плавающей точкой: float, double и long double.
Тип |
Размерность (байт) |
Диапазон |
float |
4 |
от 3.4Е-38 до 3.4Е+38 |
double |
8 |
от 1.7Е-308 до 1.7Е+308 |
long double |
10 |
от 3.4Е-4932 до 3.4Е+4932 |
Какой тип данных используется для хранения в компьютере константы с плавающей точкой? По умолчанию константы с плавающей точкой, например 8.24 и 2.4Е8, будут иметь тип данных double. Если необходимо создать константу типа float, добавьте к ней суффикс f или F. Чтобы тип константы был long double, нужно применить суффикс 1 или L.
l.234f // константа типа float
2.45E20f // константа типа float
2.345324Е28 // константа типа double
2.2L // константа типа long double Венгерская нотация при именовании переменных и констант.
Это соглашение об именовании переменных, констант и прочих идентификаторов в коде программ. Свое название венгерская нотация получила благодаря программисту компании Майкрософт венгерского происхождения Чарльзу Симони, предложившего её ещё во времена разработки первых версий MS-DOS. Эта система стала внутренним стандартом компании Майкрософт.
Суть венгерской нотации заключается в том, что имена идентификаторов предваряются заранее оговорёнными префиксами, состоящими из одного или нескольких символов. При этом ни само наличие префиксов, ни их написание не являются требованием языков программирования, и у каждого программиста (или коллектива программистов) они могут быть в принципе своими.
Пример задания имен для переменных и констант различных типов.
Префикс |
Смысл |
Пример |
s |
striing |
sClientName |
n, i |
int |
nSize, iSize |
l |
long |
lAmount |
b |
bool |
bIsEmpty |
a |
Массив |
aDimensions[10] |
p |
Указатель |
pBox |
lp |
long указатель |
lpBox |
h |
Дескриптор (handle) |
hWindow |
m_ |
Член класса |
m_sAddress |
g_ |
Глобальная переменная |
g_nSpeed |
C |
Класс |
CStrin |
Операции и выражения.
Выражение в языке С++ – это последовательность операндов, операций и символов-разделителей. Операнды – это переменные, константы либо другие выражения. Разделителями в С++ являются символы:
[ ] ( ) { } , ; : * = # ,
каждый из которых выполняет свою функцию. Выражение может состоять из целого ряда операций и определять выполнение целого ряда шагов по преобразованию информации.
По типу выполняемой операции различают арифметические операции, поразрядные логические, присваивания, операции отношения.
Операции и выражения.
Арифметические операции.
В языке C++ имеется пять основных арифметических операций: сложение, вычитание, умножение, деление и деление по модулю. Также существуют две специфические операции, к которым относится операция инкремента и декремента.
В каждой из этих операций используются два числа (называемых операндами) для вычисления результата. Знак операции и два операнда составляют выражение. Рассмотрим, например, следующий оператор:
int wheels = 4 + 2;
Числа 4 и 2 являются операндами, знак "+" является операцией сложения, а запись 4 + 2 представляет собой выражение, значение которого равно б.
Ниже описаны пять основных арифметических операций языка C++:
• Операция сложения +
задает сложение двух операндов. Например, 4 + 20 равно 24.
• Операция вычитания —
задает вычитание второго операнда из первого. Например, 12-3 равно 9.
• Операция умножения *
задает умножение операндов. Например, 28 * 4 равно 112.
• Операция деления /
задает деление первого операнда на второй. Например, 1000 / 5 равно 200. Если оба операнда — целые числа, результатом будет целая часть частного. Например, 17/3 равно 5, дробная часть отбрасывается.
• Операция вычисления остатка от деления %
задает нахождение остатка от деления первого операнда на второй. Например, 19 % 6 равно 1, так как число 19 содержит три раза по 6 с остатком 1. Оба операнда должны быть целочисленными данными. Если один из операндов отрицателен, знак результата зависит от реализации языка.
