

Нейронні мережі - Microsoft Neural Network
Алгоритм Microsoft Neural Network призначений для створення моделей класифікації і регресії шляхом конструювання багатошарової нейронної мережі перцептронов (перцептрон - математична та комп'ютерна модель сприйняття інформації мозком).
Як і у випадку алгоритму дерева рішень, для кожного стану вихідного атрибуту алгоритм обчислює розподіл ймовірності вхідних атрибутів. Обробляється повний набір записів, при цьому ітеративно порівнюються передбачені значення класифікатора з відомим значенням. Помилки класифікації на першій ітерації подаються на вхід мережі для зміни параметрів на наступній ітерації і т.д. Згодом, отримані ймовірності використовуються для прогнозування значення вихідного атрибуту на підставі значень вхідних атрибутів.
Одна із самих значних відмінностей між цим алгоритмом і алгоритмом дерева рішень полягає в тому, що процес навчання полягає в оптимізації параметрів мережі для мінімізації помилки класифікації, у той час як алгоритм дерева рішень здійснює розбиття вузлів для максимізації інформації (мінімізації ентропії).
Алгоритм підтримує як безперервні так і дискретні типи атрибутів.
Лінійна регресія - Microsoft Linear Regression
Алгоритм Microsoft Linear Regression являє собою алгоритм регресії є окремим випадком алгоритму Дерева рішень, що отримується в разі заборони на розбиття вузлів у дереві рішень. Формула регресії визначена на всьому обсязі даних, тобто на кореневому вузлі дерева. Алгоритм призначений для прогнозування безперервних атрибутів.
Логістична регресія - Microsoft Logistic Regression
Алгоритм Microsoft Logistic Regression являє собою алгоритм регресії є окремим випадком алгоритму Нейронних мереж, що отримується в разі видалення прихованого шару нейромережі. Алгоритм підтримує прогнозування значень як безперервних, так і дискретних атрибутів.
Таблиця рекомендацій використання алгоритмів для конкретних завдань
Задача |
Алгоритм |
Прогнозування дискретного атрибуту.
Як приклад можна виконати прогноз того, чи купить одержувач цільових рекламних розсилок певний продукт. |
Дерево рішень Наївний Байес Кластеризація Нейронні мережі |
Прогнозування безперервного атрибуту.
Наприклад, прогноз продажів на наступний рік. |
Дерево рішень Часові ряди
|
Прогнозування послідовності.
Наприклад, аналіз маршруту переміщення по веб-сайту компанії. |
Кластеризація послідовностей дій |
Знаходження груп загальних елементів в транзакції.
Наприклад, використання аналізу поведінки покупців для пропозиції додаткових продуктів замовнику. |
Дерево рішень Асоціативні правила |
Знаходження груп схожих елементів.
Наприклад, розбивка демографічних даних на групи для кращого розуміння зв'язків між атрибутами. |
Кластеризація Кластеризація послідовностей дій |
Перевірка моделей інтелектуального аналізу даних
Перевірка являє собою процес оцінки відповідності моделей інтелектуального аналізу даних фактичних даних. Важливо з'ясувати якість і характеристики моделей інтелектуального аналізу даних до їхнього розгортання в робітничому середовищі.
Для перевірка моделей інтелектуального аналізу даних можна використовувати вкладку Діаграма точності інтелектуального аналізу даних конструктора інтелектуального аналізу даних, щоб перевірити точність і порівняти прогнозуючі можливості моделей інтелектуального аналізу в структурі інтелектуального аналізу даних, приклад діаграми точності зображено на рис.4. Така превірка корисна при виборі відповідного алгоритму або налаштування параметрів конкретного алгоритму.
Рис 4. Діаграма точності прогнозів побудована засобами Data Mining

