

Разные полезные материалы / GEC_ALG
.DOCПостроение сложных решающих правил на основе алгоритма “Геконал”
В данном разделе рассматривается подход к построению решающих правил на основе использования алгоритма обучения “Геконал”, позволяющего реализовать правила классификации в виде дерева решений. В процессе обучения формируются описания классов в виде так называемых миноров-эталонов, фактически являющихся продукционными правилами с соответствующими факторами уверенности полученных правил. Полученные решающие правила могут быть реализованы в виде продукционных правил в соответствующей системе логического вывода.
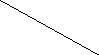
В основе использования алгоритма “Геконал” лежит концепция построения многоуровневой схемы принятия решения, обеспечивающая возможность использования разнородных групп признаков [9,13]. Общая структура такой модели классфикатора представлена на рис. 3.4.
 x11
x11


 x12
x12
 .
ЧК1
.
ЧК1
.
 x1k1
x1k1

 x21
x21
 решение
решение

 x22
БПОР
x22
БПОР
 .
ЧК2
.
ЧК2
 .
.
 x2k2
x2k2
.
.
.
.
.
.
.

 xr1
xr1
 xr2
xr2
.
.
 xrkr
xrkr
Рис 3.4. Блок принятия общего решения
Основными элементами системы являются
частные классификаторы ЧКi,
которые представляют собой самостоятельные
системы принятия решений, выполняемых
по группе признаков
![]() .
Выходом ЧКi является номер
класса или соответствующий символ, его
описывающий. Частные решения от всех
ЧКi поступают на блок принятия
общего решения (БПОР). Далее рассмотрим
теоретические основы построения такой
многоуровневой системы классификации
на основе описания алгоритма “Геконал”.
.
Выходом ЧКi является номер
класса или соответствующий символ, его
описывающий. Частные решения от всех
ЧКi поступают на блок принятия
общего решения (БПОР). Далее рассмотрим
теоретические основы построения такой
многоуровневой системы классификации
на основе описания алгоритма “Геконал”.
3.3.4.1. Алгоритмы обучения и принятия решения
Будем предполагать, что в описание объекта классификации могут включаться количественные, качественные, бинарные и именованные признаки. Таким образом, объект может быть описан вектором признаков:
![]() ,
,
состоящим из
![]() -однородных
групп длиной
-однородных
групп длиной
![]() каждая
каждая
![]() .
.
Предполагается, что для набора рассматриваемых признаков имеется обучающая выборка по каждому классу объектов, отражающая основные режимы функционирования объектов классификации.
Процесс обучения заключается в последовательном выполнении 3-х основных этапов:
- номинализация входных данных;
- получение решающих правил эталонного типа;
- оценка статистических параметров полученных эталонов.
Номинализация обеспечивает единое
представление разнородных данных на
входе классификатора. Номинализация
осуществляется путем отображения
значений соответствующих координат
(или групп координат) вектора
![]() в значения символьных переменных. В
качестве таких переменных в дальнейшем
будем использовать целые числа 0,1,... и
знак "-", соответствующий отсутствию
значений данной переменной. Номинализация
данных, представленных в качественных
и именованных шкалах, осуществляется
присвоением соответствующих целочисленных
значений (без введения упорядоченности).
При использовании в качестве координат
вектора
в значения символьных переменных. В
качестве таких переменных в дальнейшем
будем использовать целые числа 0,1,... и
знак "-", соответствующий отсутствию
значений данной переменной. Номинализация
данных, представленных в качественных
и именованных шкалах, осуществляется
присвоением соответствующих целочисленных
значений (без введения упорядоченности).
При использовании в качестве координат
вектора
![]() значений ответов частного классификатора
ЧКi результатом номинализации
будет являться номер подкласса из
внутреннего алфавита данного ЧКi,
к которому был отнесен наблюдаемый
объект в
значений ответов частного классификатора
ЧКi результатом номинализации
будет являться номер подкласса из
внутреннего алфавита данного ЧКi,
к которому был отнесен наблюдаемый
объект в
результате работы соответствующего ЧКi. При этом номинализация либо вообще не производится (если ответ выдается непосредственно в виде номера подкласса), либо заключается в замене соответствующего именованного значения подкласса на целочисленное по заданной таблице соответствий. Бинарные признаки представляются в естественной форме 0,1. Номинализация данных, представленных в числовой шкале, осуществляется с использованием алгоритмов кластеризации. При кластеризации возможны два основных подхода, выбор которых зависит от характеристик реальной задачи и свойств имеющихся в распоряжении обучающих выборок:
1. Разбиение всей выборки (без использования
информации о классе) на объективные
подклассы, после чего вся обучающая
выборка классифицируется на полученные
подклассы. При этом соответствующее
значение группы координат
![]() вектора
вектора
![]() заменяется номером соответствующего
подкласса.
