

16. Технологии информирования. Основные схемы видов информирования: трансинформирование,
дезинформирование, псевдоинформирование, конфузионное информирование.
Трансинформирование – правдивое информирование, при котором информация от ис-точника воздействия (индуктора) передается к приемнику воздействия (реципиенту) без ис-кажения.
Дезинформирование заключается в намеренном предоставлении объекту такой инфор-мации, которая вводит его в заблуждение относительно истинного положения дел. Оно включает в себя использование заведомо ложных данных и сведений
Псевдоинформирование – полуправдивое, полуложное информирование, при котором в определенных пропорциях присутствуют как правда, так и ложь, логически взаимосвязанные между собой.
Псевдоинформирование осуществляется путем увеличения или уменьшения объема ин-формации. Избыточное целенаправленное информирование позволяет создавать ложное представление о наличии чего–либо. Обобщенное информирование создает расплывчатые (неясные) образы. Кажущееся информирование связано с повторением чужого оригинала, при чем оригинал каждый раз меняется на равнозначный.
Комбинация ложных и скрытых оригиналов называется конфузионным дезинформиро-ванием. Информирование, которое в одних случаях приводит к превратному, в других – не-удачному, в–третьих – необоснованному толкованию (объяснению) информации, называют парадезинформированием
17. Обобщенная схема абстрактного технологического процесса. Классы ит.
Целевая обработка — это функционально-ориентированное преобразование получаемых или хранимых объектов обработки, обеспечивающее получение проектного результата под управлением субъекта (в качестве которого, так или иначе, выступает человек).
Информационные ресурсы — внешние по отношению к функциональному процессу источники информации, использование которых (обычно при управлении процессом) позволяет обеспечить эффективность целевой обработки.
Интерфейсные средства реализуют тот или иной способ (режим) взаимодействия субъекта с компонентами функциональной обработки.
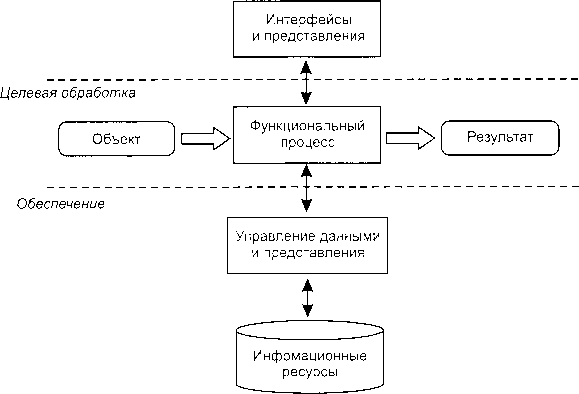
Таким образом, с точки зрения обобщенной схемы, представленной на рис. 1.6. ИТ можно подразделить на три основных класса:
технологии собственно обработки информации (ввода, обработки, хранения, поиска и передачи данных):
технологии человеко-машинного взаимодействия, реализуемые в интерфейсах:
инструментальные и другие вспомогательные технологии, позволяющие эффективно создавать и развивать ИТ предшествующих классов.
Отметим, что такое разделение, отражающее специализироваи- ность используемых методов и средств, соответствует и «специализации» пользователей соответствующих технологий, где давно сложилось разделение на «разработчиков», «конечных пользователей» и «администраторов». С точки зрения этой «специализации» представляется целесообразным подразделять технологии на базовые, обеспечивающие и инструментальные.
18. Технологии распределенной обработки данных. Типовые схемы организации хранения данных и доступа по технологии «клиент-сервер».
Следует выделить два класса систем распределенной обработки и системы распределенных данных:
системы распределенной обработки в основном отражают структуру и свойства многопользовательских операпион- ных систем с базой данных, размешенной на центральном компьютере;
Основные условия и требования к распределенной обработке данных:
прозрачность относительно расположения данных (СУБД должна представлять все данные так, как если бы они были локальными);
гетерогенность системы (СУБД должна работать с данными, которые хранятся в системах с различной архитектурой и производительностью);
прозрачность относительно сети (СУБД должна одинаково работать в условиях разнородных сетей);
поддержка распределенных запросов (пользователь должен иметь возможность объединять данные из любых баз, даже если они размешены в разных системах);
поддержка распределенных изменений (пользователь должен иметь возможность изменять данные в любых базах, на доступ к которым у него есть права, даже если эти базы размещены в разных системах);
поддержка распределенных транзакций (СУБД должна выполнять транзакции, выходящие за рамки одной вычислительной системы, и поддерживать целостность распределенной БД даже при возникновении отказов как в отдельных системах, так и в сети);
безопасность (СУБД должна обеспечивать защиту всей распределенной БД от несанкционированного доступа);
универсальность доступа (СУБД должна обеспечивать единую методику доступа ко всем данным).
