

Фазовая манипуляция сигналов
На практике часто применяются не обычная ОФМ, а ДОФМ (двойная относительная фазовая манипуляция) или ТОФМ (тройная относительная фазовая манипуляция). Главное их преимущество – это возможность передать в одной посылке сигнала сразу два информационных символа для ДОФМ и три – для ТОФМ. Это достигается за счет использования не двух, а четырех (ДОФМ) или восьми (ТОФМ) начальных фаз. Для ДОФМ, например, могут быть использованы следующий вариант: 0 градусов – передача "00", 90 – "01", 180 – "10", 270 – "11". Аналогично для ТОФМ, только для восьми начальных фаз: 0 градусов, 45, 90, 135 и т.д. Главным тормозящим фактором дальнейшего увеличения информационной емкости одной посылки сигнала является снижение помехозащищенности сигнала. Если фазовое расстояние между соседними символами уменьшается, то ошибка может быть создана меньшей по мощности помехой.
Также существуют и другие варианты фазовой манипуляции, которые привносят те или иные положительные свойства. Таким образом, фазовая манипуляция нашла наибольшее применение в системах связи исключительно за счет низкой доли фазовых помех в общей доле нежелательных внешних воздействий.
Кодирование информации
Для определения количества информации был найден способ представить любой ее тип (символьный, текстовый, графический) в едином виде, что позволило все типы информации преобразовать к единому стандартному виду. Таким видом стала так называемая двоичная форма представления информации. Она заключается в записи любой информации в виде последовательности только двух символов. Каждая такая последовательность называется двоичным кодом. Недостаток двоичного кодирования – длинные коды. Но в технике легче иметь дело с большим числом простых однотипных элементов, чем с небольшим числом сложных.
Количественное измерение информации. Двоичные символы могут кодироваться любым способом: буквами А, Б; словами ДА, НЕТ, двумя устойчивыми состояниями системы и т.д. Однако ради простоты записи были взяты цифры 1 и 0. Обработка информации в ЭВМ основана на обмене электрическими сигналами между различными устройствами машины. В компьютере, хранящем, либо обрабатывающем информацию, рассматриваемые символы 0 и 1 могут также обозначаться по-разному: один из них - наличием в рассматриваемом элементе электрического тока, либо магнитного поля, второй - отсутствием электрического тока, либо магнитного поля. Таким образом, в ЭВМ реализуются два устойчивых состояния. Эти два устойчивых состояния информационной системы определяют единицу измерения информации, называемую БИТОМ. Количество информации, кодируемое двоичной цифрой - 0 или 1, называется битом. Благодаря введению понятия единицы информации появилась возможность определения размера любой информации числом битов. Процесс получения двоичной информации об объектах исследования называют кодированием информации. Кодирование информации перечислением всех возможных событий очень трудоемко. Поэтому на практике кодирование осуществляется более простым способом. Он основан на том, что один разряд последовательности двоичных цифр имеет уже вдвое больше различных значений - 00, 01, 10, 11, чем одноразрядные 0 и 1. Трехразрядная последовательность имеет также вдвое больше значений - 000, 001, 010, 011, 100, 101, 110, 111, чем двухразрядная и т.д. Добавление одного разряда увеличивает число значений вдвое, это позволяет составить следующую таблицу информационной емкости чисел: Таблица 1. Информационная емкость чисел
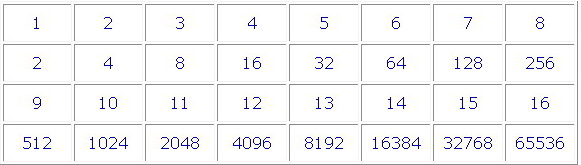 Пользуясь
вышеприведенной таблицей легко
закодировать любое множество событий.
Например, нам нужно закодировать 32 буквы
русского алфавита, для этой цели
достаточно взять пять разрядов, потому
что пятиразрядная последовательность
имеет 32 различных значения.
Для измерения
больших объемов информации пользоваться
битами неудобно. Поэтому применяются
кратные биту единицы измерения информации:
Пользуясь
вышеприведенной таблицей легко
закодировать любое множество событий.
Например, нам нужно закодировать 32 буквы
русского алфавита, для этой цели
достаточно взять пять разрядов, потому
что пятиразрядная последовательность
имеет 32 различных значения.
Для измерения
больших объемов информации пользоваться
битами неудобно. Поэтому применяются
кратные биту единицы измерения информации:
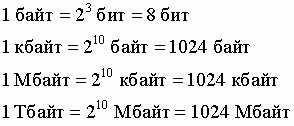
Кодирование различных типов информации с помощью набора битов, можно представить любое число и любой знак. В информационных документах широко используются не только русские, но и латинские буквы, цифры, математические знаки и другие специальные знаки, всего их количество составляет примерно 200-250 символов. Поэтому для кодировки всех указанных символов используется восьмиразрядная последовательность цифр 0 и 1. Таким образом, текстовая информация кодируется с помощью кодовой таблицы.