заменяется номером соответствующего
подкласса.
2. Проведение кластеризации по выборкам каждого класса в отдельности с присвоением соответствующим подклассам сквозной нумерации по всем классам.
При номинализации одномерных числовых
данных
![]() кроме автоматической кластеризации
возможно использование интерактивного
режима номинализации на основе гистограмм
значений отдельных признаков, сводящегося
к интервальному кодированию с задаваемыми
в процессе диалога границами интервалов.
кроме автоматической кластеризации
возможно использование интерактивного
режима номинализации на основе гистограмм
значений отдельных признаков, сводящегося
к интервальному кодированию с задаваемыми
в процессе диалога границами интервалов.
Результатом процесса номинализации
является набор обучающих выборок
![]() для каждого класса основной классификации
(
для каждого класса основной классификации
(![]() ,
где
,
где
![]() - количество классов), каждый вектор
которых
- количество классов), каждый вектор
которых
![]() представляет собой набор целочисленных
ответов отдельных частных классификаторов,
а также (при необходимости) номинализованную
дополнительную информацию.
представляет собой набор целочисленных
ответов отдельных частных классификаторов,
а также (при необходимости) номинализованную
дополнительную информацию.
Следует заметить, что описанный выше метод номинализации числовых данных путем кластеризации может быть рекомендован как один из возможных путей решения задачи построения ЧК.
На этапе получения решающих правил эталонного типа решается задача получения логических решающих правил, основанная на построении наборов миноров-эталонов для каждого класса. Рассмотрим сущность предлагаемого алгоритма.
Минором какого-либо вектора будем
называть вектор, полученный из данного
вектора путем замены символом "-"
(неопределено) одной или более компонент.
Количество значащих компонент минора
определяет его позиционность
![]() .
.
Определяются следующие базовые понятия для векторов
![]()
равенство ![]() ,
если
,
если
![]() ,
,
![]() ;
;
ортогональность ![]() ,
если
,
если
![]() ,
,
![]()
поглощение ![]()
![]() поглощает
поглощает
![]() ,
если все компоненты
,
если все компоненты
![]() ,
не равные -, равны соответствующим
компоненентам
,
не равные -, равны соответствующим
компоненентам
![]() ;
;
коллинеарность ![]() ,
если имеются хотя бы две пары одноименных
компонент с индексами
,
если имеются хотя бы две пары одноименных
компонент с индексами
![]() ,
,
![]() ,
таких, что
,
таких, что
![]() .
.
Задача обучения состоит в нахождении
![]() групп (
групп (![]() - число классов) миноров, называемых
минорами-эталонами (м-э). Каждая группа
миноров-эталонов
- число классов) миноров, называемых
минорами-эталонами (м-э). Каждая группа
миноров-эталонов
![]() ,
,
![]() поглощает соответствующую выборку
поглощает соответствующую выборку
![]() и не поглощает векторов альтернативных
выборок
и не поглощает векторов альтернативных
выборок
![]() ,
,
![]() .
Набор м-э будет минимальным, если все
входящие в него м-э будут попарно
ортогональны или коллинеарны. Предлагаемый
алгоритм обучения основан на использовании
восходящего процесса построения наборов
м-э, начиная с м-э, имеющих одну значащую
компоненту, и в дальнейшем наращивании
количества значащих компонент (так
называемый показатель позиционности
м-э). Поэтому этот алгоритм называется
восходящим алгоритмом обучения.
.