• Операция инкремента ++
увеличивает значение операнда на 1. Например:
int i;
i=1;
i++;//Здесь переменная i имеет теперь значение 2
• Операция декремента - -
уменьшает значение операнда на 1. Например:
int i;
i=1;
i--;//Здесь переменная i имеет теперь значение 0
Существует две формы записи операций инкремента и декремента. Одна префиксная (когда символ операции предшествует операнду), другая постфиксная (когда символ операции следует за операндом). Такие формы записи сказываются в составных выражениях. Например:
int x,y;
x=42;
y=++x; //Здесь y=43, x=43
Эквивалентно:
x=x+1;
y=x;
Тогда как
int x,y;
x=42;
y=x++; //Здесь y=42, x=43
Эквивалентно:
y=x;
x=x+1;
Операции и выражения.
Операция присваивания.
Язык C++ имеет несколько особенностей выполнения операции присваивания, задаваемого символом операции =. При выполнении операции значение операнда справа от знака равенства записывается в переменную, указанную слева от знака.
В отличие от других языков программирования в С++ допускается запись в одном предложении сразу нескольких операций присваивания. Например:
int a,b,c,d;
a=b=c=d=145;
Другая особенность операции присваивания в языке С++ - наличие так называемой комбинированной операции присваивания:
переменная операция = выражение
Где переменная – это обычная как-то задаваемая переменная.
Операция – это одна из операция, задаваемых знаками: *, / , + , - , % , << , >> , &, ^ , |.
Выражение – любое выражение.
Например:
int a,b;
a=b=0;
a+=12; // a теперь имеет значение 12
b-=(a+4); // b теперь имеет значение -16
Арифметические выражения.
Приоритет операций и ассоциативность
Можно ли в языке C++ выполнять сложные арифметические вычисления? Да, но нужно знать, какие правила языка C++ при этом используются. Например, многие выражения содержат более одной операции. Отсюда возникает вопрос, какая операция должна выполняться первой? Рассмотрим такой оператор:
int i = 3 + 4*5; //35 или 23?
Здесь число "4" является операндом как в операции сложения (+), так и в операции умножения (*). Когда один операнд может участвовать более чем в одной операции, чтобы решить, какая операция должна выполняться первой, в языке C++ применяются правила приоритета операций. Для арифметических операций используется обычная алгебраическая приоритетность, в соответствии с которой умножение, деление и деление по модулю выполняются перед сложением и вычитанием. Таким образом, 3+4*5 означает 3 + (4 * 5), а не (3 + 4) *. 5. Следовательно, ответ будет 23, а не 35.
Порядок выполнения операций можно, разумеется, изменить с помощью круглых скобок. Обратите внимание на то, что операции *, / и % имеют одинаковый приоритет. Аналогично сложение и вычитание обладают одинаковым, но более низким по сравнению с умножением приоритетом.
Однако в некоторых случаях правил приоритетности недостаточно. Рассмотрим следующий оператор:
float j = 120/4*5; // 150 или 6?
Число "4" снова является операндом двух операций. Однако операции /и * имеют одинаковый приоритет, поэтому одного приоритета здесь недостаточно, чтобы определить, что делать в первую очередь: делить 120 на 4 или умножать 4 на 5. А этот порядок имеет значение, так как в первом случае результат равен 150, а во втором — 6. Когда две операции имеют одинаковый приоритет, порядок выполнения операций определяется правилом «слева направо».
Поэтому j=150.0;
Арифметические выражения.
Преобразования типов данных
Разнообразие типов данных в языке C++ дает программисту возможность выбирать вариант, соответствующий конкретной потребности. Однако такое разнообразие, с другой стороны, усложняет задачу компьютера. Например, сложение двух чисел типа short может выполняться с помощью иных машинных команд, чем сложение двух чисел типа long. Когда имеется 11 типов целочисленных данных и три типа данных с плавающей точкой, компьютеру приходится обрабатывать множество различных случаев, особенно если в одной операции смешаны данные различных типов. Чтобы не допустить возможной путаницы, в языке C++ многие преобразования типов данных выполняются автоматически:
Преобразование данных осуществляется, когда данные одного арифметического типа присваиваются переменной другого арифметического типа.