Заходи інтелектуального аналізу даних можна виділити в категорії точності, надійності та інформативності:
Точність - це міра того, наскільки вихідні дані моделі корелюють з атрибутами наданих даних. Є декілька заходів точності, але всі вони залежать від використовуваних даних. У реальності значення можуть бути відсутні або бути приблизними, а дані можуть змінюватися кількома процесами. Зокрема, на етапі перегляду або розгортання можна прийняти рішення про допущення певної кількості помилок в даних, особливо якщо характеристики даних відносно однорідні. Наприклад, модель, прогнозуюче обсяги продажів конкретного магазину на основі минулих обсягів продажу, може мати строгу кореляцію і бути дуже точною, навіть якщо в магазині постійно використовується неправильний метод бухгалтерського обліку. Вимірювання точності можуть бути збалансовані оцінкою надійності. Надійність відповідає поведінці моделі інтелектуального аналізу даних на різних наборах даних. Модель інтелектуального аналізу даних вважається надійною, якщо вона формує один і той же тип прогнозів або знаходить одні й ті ж загальні типи закономірностей, незалежно від наданий перевірочних даних.
Надійність відповідає поведінці моделі інтелектуального аналізу даних на різних наборах даних. Модель інтелектуального аналізу даних вважається надійною, якщо вона формує один і той же тип прогнозів або знаходить одні й ті ж загальні типи закономірностей, незалежно від наданий перевірочних даних. Так, наприклад, модель, створена для магазину, де використовується неправильний метод бухгалтерського обліку, не підходить для інших магазинів і тому не може вважатися надійною.
Інформативність об'єднує в собі кілька метрик, що дозволяють зрозуміти, наскільки корисна інформація, що отримується з моделі. Наприклад, модель інтелектуального аналізу, в якій розташування магазину співвідноситься з обсягами продажу, може бути точною і надійною, але не інформативною, якщо її не можна застосувати після додавання інших магазинів у тому ж розташуванні. Більш того, вона не містить відповіді на основне питання про те, чому обсяги продажів у певних місцях більше, ніж в інших. Крім того, успішна модель може виявитися насправді безглуздою через взаємну кореляції в даних.
В службах Analysis Services для перегляду і дослідження моделі передбачено низку засобів перегляду інтелектуального аналізу даних. Крім того, можна створювати запити до вмісту, що дозволяють краще розібратися в моделі і виявити непередбачені помилки у власному підході або в даних. Коли запит вмісту створюється за допомогою розширень інтелектуального аналізу даних, можна отримати статистичні відомості про закономірності, виявлених моделлю інтелектуального аналізу даних, або виділити варіанти, які підтримують певні закономірності, виявлені цією моделлю. Можлива деталізація, аж до базової структури інтелектуального аналізу даних, що дозволяє знайти або представити докладні відомості, не включені в модель, або виконати необхідні дії з виявленими в даних закономірностями.
Запити до моделей інтелектуального аналізу даних
Основною метою більшості проектів інтелектуального аналізу даних є використання моделей інтелектуального аналізу даних для створення прогнозів нових даних.
Прогнозуючі запити засновані на мові розширень інтелектуального аналізу даних. Мова розширень доповнює мову SQL для забезпечення підтримки робочих моделей інтелектуального аналізу даних.
SQL Server надає два засоби, які можна використовувати для побудови прогнозуючих запитів:
конструктор прогнозуючих запитів міститься на вкладці Прогноз моделі інтелектуального аналізу. При використанні конструктора запитів можна використовувати графічні засоби для проектування запиту, використовувати текстовий редактор для зміни запиту вручну і використовувати просту область результатів для перегляду результатів запиту.
редактор запитів надає засоби, які можна використовувати для побудови та виконання запитів розширень інтелектуального аналізу даних. Розширення інтелектуального аналізу даних можуть використовуватися для створення структури нових моделей інтелектуального аналізу даних, навчання цих моделей, а також для здійснення огляду, управління та прогнозування за цими моделями.
Використання конструктора прогнозуючих запитів
Конструктор прогнозуючих запитів міститься на вкладці Прогноз моделей інтелектуального аналізу конструктора інтелектуального аналізу даних. Ця вкладка містить наступні підменю:
Конструювання
Запит
Результат
Можна побудувати запит, використовуючи комбінацію візуальних засобів на екрані Конструювання і текстовий редактор, що надає безпосередній доступ до DMX-запитів, на екрані Запит. Запит виконується при відкритті екрану Результат і відображає результати в сітці.
Підменю Конструювання
Таблиці Модель інтелектуального аналізу даних і Вибір вхідних таблиць знаходяться у верхній частині екрана Конструювання. Вони призначені для вибору моделі інтелектуального аналізу даних і вхідну таблицю, на підставі яких необхідно створювати прогнози. Можна використовувати будь-яку модель інтелектуального аналізу даних у проекті і будь-яку вхідну таблицю в уявленнях джерел даних. Можна створювати прогнози, не використовуючи вхідну таблицю. Замість прив'язки моделі інтелектуального аналізу даних до джерела даних можна подавати дані безпосередньо в модель інтелектуального аналізу даних, створюючи одноелементні запит. Додаткові відомості про створення одноелементні запитів наведені в наступному підпункті.
Для вибору моделі, натискаємо кнопку Вибрати модель, при цьому відкриється діалогове вікно Вибір моделі інтелектуального аналізу даних. Це діалогове вікно містить деревоподібну структуру, в якій наведено список структур для проекту і моделей, пов'язаних з кожної зі структур.
Гіперпосилання, пов'язані з таблицею Вибір вхідних таблиць, дають змогу вибрати таблицю варіантів, додати вкладену таблицю, змінити з'єднання і видалити таблиці.
Після вибору моделі і вхідний таблиці спільні стовпці, що присутні в них обох, співставляються. Можна вручну налаштувати співставлення, перетягуючи ім'я стовпця з однієї таблиці в іншу. Також можна видаляти співставлення між двома стовпцями, видаливши з'єднуючу лінію.