Набор м-э будет минимальным, если все
входящие в него м-э будут попарно
ортогональны или коллинеарны. Предлагаемый
алгоритм обучения основан на использовании
восходящего процесса построения наборов
м-э, начиная с м-э, имеющих одну значащую
компоненту, и в дальнейшем наращивании
количества значащих компонент (так
называемый показатель позиционности
м-э). Поэтому этот алгоритм называется
восходящим алгоритмом обучения.
С целью минимизации процесса перебора
из выборок
![]()
![]() формируются новые выборки
формируются новые выборки
![]() ,
получаемые заменой одинаковых векторов,
входящих в
,
получаемые заменой одинаковых векторов,
входящих в
![]() ,
на их единичного представителя. В
практических задачах длина
,
на их единичного представителя. В
практических задачах длина
![]() оказывается существенно меньше длины
исходной выборки
оказывается существенно меньше длины
исходной выборки
![]() .
Выборки
.
Выборки
![]() непосредственно используются в ходе
построения м-э, а также при дальнейшей
минимизации их количества.
непосредственно используются в ходе
построения м-э, а также при дальнейшей
минимизации их количества.
Процесс порождения м-э осуществляется
путем поочередного анализа минора
каждого вектора
![]() ,
,
![]() , где
, где
![]() - длина обучающей выборки класса
- длина обучающей выборки класса
![]() .
.
При этом осуществляется следующая последовательность действий.
1. Проверка, не входит ли анализируемый
минор
![]() в набор пересечений П.
в набор пересечений П.
2. Не поглощается ли
![]() уже сформированным набором м-э данного
класса позиционности М.
уже сформированным набором м-э данного
класса позиционности М.
Если ответ на 1 и 2 утвердительный (не входит, не поглощается), то происходит переход к пункту 3, иначе данный минор далее не рассматривается.
3. Производится проверка
![]() на ортогональность всех векторов
альтернативных классов
на ортогональность всех векторов
альтернативных классов
![]()
![]() .
Если результат проверки положителен,
то
.
Если результат проверки положителен,
то
![]() включается в набор м-э
включается в набор м-э
![]() ,
иначе он включается в набор пересечений
П.
,
иначе он включается в набор пересечений
П.
Указанный в процессе перебор повторяется с наращиванием позиционности на 1 в каждом цикле.
Остановка процесса производится на основании критерия, сформулированного в теореме о достижении непродуктивной фазы восходящего алгоритма обучения.
"Для восходящего алгоритма построения
набора м-э процесс обучения при любом
значении позиционности
![]() является непродуктивным, если подмножество
является непродуктивным, если подмножество
![]() позиционных миноров-пересечений пусто".
позиционных миноров-пересечений пусто".
Под непродуктивной фазой понимается
этап обучения, при котором не появляются
новые м-э с ростом позиционности
![]() .
.
Применение сформулированной теоремы на практике приводит к существенному ограничению процесса перебора в процессе обучения.
В случае, если обучающие выборки классов не пересекаются, то процесс прекращается на соответствующем шаге при выполнении условия вышеприведенной теоремы. При этом гарантируется, что полученное множество м-э позволяет правильно классифицировать вектора обучающей выборки.
В случае пересекающихся обучающих
выборок, даже после построения м-э
позиционности
![]() (
(![]() - размерность признакового пространства
выборок
- размерность признакового пространства
выборок
![]() ),
набор пересечений П остается не пустым.
В этом случае пересекающиеся вектора,
вошедшие в набор П, помещаются в качестве
м-э позиционности для соответствующих
классов.
),
набор пересечений П остается не пустым.
В этом случае пересекающиеся вектора,
вошедшие в набор П, помещаются в качестве
м-э позиционности для соответствующих
классов.
В процессе классификации производится проверка распознавания вектора на поглощение минорами-эталонами соответствующих классов и производится принятие решения о классе. При этом возможно возникновение следующих критических ситуаций:
- отсутствие м-э какого-либо класса, поглотивших данный вектор;
-нахождение нескольких м-э, относящихся к разным классам, поглотившим данный вектор.
Первая ситуация связана, как правило, с недостаточной информативностью обучающей выборки и ее возникновение однозначно приводит к отказу в принятии решения.
Вторая ситуация может возникать вследствие анализа вектора, соответствующего м-э, вошедшему в массив пересечений, либо с возникновением ситуации, предусмотренной исходной обучающей выборкой и связанной с отклонениями в работе одного, либо нескольких ЧК. В этих случаях выработка окончательного ответа возможна с учетом оценки статистических параметров выборок.