Кодовая таблица – это внутреннее преставление символов в компьютере. Во всем мире в качестве стандарта принята таблица ASCII – Американский стандартный код для обмена информацией. Для хранения двоичного кода одного символа выделен 1 байт = 8 бит. Следует отметить, что указанный способ кодирования используется тогда, когда к нему не предъявляются дополнительные требования, такие как необходимость указать на возникшую ошибку, исправление ошибки, секретность информации. При специальном кодировании коды получаются длиннее, чем в указанной таблице. Наиболее просто кодируется числовая информация – она переводится в двоичную систему исчисления. Для представления графической информации в двоичной форме используется так называемый поточечный способ. На первом этапе вертикальными и горизонтальными линиями делят изображение. Чем больше при этом получилось квадратов, тем точнее будет передана информация о картинке. Как известно из физики, любой цвет может быть представлен в виде суммы различной яркости зеленого, синего, красного цветов. Поэтому информация о каждой клетке должна содержать кодировку значения яркости и количеств зеленого, синего и красного компонентов. Таким образом кодируется растровое изображение – изображение, разбитое на отдельные точки. Объем растрового изображения определяется умножением количества точек на рисунке на информационный объем одной точки, который зависит от количества возможных цветов отображения (для черно-белого изображения информационный объем одной точки равен 1 биту и кодируется двумя цифрами – 0 или 1). Разные цвета и их оттенки получаются за счет наличия или отсутствия трех основных цветов – красного, синего, зеленого и их яркости. Каждая точка на экране кодируется с помощью 4 битов. Векторное изображение кодируется разбиением рисунка на элементарные отрезки, геометрические фигуры и дуги. Положение этих элементарных объектов определяется координатами точек. Для каждой линии указывается ее тип (сплошная, пунктирная, штрих- пунктирная ), толщина и цвет. Информация о векторном изображении кодируется как обычная буквенно-цифровая и обрабатывается специальными программами. Звуковая информация может быть представлена последовательностью элементарных звуков и пауз между ними. Вывод звуков из компьютера осуществляется синтезатором речи, который считывает из памяти хранящийся код звука. Речь человека имеет большое разнообразие оттенков, поэтому каждое произнесенное слово должно сравниваться с предварительно занесенным в память компьютера эталоном, и при их совпадении происходит его распознавание и запись.
Цифровое кодирование (Digital Encoding) иногда не совсем корректно называемое модуляцией определяет способ представления битов в физическом канале передачи данных.
Требования к алгоритмам цифрового кодирования
При кодировании цифровых сигналов должны выполняться следующие требования:
1. Малая полоса цифрового сигнала для того, чтобы можно было передать больший объем данных по имеющемуся физическому каналу.
2. Невысокий уровень постоянного напряжения в линии.
3. Достаточно высокие перепады напряжения для того, чтобы можно было использовать сигнальные импульсы (переходы напряжения) для синхронизации приемника и передатчика без добавления в поток сигналов дополнительной информации.
4. Сигнал должен быть неполяризованным для того, чтобы можно было не обращать внимания на полярность подключения проводников в каждой паре.
Обзор методов цифрового кодирования
NRZ - Non Return to Zero (без возврата к нулю)
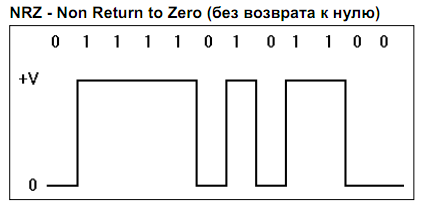
В этом варианте кодирования используется следующее представление битов:
♦ биты '0' представляются нулевым напряжением (0 В);
♦ биты '1' представляются напряжением +V.
Этот метод кодирования является наиболее простым и служит базой для построения более совершенных алгоритмов кодирования.
Кодированию по методу NRZ присущ целый ряд недостатков:
♦ высокий уровень постоянного напряжения (среднее значение 1/2V вольт для последовательности, содержащей равное число 1 и 0);
♦ широкая полоса сигнала (от 0 Гц для последовательности, содержащей только 1 или только 0 до половины скорости передачи данных при чередовании 10101010...);
♦ возможность возникновения продолжительных периодов передачи постоянного уровня (длинная последовательность 1 или 0) в результате чего затрудняется синхронизация устройств;
♦ сигнал является поляризованным.
RZ - Return to Zero (возврат к нулю)
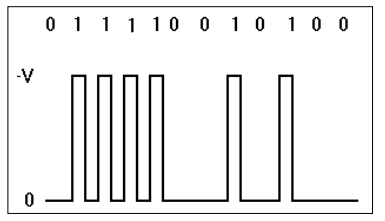
Цифровые данные представляются следующим образом:
♦ биты '0' представляются нулевым напряжением (0 В);
♦ биты '1' представляются значением +V в первой половине и нулевым напряжением – во второй, т.е. единице соответствует импульс напряжения продолжительностью в половину продолжительности передачи одного бита данных.
Этот метод имеет два преимущества по сравнению с кодированием NRZ:
♦ средний уровень напряжения в линии составляет 1/4V (вместо 1/2 V);
♦ при передаче непрерывной последовательности 1 сигнал в линии не остается постоянным.
Однако при использовании кодирования RZ полоса сигнала может достигать значений, равных скорости передачи данных (при передаче последовательности 1).
