

3. Порог
Под порогом подразумевается обычно то число, с которым сравнивается расстояние между объектами (классами) или мера близости объектов для того, чтобы определить, можно ли отнести рассматриваемые два объекта (либо объект и класс, либо два класса) к одному общему классу.
При конструировании классификационной процедуры порог может задаваться и как величина постоянная, не изменяющаяся в течение всей процедуры, и как величина переменная, меняющаяся по определенным правилам при переходе от одного этапа процедуры к другому (см. § 3 настоящей главы).
4. Функционалы качества разбиения на классы. Экстремальная постановка задачи кластер-анализа, связь с теорией статистического оценивания параметров
Естественно попытаться определить сравнительное качество различных способов разбиения заданной совокупности элементов на классы, т. е. определить тот количественный критерий, следуя которому можно было бы предпочесть одно разбиение другому. С этой целью в постановку задачи кластер-анализа часто вводится понятие так называемого функционала качества разбиения Q(S), определенного на множестве всех возможных разбиений. Функционалом он называется потому, что чаще всего разбиение S задается, вообще говоря, набором дискриминантных функций δ1(X), δ2(X), ... . Тогда под наилучшим разбиением S* понимается то разбиение, на котором достигается экстремум выбранного функционала качества. Надо сказать, что выбор того или иного функционала качества, как правило, осуществляется весьма произвольно и опирается скорее на эмпирические и профессионально-интуитивные соображения, чем на какую-либо строгую формализованную систему.
Мы приведем здесь примеры наиболее распространенных функционалов качества разбиения и попытаемся обосновать выбор некоторых из них в рамках одной из моделей статистического оценивания параметров.
Пусть исследователем уже выбрана метрика р в пространстве X и пусть S=(S1, S2, ..., Sk) некоторое фиксированное разбиение наблюдений X1, Х2, ..., Хn на заданное число k классов S1,S2, ..., Sk.
За функционалы качества часто берутся следующие характеристики:
— сумма («взвешенная») внутриклассовых дисперсий
![]() (3.11)
(3.11)
весьма широко используется в задачах кластер-анализа в качестве критерийной оценки разбиения [125],[11],[105],[107],[11],[76] и др.;
сумма попарных внутриклассовых расстояний между элементами
![]()
либо
![]()
в большинстве случаев приводит к тем же наилучшим разбиениям, что и Q1(S) и тоже используется для сравнения кластер-процедур [70],[45],[7].
— обобщенная внутриклассовая дисперсия Q3(S) является, как известно [4, с. 231], одно из характеристик степени рассеивания многомерных наблюдений одного класса (генеральной совокупности) около своего «центра тяжести». Следуя обычным правилам вычисления ковариационной матрицы, - отдельно по наблюдениям, попавшим в какой-то один класс S,
 (3.12)
(3.12)
где под detAпонимается «определитель матрицы А», а элементыwqm(l) выборочной ковариационной матрицыWl классаSlподсчитываются по формуле:
![]() (3.13)
(3.13)
где x(ν)i– ν-ая компонента многомерного
наблюденияXi,
а![]() -среднее
значение ν-й
компоненты,
подсчитанное по наблюдениям l-го
класса.
-среднее
значение ν-й
компоненты,
подсчитанное по наблюдениям l-го
класса.
Встречается и другой вариант использования понятия обобщенной дисперсии как характеристики качества разбиения в котором операция суммирования Wlзаменена операцией умножения:
 .
.
Как видно из формул (3.12 и 3.13), функционал Q3(S) является средней арифметической (по всем классам) характеристикой обобщенной внутриклассовой дисперсии, в то время как функционал Q4(S) пропорционален средней геометрической характеристике тех же величин.
Заметим, что использование функционалов Q3 (S) и Q4 (S) является особенно уместным в ситуациях, при которых исследователь, в первую очередь, задается вопросом: не сосредоточены ли наблюдения, разбитые на классы Sl S2, ..., Sk, в пространстве размерности меньшей, чем p?