Учет вероятностных характеристик при принятии решений
После построения миноров-эталонов
каждого класса
![]() производится оценка каждого м-э с
использованием соответствующей выборки
класса
производится оценка каждого м-э с
использованием соответствующей выборки
класса
![]() .
Для оценки веса м-э
.
Для оценки веса м-э
![]() используется соотношение
используется соотношение
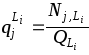 ,
,
где
![]() - количество векторов выборки
- количество векторов выборки
![]() ,
поглощаемых
,
поглощаемых
![]() -ым
м-э класса
-ым
м-э класса
![]() ;
;
![]() - общее количество векторов в выборке
- общее количество векторов в выборке
![]() .
.
Следует заметить, что для м-э, сформированных
на основании векторов пересечений,
значение
![]() равно оценке соответствующей апостериорной
вероятности
равно оценке соответствующей апостериорной
вероятности
![]() .
.
Принятие решения реализуется по следующей схеме.
1. Если классифицируемый вектор
![]() поглощается м-э нескольких классов, то
для каждого класса вычисляется вес
поглощается м-э нескольких классов, то
для каждого класса вычисляется вес
![]() по одному из соотношений:
по одному из соотношений:
а) 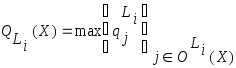 ,
,
где
![]() - множество м-э класса
- множество м-э класса
![]() ,
поглотивших вектор
,
поглотивших вектор
![]() ;
;
б) либо рекуррентно
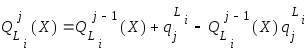 , для
, для
![]() .
.
Выбор соответствующей формулы в общем виде зависит от коррелированности ответов соответствующих м-э и на практике может быть сделан в ходе экспериментальных исследований.
2. После вычисления весов определяются вероятности каждого класса
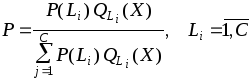
и принимается решение о классе с большей вероятностью.
3. При невыполнении условий 1 и 2, то есть в случае отсутствия м-э какого-либо класса, поглотившего данный вектор, выдается отказ.
Минимизация количества миноров-эталонов и формирование факторов уверенности
Порождаемое в ходе работы алгоритма обучения множество миноров-эталонов как правило оказывается в значительной степени избыточным. Задачу минимизации их количества можно сформулировать в следующем виде:
Введем понятие бинарной матрицы покрытий
![]() размерности
размерности
![]() ,
где
,
где
![]() - количество элементов в выборке
- количество элементов в выборке
![]() (обучающая выборка после приведения
подобных векторов),
(обучающая выборка после приведения
подобных векторов),
![]() - количество м-э класса
- количество м-э класса
![]() .
Элементы матрицы
.
Элементы матрицы
![]() определяются следующим образом:
определяются следующим образом:

где
![]() -
-
![]() -ый
м-э класса
-ый
м-э класса
![]() ,
,
![]() -
-
![]() -ый
вектор обучающей выборки класса
-ый
вектор обучающей выборки класса
![]() .
.
Значение
![]() означает, что j-ый м-э класса
означает, что j-ый м-э класса
![]() поглощает
поглощает
![]() -ый
элемент обучающей выборки, то есть
правильно классифицирует его. Необходимо
найти множество м-э
-ый
элемент обучающей выборки, то есть
правильно классифицирует его. Необходимо
найти множество м-э
![]() ,
содержащее минимальное количество
членов и поглощающее обучающую выборку
,
содержащее минимальное количество
членов и поглощающее обучающую выборку
![]() ,
что сводится к нахождению минимального
набора столбцов матрицы
,
что сводится к нахождению минимального
набора столбцов матрицы
![]() ,
обеспечивающего выполнение условия:
,
обеспечивающего выполнение условия:
 .
.
Нахождение
![]() производится для каждого класса отдельно,
полученное множество м-э
производится для каждого класса отдельно,
полученное множество м-э
![]() обеспечивает решение поставленной
задачи в целом.
обеспечивает решение поставленной
задачи в целом.