Побудова прогнозуючому запиту проводиться в сітці в нижній частині екрана Конструювання. Можна перетягувати стовпці в сітку, щоб включити їх у прогнозуючий запит. Сітка містить стовпці, опис яких наведено в наступному списку:
Джерело - визначає джерело нового стовпця. Можливі джерела включають модель інтелектуального аналізу даних, вхідні таблиці, функцію прогнозування або користувальницьке вираз.
Поле - визначає конкретний стовпець або функцію, пов'язану з елементом, обраним в стовпці Джерело.
Псевдонім - визначає, як стовпець буде називатися в результуючому наборі.
Відображення - визначає, чи відображається елемент, вибраний у стовпці Джерело, в результатах.
Група - працює із стовпцем І/АБО для групування виразів з використанням дужок. Наприклад, (expr1 або expr2) і expr3.
І/АБО - створює логіку у запиті. Наприклад, (expr1 або expr2) і expr3.
Критерій / Аргумент - вказується умова або вираз, що застосовується до колонки. Можна перетягувати стовпці з таблиць в клітинку.
Після побудови запиту можна переглянути створену інструкцію розширень інтелектуального аналізу даних або ознайомитися з результатами.
Підменю Запит
При виборі екрану Запит сітка, яка використовується для визначення запиту, замінюється базовим текстовим редактором. У ньому можна відредагувати запит або скопіювати його в буфер обміну. При внесенні змін до запиту в текстовому редакторі і перемиканні назад до підменю Конструювання всі зміни губляться і запит повертається в початковий вигляд.
Підменю Результат
На екрані Результат відображається сітка результатів, що повертаються DMX-запитом, побудованим на екрані Конструювання або зміненим на екрані Запит. Можна повторно запустити запит, натиснувши кнопку Виконати в правому нижньому кутку.
Одноелементні запити
Конструктор прогнозуючих запитів можна налаштувати на просте створення одноелементних прогнозуючих запитів, на вкладці Прогноз моделі інтелектуального аналізу в конструкторі інтелектуального аналізу даних. Для одноелементних запитів не потрібна вхідна таблиця. Набір даних передається в модель, з якої одноелементні прогноз повертається в режимі реального часу. У порівнянні з цим звичайні прогнозуючі запити створюють пакетні прогнози, засновані на даних, що містяться в таблиці.
Створення одноелементних прогнозів
Щоб налаштувати будівник запитів на створення одноелементні прогнозів, натисніть кнопку Одноелементні запити. Після цього діалогове вікно Вибір вхідних таблиць зміниться діалоговим вікном Введення одноелементного запиту. Буде здійснено автоматичне зіставлення стовпців між діалоговим вікном Модель інтелектуального аналізу даних і діалоговим вікном Введення одноелементного запиту, оскільки стовпці в обох вікнах виводяться з однієї і тієї ж моделі інтелектуального аналізу даних.
Після появи нового діалогового вікна його можна використовувати для зазначення даних, які будуть використовуватися для створення запиту. Якщо модель містить вкладені таблиці, клацніть стовпець значення для стовпця вкладеної таблиці, щоб відкрити діалогове вікно Введення вкладеної таблиці. Його можна використовувати для вибору стану колонок для включення в запит.
Наприклад, відкрийте модель інтелектуального аналізу даних «Цільова розсилка» у зразку бази даних Adventure Works DW і перейдіть на вкладку Прогноз моделі інтелектуального аналізу. Після натискання кнопки одноелементні запит відобразиться діалогове вікно Введення одноелементні запиту, заповнене стовпцями з моделі TM_Decision_Tree (перші моделі в структурі). Припустимо, що необхідно створити запит, який прогнозує, чи придбає замовник, який має певні характеристики, велосипед у компанії.
Характеристики замовника
Вік 35 років;
Одружений;
Дома двоє дітей;
Живе в 10 милях від роботи.
Якщо ввести ці дані в стовпчик значень в діалоговому вікні і перетягнути стовпець «Покупець велосипеда» з діалогового вікна Модель інтелектуального аналізу даних у стовпець Джерело сітки, то цих установок достатньо для завершення запиту. При перемиканні в область результатів у Конструкторі запитів відобразиться, що цей замовник, швидше за все, придбає велосипед.
Редактор запитів
У редакторі запитів можна створити власний запит або використовувати шаблон загальних задач, наприклад створення нової моделі інтелектуального аналізу даних.
Побудова та запуск запитів
Щоб відкрити новий DMX-запит, клацніть пункт Створити запит у середовищі Management Studio і виберіть пункт Створити запит розширень інтелектуального аналізу служб Analysis Server. У діалоговому вікні, Підключитися до сервера виберіть екземпляр служб Analysis Services, що містить моделі інтелектуального аналізу даних.
Редактор запитів містить наступні елементи:
Список з усіма моделями інтелектуального аналізу даних у вибраній базі даних служб Analysis Services.
Вкладка з представленнями дерева всіх стовпців у вибраній моделі інтелектуального аналізу даних.
Вкладка з усіма функціями, які можна використовувати з кожним типом моделі.
Текстовий редактор, який використовується для створення запитів розширень інтелектуального аналізу.
Щоб перевірити синтаксис запиту, натисніть кнопку Синтаксиячний Аналіз. Щоб запустити запит, натисніть кнопку Виконати. Щоб зупинити виконання запиту, натисніть кнопку Скасувати виконання запиту.
На вкладці Результати внизу вікна відображаються результати запиту. На вкладці Повідомлення відображаються всі повідомлення, пов'язані з виконанням запиту.
Після вибору моделі в списку Моделі інтелектуального аналізу даних можна перетягнути стовпці або функції із перегляду дерева в лівій частині вікна в текстовий редактор.
Шаблони
Шаблони для створення основних запитів розширень інтелектуального аналізу знаходяться в меню шаблонів. Щоб відкрити меню шаблонів, виберіть пункт Меню шаблонів у вкладці Вигляд. Клацніть значок Служби Analysis Server, щоб переглянути предствалення дерева шаблонів, які можна застосувати до служб Analysis Services. Папка Розширення інтелектуального аналізу даних містить шаблони інтелектуального аналізу даних, розділені на папки Вміст моделі, Управління моделлю і Прогнозуючі запити.
Додатки
Рис 5. Редактор Data Mining