Замечание. При вероятностной модификации схем кластер-анализа соответственно видоизменится запись приведенных выше функционалов. Так, например,
![]() ,
,
где
![]()
или
![]() . (3.14)
. (3.14)
а) Общий вид функционала качества разбиения, как функции ряда параметров, характеризующих межклассовую и внутриклассовую структуру наблюдений. Зададимся вопросом: нельзя ли выделить такой достаточно полный набор величин u1(S), u2(S),..., характеризующих как межклассовую, так и внутриклассовую структуру наблюдений при каждом фиксированном разбиении на классы S, чтобы существовала некоторая функция Q(u1,u2,….) от этих величин, которую мы могли бы считать в каком-то смысле универсальной характеристикой качества разбиения. В частности, в качестве таких величин, u1=u1(S),u2=u2(S), ... можно рассмотреть, например, некоторые числовые характеристики: степени близости элементов внутри классов (u1); степени удаленности классов друг от друга (u2); степени «одинаковости» распределения многомерных наблюдений внутри классов (u3); степени равномерности распределения общего числа классифицируемых наблюдений п по классам (u4).
Что касается установления
общего вида функции Q(u1,u2,u3,u4),
то
без введения дополнительной априорной
информации о наблюдениях
Xi
(характере и общем виде их закона
распределения внутри классов
и т. п.) единственным возможным подходом
в решении задачи,
как нам представляется, является
экспериментальное
исследование. Именно с этих позиций в
[12] сделана попытка определения
общего вида функции Q.
Чтобы
определить рассмотренные в
этой работе величины u1
u2,
u3
и u4,
введем
понятие кратчайшего незамкнутого
пути (КНП), соединяющего все n
точек исходной
совокупности
в связный неориентированный граф с
минимальной суммарной длиной
ребер. Под длиной ребра понимается
расстояние между соответствующими
точками совокупности в смысле выбранной
метрики. Построение
такого графа можно начать с пары наиболее
близких точек. Если таких пар несколько,
то выбирается любая из этих пар, Пусть
это будут наблюдения с номерами i0
и j0.
Затем с помощью сравнения
расстояний ρ(Xio,Xj)(j=l,2,...,n,
j≠i0,
j≠j0)
и ρ(Xi0,Xq),
где
q=l,2,...,n,q≠i0,
q≠i0
определяются
точки![]() и
и![]() —
наименее удаленные соответственно от
точек
—
наименее удаленные соответственно от
точек
![]() и
и![]() —
выбирается
ближайшая из них
—
выбирается
ближайшая из них
![]() ,
т.е.
,
т.е.
![]() =
=![]() ,
если
,
если
![]() и
и
![]() =
=![]() ,
если
,
если
![]() 1.
Затем точка
1.
Затем точка
![]() „пристраивается"
к той из точек
„пристраивается"
к той из точек
![]() и
и![]() ,
к которой она ближе. Далее сравниваются
расстояния
,
к которой она ближе. Далее сравниваются
расстояния ![]()
![]() и т. д. Очевидно, «разрубая»
s
ребер такого графа, мы будем делить
совокупность
на s+1
классов.
и т. д. Очевидно, «разрубая»
s
ребер такого графа, мы будем делить
совокупность
на s+1
классов.
Пусть ρi(l)
— i-ое
ребро части графа, отнесенной к l-му
классу. Всего
таких ребер, как легко видеть, будет пl
—
1. И пусть ![]() —
минимальное из
ребер, непосредственно примыкающих к
ребру ρ
и
относящихся к l-му
классу, если таковое имеется. Занумеруем
в определенном
порядке граничные, разрубленные ребра
λ1,
λ2,…..