В такой постановке задача сводится к
нахождению минимального покрытия
бинарной матрицы
![]() и в общем виде решается путем полного
перебора. В [21] предложен быстрый
субоптимальный алгоритм поиска
минимального покрытия бинарной матрицы,
заключающийся в следующем. В матрице
и в общем виде решается путем полного
перебора. В [21] предложен быстрый
субоптимальный алгоритм поиска
минимального покрытия бинарной матрицы,
заключающийся в следующем. В матрице
![]() выбирается
выбирается
![]() -я
строка, содержащая наименьшее количество
единиц. В случае наличия нескольких
таких строк выбирается любая из них
(например первая). Из всех столбцов,
имеющих элементы
-я
строка, содержащая наименьшее количество
единиц. В случае наличия нескольких
таких строк выбирается любая из них
(например первая). Из всех столбцов,
имеющих элементы
![]() выбирается столбец , содержащий наибольшее
количество единиц. При наличии нескольких
таких столбцов выбирается любой из них
(например первый). Соответствующий
данному столбцу м-э помещается в набор
выбирается столбец , содержащий наибольшее
количество единиц. При наличии нескольких
таких столбцов выбирается любой из них
(например первый). Соответствующий
данному столбцу м-э помещается в набор
![]() ,
а в матрице
,
а в матрице
![]() вычеркивается первый столбец и строки,
для которых выполняется условие
вычеркивается первый столбец и строки,
для которых выполняется условие
![]() .
Указанный процесс повторяется до тех
пор , пока в матрице
.
Указанный процесс повторяется до тех
пор , пока в матрице
![]() не будут вычеркнуты все строки. Очевидно,
что максимальное число итераций алгоритма
равно
не будут вычеркнуты все строки. Очевидно,
что максимальное число итераций алгоритма
равно
![]() ,
однако на практике он сходится значительно
быстрее.
,
однако на практике он сходится значительно
быстрее.
В практических задачах классификации
на основе наблюдений нескольких
разнородных групп признаков с целью
повышения помехозащищенности от сбоев
при принятии решений по отдельным
группам часто бывает важно включить в
окончательное решающее правило м-э с
наибольшими весами
![]() .
В этом случае для каждого класса
предварительно устанавливается граничное
значение веса
.
В этом случае для каждого класса
предварительно устанавливается граничное
значение веса
![]() и в набор м-э
и в набор м-э
![]() включаются все м-э, для которых выполняется
условие
включаются все м-э, для которых выполняется
условие
![]() .
После этого может быть сформирован
окончательный набор
.
После этого может быть сформирован
окончательный набор
![]() с использованием описанного выше
метода, причем матрица покрытия
с использованием описанного выше
метода, причем матрица покрытия
![]() строится только для векторов обучающей
выборки, не поглощаемых ни одним из уже
выбранных по критерию весов миноров-эталонов,
что существенно сокращает требования
к оперативной памяти и времени работы
при програмной реализации алгоритма.
строится только для векторов обучающей
выборки, не поглощаемых ни одним из уже
выбранных по критерию весов миноров-эталонов,
что существенно сокращает требования
к оперативной памяти и времени работы
при програмной реализации алгоритма.
После нахождения набора миноров-эталонов
производится формирование факторов
уверенности миноров. При этом среди
миноров-эталонов всех классов определяются
миноры с минимальными
![]() и максимальными
и максимальными
![]() весами. Этими весами назначаются факторы
уверенности
весами. Этими весами назначаются факторы
уверенности
![]() ,
,
![]() .
Фактор уверенности минора-эталона
определяется как
.
Фактор уверенности минора-эталона
определяется как
![]() ,
,
где
![]() - соответствующий вес
- соответствующий вес
![]() -го
минора-эталона. Диапазон изменения
значений
-го
минора-эталона. Диапазон изменения
значений
![]() определяется выбранной алгеброй факторов
уверенности.
определяется выбранной алгеброй факторов
уверенности.
При выбранных значениях
![]() и
и
![]() значения изменяются между этими двумя
значениями в зависимости от веса
минора-эталона. Очевидно, что миноры,
имеющие большие веса, имеют и большие
значения факторов уверенности и наоборот.
значения изменяются между этими двумя
значениями в зависимости от веса
минора-эталона. Очевидно, что миноры,
имеющие большие веса, имеют и большие
значения факторов уверенности и наоборот.