NRZ I - Non Return to Zero Invertive (инверсное кодирование без возврата к нулю)
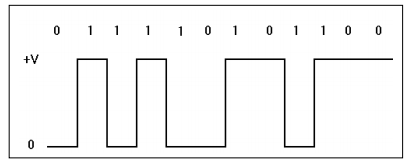
Этот метод кодирования использует следующие представления битов цифрового потока:
♦ биты '0' представляются нулевым напряжением (0 В);
♦ биты '1' представляются напряжением 0 или +V в зависимости от предшествовавшего этому биту напряжения – если предыдущее напряжение было равно 0, единица будет представлена значением +V, а в случаях, когда предыдущий уровень составлял +V для представления единицы будет использовано напряжение 0 В.
Этот алгоритм обеспечивает малую полосу (как при методе NRZ) в сочетании с частыми изменениями напряжения (как в RZ), а кроме того, обеспечивает неполярный сигнал (т. е. проводники в линии можно поменять местами).
AMI - Alternate Mark Inversion (поочередная инверсия единиц)
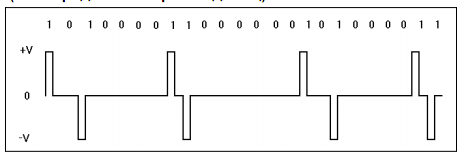
Этот метод кодирования использует следующие представления битов:
♦ биты '0' представляются нулевым напряжением (0 В);
♦ биты '1' представляются поочередно значениями +V и -V.
Этот метод подобен алгоритму RZ, но обеспечивает в линии нулевой уровень постоянного напряжения.
Недостатком метода AMI является ограничение на «плотность» нулей в потоке данных, поскольку длинные последовательности '0' ведут к потере синхронизации.
HDB3 - High Density Bipolar 3 (биполярное кодирование с высокой плотностью)
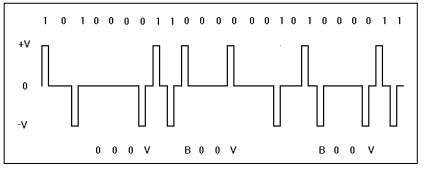
Представление битов в методе HDB3 лишь незначительно отличается от представления, используемого алгоритмом AMI:
При наличии в потоке данных 4 последовательных битов '0' последовательность изменяется на 000V, где полярность бита V такая же, как для предшествующего ненулевого импульса (в отличие от кодирования битов '1', для которых знак сигнала V изменяется поочередно для каждой единицы в потоке данных).
Этот алгоритм снимает ограничения на плотность '0', присущие кодированию AMI, но порождает взамен новую проблему – в линии появляется отличный от нуля уровень постоянного напряжения за счет того, что полярность отличных от нуля импульсов совпадает. Для решения этой проблемы полярность бита V изменяется по сравнению с полярностью предшествующего бита V. Когда это происходит, битовый поток изменяется на B00V, где полярность бита B совпадает с полярностью бита V. Когда приемник получает бит B, он думает, что этот сигнал соответствует значению '1', но после получения бита V (с такой же полярностью) приемник может корректно трактовать биты B и V как '0'.
Метод HDB3 удовлетворяет всем требованиям, предъявляемым к алгоритмам цифрового кодирования, но при использовании этого метода могут возникать некоторые проблемы.
PE - Phase Encode (Manchester, фазовое кодирование, манчестерское кодирование)
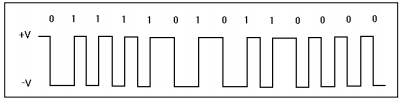
При фазовом кодировании используется следующее представление битов:
♦ биты '0' представляются напряжением +V в первой половине бита и напряжением -V – во второй половине;
♦ биты '1' представляются напряжением -V в первой половине бита и напряжением +V – во второй половине.
Этот алгоритм удовлетворяет всем предъявляемым требованиям, но передаваемый в линию сигнал имеет широкую полосу и является поляризованным.
CDP - Conditional
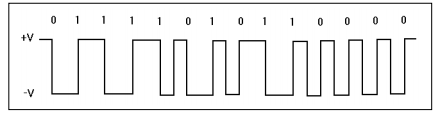
Этот метод является комбинацией алгоритмов NRZI и PE и использует следующие представления битов цифрового потока:
♦ биты '0' представляются переходом напряжения в том же направлении, что и для предшествующего бита (от +V к –V или от -V к +V);
♦ биты '1' представляются переходом напряжения в направлении, противоположном предшествующему биту (от +V к -V или от -V к +V).
Этот алгоритм обеспечивает неполярный сигнал, который занимает достаточно широкую полосу.
Заключение
Как вы увидели из приведенных описаний, существует достаточно много алгоритмов кодирования цифровых сигналов. Простейший метод NRZ используется в протоколах на базе интерфейса RS232, в сетях Ethernet применяется кодирование PE, а в телефонии используется алгоритм HDB3 (этот метод служит для кодирования сигналов в потоках E1 и E2). Выбор метода кодирования зависит от полосы канала связи, используемой кабельной системы, скорости передачи данных и других параметров.