λk-1
таким
образом, чтобы имелось взаимно однозначное
соответствие между
номерами граничных ребер и номерами
примыкающих к ним классов,
за исключением одного, геометрически
представленного одним
из «хвостов» графа. На рис. 3.2 представлено
изображение кратчайшего незамкнутого
пути. Выбрасывая ребра I,
II,
III,
получаем
четыре связных графа, что соответствует
разбиению совокупности на
четыре группы. Обозначим с помощью λl,
одно из таких ребер l-го
класса.
—
минимальное из
ребер, непосредственно примыкающих к
ребру ρ
и
относящихся к l-му
классу, если таковое имеется. Занумеруем
в определенном
порядке граничные, разрубленные ребра
λ1,
λ2,…..
λk-1
таким
образом, чтобы имелось взаимно однозначное
соответствие между
номерами граничных ребер и номерами
примыкающих к ним классов,
за исключением одного, геометрически
представленного одним
из «хвостов» графа. На рис. 3.2 представлено
изображение кратчайшего незамкнутого
пути. Выбрасывая ребра I,
II,
III,
получаем
четыре связных графа, что соответствует
разбиению совокупности на
четыре группы. Обозначим с помощью λl,
одно из таких ребер l-го
класса.
Р ис.3.2.
ис.3.2.
Графическое изображение кратчайшего незамкнутого пути.
Теперь, следуя [12], определим величины uiследующим образом:
![]() ,
где
,
где - средняя длина реберl-го
класса.
- средняя длина реберl-го
класса.
![]() ,
,
![]() ,
,
![]() .
.
Эмпирический перебор различных вариантов общего вида функции Q в сочетании с анализом результатов экспертных оценок качества всевозможных разбиений привели авторов [12] к следующей формуле:
 (3.15)
(3.15)
тде а, Ь, с и d — некоторые неотрицательные параметры, оставляющие исследователю определенную свободу выбора в каждом конкретном случае. Авторы [12] отмечали хорошее согласие своих экспериментов с экспертными оценками при a = b = c = d-= 1.
Из смысла величины ui (i = 1, 2, 3, 4) следует, что лучшим разбиениям соответствуют большие численные значения функционала Q, так что в данном случае требуется найти такое разбиение S*, при котором Q (S*) = maxS Q(S).
Конечно, данный выбор количественного и качественного состава величин ui и, в еще большей степени, их точное определение являются чисто эвристическими и подчас просто спорными. Это относится, в первую очередь, к величине u3. Поэтому читатель должен принимать описанную здесь схему не как рекомендацию к универсальному использованию функционалов типа (3.15) в задачах кластер-анализа, но лишь как описание конкретного примера одного из возможных подходов при выборе функционалов качества разбиения.
б) Функционалы качества разбиения при неизвестном числе классов. В ситуациях, когда исследователю заранее не известно, на какое Число классов подразделяются исходные многомерные наблюдения Х1, Х2, ..., Хп, функционалы качества разбиения Q(S) выбирают чаще всего в виде простой алгебраической комбинации (суммы, разности, произведения, отношения) двух функционалов I1(S) и I2(S), один из которых I1 является убывающей (не возрастающей) функцией числа классов k и характеризует, как правило, внутриклассовый разброс наблюдений, а второй I2 является возрастающей (неубывающей) функцией числа классов k. При этом интерпретация функционала I2 может быть различной. Под I2 понимается иногда и некоторая мера взаимной удаленности (близости) классов, и мера тех потерь, которые приходится нести исследователю при излишней детализации рассматриваемого массива исходных наблюдений, и величина, обратная так называемой «мере концентрации» всей структуры точек, полученной при разбиении исследуемого множества наблюдений на k классов. В [41], например, предлагается брать
![]() ,
,
![]()
где k(S)- число классов, получающихся при разбиенииS, а с – некоторая положительная постоянная, характеризующая потери исследователя числа классов на единицу. Другой вариант функционалов качества такого типа можно найти, например, в [10], где полагают
 ,
,
![]() .
.
Здесь К (X, Y) — упомянутая выше потенциальная функция, а r(Si, Sj) — мера близости i-го и j-го классов, основанная на потенциальной функции (3.6).