Одной из важнейших сетевых технологий является распределенная обработка данных. Персональные компьютеры стоят на рабочих местах, т.е. на местах возникновения и использования информации. Они соединены каналами связи. Это дало возможность распределить их ресурсы по отдельным функциональным сферам деятельности и изменить технологию обработки данных в направлении децентрализации. Распределенная обработка данных позволила повысить эффективность удовлетворения изменяющейся информационной потребности информационного работника и тем самым обеспечить гибкость принимаемых им решений. Преимущества распределенной обработки данных: большое число взаимодействующих пользователей, выполняющих функции сбора, регистрации, хранения, передачи и выдачи информации; снятие пиковых нагрузок с централизованной базы путем распределения обработки и хранения локальных баз данных на разных ЭВМ; обеспечение доступа информационному работнику к вычислительным ресурсам сети ЭВМ; обеспечение симметричного обмена данными между удаленными пользователями.
Формализация концептуальной схемы данных повлекла за собой возможность к классификации моделей представления данных на иерархические, сетевые и реляционные. Это отразилось в понятии архитектуры систем управления базами данных и технологии обработки. Архитектура СУБД описывает ее функционирование как взаимодействие процессов двух типов клиента и сервера.
Клиент-серверные архитектуры распределенной обработки данных
Практически все модели организации взаимодействия пользователя с базой данных, построены на основе модели «клиент — сервер». То есть предполагается, что приложения, реализующие какой-либо тип модели, отличаются способом распределения функций ранее приведенных групп обработки данных между как минимум двумя частями:
клиентской, которая отвечает за целевую обработку данных и организацию взаимодействия с пользователем;
серверной, которая обеспечивает хранение данных, обрабатывает запросы и посылает результаты клиенту для специальной обработки.
В общем случае предполагается, что эти части приложения функционируют на отдельных компьютерах, т. е. к серверу БД с помощью сети подключены компьютеры пользователей (клиенты).
Сервер — это программа, реализующая функции собственно СУБД: определение данных, запись-чтение данных, поддержка схем внешнего, концептуального и внутреннего уровней, диспетчеризация и оптимизация выполнения запросов, защита данных.
Клиент — это различные программы, написанные как пользователями, так и поставщиками СУБД, внешние или «встроенные» по отношению к СУБД. Программа-клиент организована в виде приложения, работающего «поверх» СУБД и обращающегося для выполнения операций над данными к компонентам СУБД через интерфейс внешнего уровня. Инструментальные средства, в том числе и утилиты, не отнесены к серверной части очень условно. Являясь не менее важной составляющей, чем ядро СУБД, они выполняются самостоятельно, как пользовательское приложение.
Основной принцип технологии «клиент—сервер» заключается в разделении функций стандартного интерактивного приложения на четыре группы, имеющие различную природу:
функции ввода и отображения данных;
чисто прикладные функции, характерные для данной предметной области (например, для банковской системы — открытие счета, перевод денег с одного счета на другой и т. д.);
фундаментальные функции хранения и управления информационными ресурсами (базами данных, файловыми системами и т. д.);
служебные, играющие роль интерфейсов между функциями первых трех групп.
Выделяются четыре основных подхода, реализованные в следующих моделях (или схемах):
файловый сервер (File Server — FS);
доступ к удаленным данным (Remote Data Access — RDA);
север базы данных (DataBase Server — DBS);
сервер приложений (Application Server — AS).
19. Коммуникативные форматы. Назначение. Принципы построения «самоопределенных форматов.
20. Объектная модель документа.
21. XML. Назначение. Основные элементы языка. DTD, XML-схема.
XML-технологии — современное развитие инструментария HTML и SGML. В начале февраля 1998 г. международная ассоциация W3C утвердила спецификацию «Extensible Markup Language(XML) 1.0», Сегодня появляются новые языки, созданные на основе XML. Возникают многочисленные Web-серверы, использующие и технологию XML для организации хранящейся на них информации.
Упрощая ситуацию, можно сказать, что разработчики XML взяли лучшие решения SGML и. руководствуюсь опытом HTML, создали язык, не уступающий по мощности SGML, но гораздо более удобный и легкий в использовании. XML предназначен для создания новых языков разметки и используется в качестве средства для описания грамматики других языков и контроля за правильностью составления документов.
С его помощью можно описать целый класс агрегатов данных, называемых X М L - д о к у м е н т а м и. ориентированными на конкретную предметную область. XML позволяет определить допустимый набор тэгов, их атрибуты и внутреннюю структуру документа. Тэги (подобно тэгам в HTML) представляют специальные инструкции, предназначенные для формирования в документах определенной структуры и четких отношений между различными элементами этой структуры. Для описания данных XML использует DTD (Document Type Definition — Определение типа документа) или схему документа.