Рис 6. Діаграма Decision Tree

Рис 7. Сторінка Dependency Network - відносини між атрибутами, що впливають на прогнозуючому здатність моделі.

Рис 8. Кластерна діаграма

Рис 9. Сторінка Cluster Profiles (Профілі кластерів)

Рис 10. Сторінка Cluster Discrimination показує характеристики, що відрізняють один кластер від іншого.
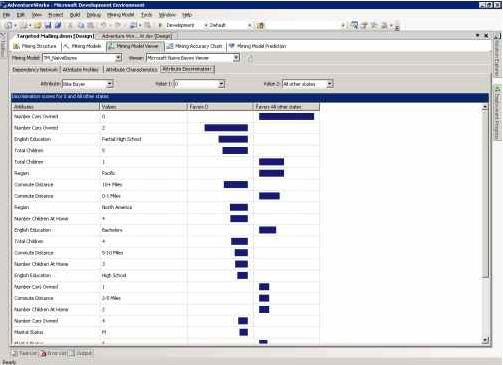
Тестування точності Data Mining-моделей
Рис 11. Сторінка Mining Accuracy Chart
Рис 12. Зв’язуємо стовпці
Рис 13. Точність кожної моделі в порівнянні з ідеальною моделлю.

Створення запитів
Рис 14. Prediction Query Builder – загальний вигляд.

Рис 15. Співставлення стовпців

Рис 16. Построєний запит

Рис 17. Результат виконання запиту

Висновки
SQL Server 2005 Analysis Services надає набір високоінтегрірованних інструментів допомоги підприємницькій діяльності, що дозволяє оцінити весь спектр можливостей інтелектуального аналізу даних, будь то інтегрування даних з безлічі додатків в єдиний формат, аналіз даних із різноманітних джерел, створення звітів на основі даних з використанням безлічі форматів і технологій, видобутку даних для створення взаємозв'язків або прогнозування майбутніх результатів за допомогою прогнозуючої аналітики.
Використання SQL Server 2005 Analysis Services дає змогу після опрацювання великих обсягів даних знайти в них закономірності та на цій підставі створити прогноз поведінки системи при виникненні таких умов. При цьому немає потреби писати складні математичні системи, оскільки про це вже поклопоталася корпорація Microsoft, яка реалізувала так звані моделі аналізу даних у готовому вигляді.
Завдяки всім цим факторам засоби Analysis Services здатні надати неймовірну потужність і серйозний аналітичний інструментарій організаціям будь-якого розміру.