Очевидно, в первом случае мы будем искать разбиение S*, минимизирующее значение функционала
Q(S)=I1(S)+I2(S)
в то время как во втором случае требуется найти разбиение S°, которое максимизировало бы значение функционала
Q’(S)=I1’(S)+I2’(S)
Весьма
гибкой и достаточно общей схемой,
реализующей идею одновременного
учета двух функционалов, нам представляется
схема, предложенная
А. Н. Колмогоровым (см. сноску к стр. 83).
Эта схема опирается
на понятия меры концентрации Zr(S)
точек,
соответствующей
разбиению S, и средней меры внутриклассового
рассеяния
![]() ,характеризующей
то же разбиение S.
,характеризующей
то же разбиение S.
Под мерой концентрации Zr (S) предлагается принимать величину

где ν(Xi) — число элементов в кластере, содержащем точку Хi, а выбор - числового параметра r находится в распоряжении исследователя и за висят от конкретных целей разбиения. При выборе r полезно иметь в виду следующие частные случаи Zr (S):
Z-1(S)=1/k.
где k — число различных кластеров в разбиении S;
![]() — естественная
информационная мера концентрации;
— естественная
информационная мера концентрации;
![]() ,
,
![]() ,
,
![]() .
.
Заметим, что при любом r
предложенная мера
концентрации имеет минимальное
значение, равное
![]() ,
при разбиении исследуемого множества
на п
одноточечных
кластеров и максимальное значение,
равное 1, при
объединении всех исходных наблюдений
в один общий кластер. При
конструировании и сравнении различных
кластер-процедур полезно иметь в виду,
что объединение двух кластеров Sl
и Sm
в один дает
прирост меры концентрации Z1
(S),
равный
,
при разбиении исследуемого множества
на п
одноточечных
кластеров и максимальное значение,
равное 1, при
объединении всех исходных наблюдений
в один общий кластер. При
конструировании и сравнении различных
кластер-процедур полезно иметь в виду,
что объединение двух кластеров Sl
и Sm
в один дает
прирост меры концентрации Z1
(S),
равный
![]()
Определение средней меры внутриклассового рассеяния Ir(К)(S) также опирается на понятие степенного среднего. В частности, полагают
 , (3.19)
, (3.19)
где под

понимается обобщенная средняя мера рассеяния, характеризующая класс Si. Числовой параметр r здесь, как и прежде, выбирается по усмотрению исследователя. Полагая

где, как и прежде, S(X) — кластер, в который входит наблюдение X, a ν(X)—число элементов в кластере S(X), формулу (3.19) можно переписать в виде
 . (3.20)
. (3.20)
При
конструировании и сравнении различных
кластер-процедур полезно
иметь в виду, что объединение двух
кластеров Sl,
и Sm
в
один дает прирост величины
![]() ,
непосредственно
характеризующей
среднюю меру внутриклассового рассеяния,
равный
,
непосредственно
характеризующей
среднюю меру внутриклассового рассеяния,
равный
![]() .
.
Очевидно, если ориентироваться
на сокращение числа кластеров при
наименьших потерях в отношении
внутриклассового рассеивания,
не обращая внимания на меру концентрации,
то естественно объединять
два кластера, для которых минимальна
величина ![]() .
Если же одновременно ориентироваться
и на рост взвешенной
концентрации Z1(S),
то объединение кластеров естественно
подчинить
требованию минимизации величины
.
Если же одновременно ориентироваться
и на рост взвешенной
концентрации Z1(S),
то объединение кластеров естественно
подчинить
требованию минимизации величины
 .
.
в) Формулировка экстремальных задач разбиения исходного множества на классы.
Вариант 1: комбинирование функционалов качества. Требуется найти такое разбиение S*, для которого некоторая алгебраическая комбинация функционала, характеризующего среднее внутриклассовое рассеяние (3.20), и функционала, характеризующего меру концентрации полученной структуры (3.18), достигала бы своего экстремума. В качестве примеров можно привести комбинации Q(S) и Q'(S), задаваемые формулами (3.16) и (3.17), выражения вида
![]() (3.21)
(3.21)
где
![]() ,
,
а α и β — некоторые положительные константы, например, α=β=1.