// данные типа int преобразуются в данные // типа float
float tree = 3;
// данные типа float преобразуются
// в данные типа int
int guess = 3.9832;
Результат:
tree = 3.0
guess = 3
Преобразование данных осуществляется, когда в выражении содержатся данные разных типов.
Когда некоторая операция выполняется над данными двух разных типов, то данные меньшего типа преобразуются в данные большего типа. Например:
int i=45;
float f=450.123;
float r=i+f; // результат float
Преобразование данных осуществляется при передаче аргументов в функции.
Если не знать, что происходит при таких автоматических преобразованиях, то результаты выполнения некоторых программ могут оказаться для вас неожиданными.
Приведение типов:
В общем виде:
(имяТипа) значение
// преобразует значение в данные типа имяТипа
имяТипа (значение)
// преобразует значение в данные типа имяТипа
Операции и выражения.
Поразрядные логические операции.
Язык С++ поддерживает следующие поразрядные логические операции.
• Логическое И (AND) &
• Поразрядное логическое сложение по модулю 2 (XOR – исключающее ИЛИ) ^
• Поразрядное логическое ИЛИ (OR) |
• Поразрядная инверсия ~
Каждый бит результата определяется по битам операндов так, как это показано в следующей таблице.
Операнд 1 |
Операнд 2 |
AND |
OR |
XOR |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
1 |
1 |
0 |
0 |
1 |
1 |
1 |
1 |
1 |
1 |
0 |
Инверсия требует единственного операнда справа от знака операции ~. Результат образуется поразрядной инверсией всех битов операнда.
Примеры….
int i=17919, /* i=0100 0101 1111 1111 */
j=255; /* j=0000 0000 1111 1111 */
int r;
r=i^j; /* r=4500 = 0100 0101 0000 0000 */
r=i|j; /* r=17919= 0100 0101 1111 1111 */
r=i&j /* r=255 = 0000 0000 1111 1111 */
r=~j /* r=62280 = 1111 1111 0000 0000 */
Операции и выражения.
Операции сдвига.
Язык С++ включает две операции поразрядного сдвига.
<< - сдвиг влево операнда слева от знака операции на число двоичных разрядов справа от знака операции.
>> - сдвиг вправо операнда слева от знака операции на число двоичных разрядов справа от знака операции.
Выдвигаемые биты теряются, а «вдвигаются» нулевые биты.
Сдвиг операндов влево на 1,2,3 и более разрядов – наиболее быстрый способ умножения на 2, 4, 8 и т.д.. Сдвиг операндов вправо на 1,2,3 и более разрядов – наиболее быстрый способ деления на 2,4,8 и т.д.
Например:
int x,y;
x=12;
y=x>>1; //Деление на 2. Здесь y=6
y=x<<1; //Умножение на 2. Здесь y=24
Операции и выражения.
Логические операции и операции отношения.
Логические операции и операции отношения используются при формировании логических выражений, имеющих только два значения: 1, если логическое выражение ИСТИННО; и 0, если логическое выражение ЛОЖНО. Логические выражения наиболее часто используются вместе с операторами циклов и ветвлений.
С++ поддерживает следующие операции отношения:
> больше
Даёт результат 1, если операнд слева от знака больше операнда справа; в противном случае дает результат 0.
< меньше
Даёт результат 1, если операнд слева меньше операнда справа; в противном случае дает результат 0.
= = равно
Даёт результат 1, если операнд слева от знака равен операнду справа; в противном случае дает результат 0.