Вариант
2:
двойственная формулировка. Требуется
найти разбиение
S*,
которое, обладая концентрацией Zr(S*),
не меньшей
заданного
порогового значения Z0,
давало бы наименьшее внутриклассовое
рассеяние
![]() или в двойственной подстановке: при
заданном пороговом
значении I0
найти разбиение S*
с внутриклассовым,
рассеянием
или в двойственной подстановке: при
заданном пороговом
значении I0
найти разбиение S*
с внутриклассовым,
рассеянием
![]() наибольшей концентрацией Zr
(S*).
наибольшей концентрацией Zr
(S*).
г) Функционалы качества и необходимые условия оптимальности-разбиения. Естественно попытаться проследить, в какой мере выбор того или иного вида функционала качества определяет класс разбиений, в котором следует искать оптимальное. Приведем здесь некоторые результаты, устанавливающие такого рода соответствие.
Утверждение 1: для функционалов типа Q1 (3.11). Будем, предполагать используемую метрику евклидовой. Обозначим через Е = (El ..., Ek) группу из k p-мерных векторов Еj (j = 1, 2.... k), а через S(E)= (S1(E),…Sk(E)) – так называемое минимальное дистанционное разбиение, порождаемое точками Е = (El ..., Ek). А именно,
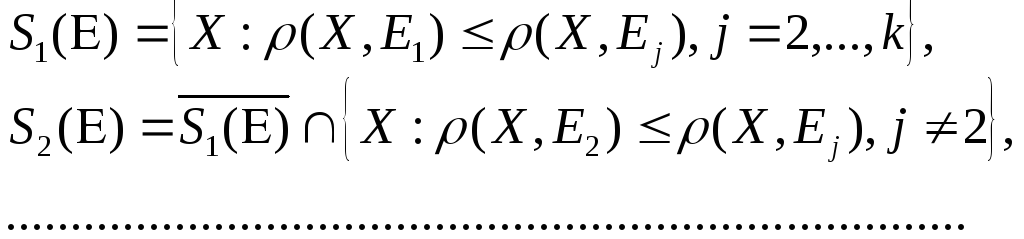
![]() 1
1
Таким образом, класс Sj(Е) состоит из тех точек пространства X, которые ближе Еj, чем ко всем остальным Еi (i<>j). Если для некоторых точек из X самыми близкими являются сразу несколько векторов Ej(j=1,…,k), то мы относим эти точки к классу с минимальным индексом.
Разбиение S=(S1,...,Sk) называется несмещенным разбиением, если это разбиение с точностью до множеств меры нуль совпадает с минимальным дистанционным разбиением, порождаемым векторами средних
![]() .
.
В работе [33] показано, что минимальное значение функционала достигается только на несмещенных разбиениях. Это означает, что оптимальное разбиение обязательно должно быть несмещенным.
Утверждение 2: для функционалов от разбиений на два класса. Следующее утверждение относится к довольно широкому классу функционалов качества разбиения совокупности на два класса. Разбиение на два класса может быть задано с помощью так называемой разделяющей функции. А именно, точки пространства X, на которых разделяющая функция принимает неотрицательное значение, относятся к одному классу, а остальные — к другому. Поэтому поиск класса оптимальных разбиений в этом случае эквивалентен поиску класса оптимальных разделяющих функций.
Для иллюстрации дальнейшего изложения будем рассматривать вероятностную модификацию функционала Q2’ (3.14).
Пусть расстояние ρ(X,Y) задается с помощью соотношения (3.3) потенциальной функцией вида
![]() ,
,
где φi(X) (i = 1, ..., N) — некоторая система функции на X.
Функционал Q2’ через потенциальную функцию К(X,Y) выражается следующим образом:
![]() .
.
Поскольку в правой части этого равенства первый интеграл не зависит от разбиения, то минимум функционала Q2’(S) достигается на тех разбиениях, на которых функционал
![]()
достигает максимума.
Введем в рассмотрение спрямляющее пространство Z, координаты z(i) векторов Z є Z которого определяются соотношениями
z(i)=λiφi(X) (i=1,….,N).
В спрямляющем пространстве Z вероятностной мерой Р, заданной в исходном пространстве X, индуцируется своя вероятностная мера P(Z). Однако в целях упрощения обозначений мы будем опускать ''верхний индекс Z у этой новой меры. Что касается функционала Q2 (S), то в спрямляющем пространстве он примет вид
![]() .
.
Пусть
![]()
Здесь Z2j=[(Z,Z)]j— числа, Z2j+1 =[(Z, Z)]jZ — векторы.
В работе
[7] формулируется утверждение,
устанавливающее класс функций в
спрямляющем пространстве Z,
среди которых следует искать
разделяющую функцию, доставляющую
экстремум функционалу качества
разбиения. А именно, показано, что если
функционал качества
Ф является дифференцируемой функцией
от ![]() ,
а вероятностное
распределение Р(Z)
сосредоточено на ограниченном множестве
Z
и обладает непрерывной плотностью, то
если экстремум функционала Ф
достигается на некоторой разделяющей
функции, то этот же
экстремум достигается на разделяющей
функции, являющейся
полиномом r-й
степени вида:
,
а вероятностное
распределение Р(Z)
сосредоточено на ограниченном множестве
Z
и обладает непрерывной плотностью, то
если экстремум функционала Ф
достигается на некоторой разделяющей
функции, то этот же
экстремум достигается на разделяющей
функции, являющейся
полиномом r-й
степени вида:
![]() ,
,
где
![]()
a
![]() ,
означает при четном ν произведение
чисел cν
и Zν,
а при нечетном
ν — скалярное произведение векторов
cν
и Zν.
,
означает при четном ν произведение
чисел cν
и Zν,
а при нечетном
ν — скалярное произведение векторов
cν
и Zν.
Для функционала Q2’ сформулированное означает, что класс разделяющих функций, среди которых надо искать наилучшее в спрямляющем пространстве разбиение, имеет вид
![]() ,
,
где
 (3.22)
(3.22)
и
 ,
,
![]()
Класс разделяющих функций в спрямляющем пространстве очевидным образом определяет класс разделяющих функций в исходном пространстве X.
Если К (X,Y) = (X,Y) является скалярным произведением векторов X и Y, то спрямляющее пространство Z совпадает с исходным пространством X, а метрика, задаваемая потенциальной функцией К (X, Y), совпадает с обычной евклидовой метрикой. Функционалы Q2 и Q'2, рассматриваемые относительно этой метрики, совпадают с точностью до константы.
В этом случае, как нетрудно видеть, разбиение, задаваемое разделяющей функцией f (Z), является несмещенным разбиением.
д) Функционалы качества разбиения как результат применения метода максимального правдоподобия, к задаче статистического оценивания неизвестных параметров. Приведем здесь пример, иллюстрирующий возможность обоснования выбора общего вида функционала качества разбиения на классы в ситуациях, в которых исследователю удастся «втиснуть» свою задачу в рамки одной из классических моделей.
Пусть априорные сведения позволяют определить i-й однородный класс (кластер) как нормальную генеральную совокупность наблюдений с вектором средних ai ковариационной матрицей Σi. При этом ai и Σi вообще говоря, неизвестны. Нам известно лишь, что каждое из наблюдений Х1, Х2, ..., Хn извлекается из одной из k нормальных генеральных совокупностей N (ai,Σi), i= 1, 2, ..., k. Задача исследователя — определить, какие из ni исходных наблюдений извлечены из класса N (a1,Σ1), какие n2 наблюдений извлечены из класса N (a1,Σ1), и т. д. Очевидно, числа n1,n2, ..., nk, вообще говоря, также неизвестны.