>= больше или равно
Даёт результат 1, если операнд слева от знака больше или равен операнду справа; в противном случае дает результат 0.
• <= меньше или равно
Даёт результат 1, если операнд слева меньше или равен операнду справа; в противном случае дает результат 0.
• ! = не равно
Даёт результат 1, если операнд слева от знака не равен операнду справа; в противном случае дает результат 0.
С++ поддерживает следующие логические операции:
&& логическое И
Даёт результат 1 (ИСТИНА), если операнд слева от знака и операнд справа имеют значение 1 (ИСТИНА); в противном случае дает результат 0 (ЛОЖЬ).
| | логическое ИЛИ
Даёт результат 1 (ИСТИНА), если операнд слева от знака или операнд справа имеет значение 1 (ИСТИНА); в противном случае дает результат 0 (ЛОЖЬ).
! логическое НЕ
Даёт результат 1 (ИСТИНА), если операнд справа от знака имеет значение 0 (ЛОЖЬ); в противном случае дает результат 0 (ЛОЖЬ).
В С++ значению ИСТИНА соответствует не только значение 1, но и любое другое ненулевое значение. Поэтому, например:
int i,j;
bool b1,b2;
i=15;
j=0;
b1=!i; // b1 имеет значение 0 (ЛОЖЬ)
b2=!j; // b2 имеет значение 1 (ИСТИНА)
Стандартные библиотечные математические функции.
Программа на языке С++ состоит из одной или нескольких функций. Функция – это логически самостоятельная именованная часть программы, которой могут передаваться параметры и которая может возвращать значение. Тема функций – тема отдельной лекции. Язык С++ в своем составе имеет множество библиотек полезных функций, в том числе библиотеку математических функций, которые незаменимы при разработке программ практически любого назначения. Её содержимого мы и коснемся.
Рассмотрим описания некоторых функций для выполнения элементарных математических операций.
Функция вычисления абсолютного значения аргумента
int abs(int x)
long abs(long x)
Пример:
int a,b;
a=-4;
b=abs(a); // результат b=4
Функция вычисления абсолютного значения аргумента.
float fabs(float x)
double fabs(double x)
long double fabs(long double x)
Пример:
double a,b;
a=-125.25;
b=fabs(a); // результат b=125.25
Функция вычисления значения косинуса угла, заданного в радианах.
float cos(float x)
double cos(double x)
long double cos(long double x)
Пример:
double a,b;
a=3.14;
b=cos(a); // результат b = -1
Функция вычисления значения синуса угла, заданного в радианах.
float sin(float x)
double sin(double x)
long double sin(long double x)
Пример:
double a,b;
a=3.14;
b=sin(a); // результат b = 0
Функция вычисления значения тангенса угла, заданного в радианах.
float tan(float x)
double tan(double x)
long double tan(long double x)
Пример:
double a,b;
a=3.14;
b=tan(a); // результат b = 0
Функция вычисления квадратного корня положительного числа.
float sqrt(float x)
double sqrt(double x)
long double sqrt(long double x)
Пример:
double a,b;
a=144.0;
b=sqrt(a); // результат b = 12.0
Функция вычисления значения <аргумент 1> в степени <аргумент 2>.
float pow(float x, float y)
double pow(double x, double y)
long double pow(long double x, long double y)
double pow(double x, int y)
long double pow(long double x, int y)
Пример:
double a,b,c;
a=2.0;
b=10.0;
c=pow(a,b); // результат c = 1024.0
Функция выделения целой и дробной частей числа типа double.
float modf(float x, float *ipart)
double modf(double x, double *ipart)
long double modf(long double x, long double *ipart)
Дробная часть со знаком числа возвращается функцией, а целая помещается в ячейку памяти, на которую указывает ipart.
Пример:
double a,b,c;
a=41.56789;
b=modf(a,&c); // b = 0.5678924
// c = 41.0
Функция возврата случайного целого числа в диапазоне от 0 до 32767.