Если ввести в рассмотрение вспомогательный векторный параметр γ=(γ1,γ2,….,γn), в котором компонента γi определяет помер класса, к которому относится наблюдение Хi, т. е. γi=l, если Xi є N(al,Σl), i = 1, 2, ..., п, то задачу разбиения на классы можно формулировать как задачу оценивания неизвестных параметров γ1,γ2,….,γn при «мешающих» неизвестных параметрах ai и Σi , i = 1,2, ..., k. Обозначив весь набор неизвестных параметров с помощью θ, т. е. θ = (γ,a1,…,ak,Σ1,….,Σk) и пользуясь известной [4] техникой, получаем логарифмическую функцию правдоподобия для наших наблюдений Х1, Х2, ..., Хn.
![]() . (3.23)
. (3.23)
Как
известно, оценка
![]() параметра
параметра![]() и по методу максимальногоправдоподобия
находится из условия
и по методу максимальногоправдоподобия
находится из условия
![]() .
.
Поэтому
естественно было бы попытаться найти
такое разбиение
![]() на классы S1,S2,
..., Sk,
а также такие вектора средних ai
и ковариационные
матрицы
на классы S1,S2,
..., Sk,
а также такие вектора средних ai
и ковариационные
матрицы
![]() ,
при которых величина —2l(θ)
достигала бы своего
абсолютного минимума1.
,
при которых величина —2l(θ)
достигала бы своего
абсолютного минимума1.
При известном разбиении γ оценками максимального правдоподобия для al будут «центры тяжести» классов
![]()
Подставляя их в (3.23) вместо al и воспользовавшись очевидными тождественными преобразованиями, приходим к эквивалентности задачи поиска минимума функции — 2l(θ), определенной соотношением (3.23), и задачи поиска минимума выражения
 (3.24)
(3.24)
или, что то же, выражения
![]() (3.25)
(3.25)
В последнем выражении Wl выборочная ковариационная матрица, вычисленная по наблюдениям, входящим в состав l-го класса (3.13).
Анализ выражений (3.24) и (3.25) в некоторых частных случаях немедленно приводит к следующим интересным выводам:
— если ковариационные матрицы исследуемых генеральных совокупностей равны между собой и известны, то задача оценивания неизвестного параметра θ по методу максимального правдоподобия равносильна задаче разбиения наблюдений Xi на классы, подчиненной функционалу качества разбиения вида Q1(S), в котором под расстоянием ρ подразумевается расстояние Махаланобиса;
—- если ковариационные матрицы исследуемых генеральных совокупностей равны между собой, но не известны, то, подставляя в (3.25) вместо Σl = Σ ее оценку максимального правдоподобия
![]()
убеждаемся в эквивалентности задачи оценивания (по методу максимального правдоподобия) параметра θ и задачи поиска разбиения наблюдений Xi на классы, наилучшего в смысле функционала качества Q3(S);
— если ковариационные матрицы исследуемых генеральных совокупностей не равны между собой и не известны, то, подставляя в (3.25) вместо Σl их оценки максимального правдоподобия Wl убеждаемся в эквивалентности задачи оценивания по методу максимального правдоподобия параметра θ и задачи поиска разбиения наблюдений Xi на классы, наилучшего в смысле функционала качества Q4 (S).
В [68] авторы пытаются конструировать алгоритмы, реализующие идею получения оценок максимального правдоподобия для параметра θ. Однако нам представляется главная ценность подобного подхода лишь в его методологической, качественной стороне, в том, что он позволяет строго осмыслить и формализовать некоторые функционалы качества разбиения, введенные ранее чисто эвристически. Конструктивная же сторона подобного подхода упирается в трудно преодолимые препятствия вычислительного плана, связанные с колоссальным количеством переборов вариантов уже при сравнительно небольших размерностях р и объемах выборки.