

34. Основные принципы систем автоматизированного перевода
Перевод с одного языка на другой человеком происходит путем восприятия и понимания исходного текста и последующей передачи его смысла средствами выходного языка. При этом переводятся не слова и словосочетания, а понятийные образы, порождаемые в сознании переводчика под их воздействием. Однако если в настоящее время пока еще нет возможности моделировать работу человека-переводчика, то, по крайней мере, нужно стремиться оперировать теми единицами языка и речи, которые позволяют наиболее точно передавать содержание текста, написанного на одном языке, средствами другого языка. Такими единицами являются, прежде всего, фразеологические обороты и терминологические словосочетания и. во вторую очередь, отдельные слова. Если в настоящее время полностью автоматический высококачественный научно-технический перевод практически невозможен, то автоматизированный человеко-машинный перевод вполне реален.
Обобщенная технология работы системы машинного перевода
Процесс машинного перевода текстов с одного естественного языка на другой может быть в крупном плане разделен на три этапа (рис. 4.14).
Текст на входном языке поступает в систему перевода, на этапе с е м а н т и к о - с и н т а к с и ч е с к о г о анализа выявляется его грамматическая структура, распознаются наименования понятий и устанавливаются отношения между понятиями.
На этапе трансфера производится переход от наименований понятий и структуры текста на входном языке к наименованиям понятий и структуре текста на выходном языке. В результате семантик о- синтаксического синтеза на основании полученных эквивалентов получается текст на выходном языке (его грамматическое оформление), который выдается в качестве результата.
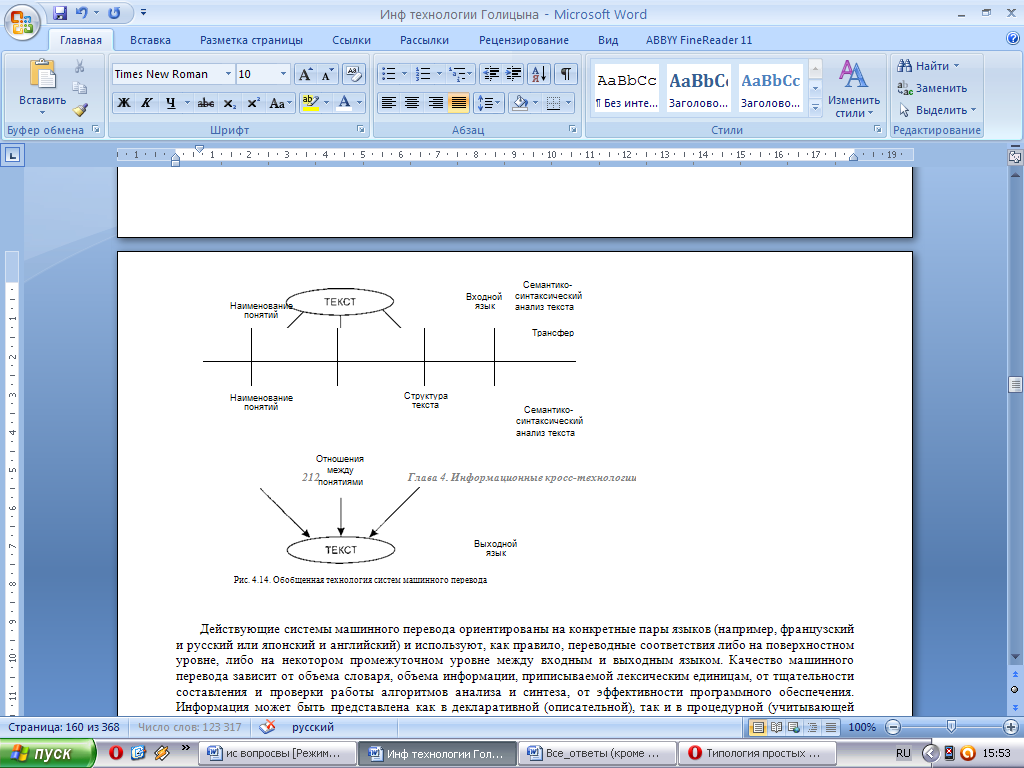
Действующие системы машинного перевода ориентированы на конкретные пары языков (например, французский и русский или японский и английский) и используют, как правило, переводные соответствия либо на поверхностном уровне, либо на некотором промежуточном уровне между входным и выходным языком. Качество машинного перевода зависит от объема словаря, объема информации, приписываемой лексическим единицам, от тщательности составления и проверки работы алгоритмов анализа и синтеза, от эффективности программного обеспечения. Информация может быть представлена как в декларативной (описательной), так и в процедурной (учитывающей потребности алгоритма) форме.
Машинный перевод следует отличать от использования компьютеров в помощь человеку-переводчику. В последнем случае имеется в виду автоматический словарь, помогающий человеку быстрее подбирать нужный переводной эквивалент. Хотя и в том, и в другом случае компьютер работает вместе с человеком (переводчиком или редактором), в содержание термина «машинный перевод» входит представление о том, что главную, большую часть работы по переводу и отысканию переводных эквивалентов и переводных соответствий машина берет на себя оставляя человеку лишь контроль и исправление ошибок, в то время как компьютерный словарь в помощь человеку — это чисто вспомогательное средство.
Основные проблемы машинного перевода
Для создания систем, работающих со всем естественным языком без потери глубины анализа, в настоящий момент не хватает либо технических возможностей (быстродействия, памяти), либо теоретической базы. Однако в коммерческих системах, ввиду того, что предназначаются они для большого количества пользователей, разных предметных областей, принята концепция поверхностного анализа, к тому же и производится такой анализ значительно быстрее.
Исторически машинный перевод является первой попыткой использования компьютеров для решения невычислительных задач (Джорджтаунский эксперимент в США в 1954 г.; работы по машинному переводу в СССР, начавшиеся в 1954 г.). Развитие электронной техники, рост объема памяти и производительности компьютеров создавали иллюзию быстрого решения этой задачи. Практическая цель была простой: загрузить в память компьютера максимально возможный словарь и с его помощью из иноязычных текстов получать текст на родном языке в удобочитаемом виде. Однако первоначальная эйфория по поводу того, что столь трудоемкую работу можно поручить ЭВМ, сменилась разочарованием в связи с абсолютной непригодностью получаемых текстов.
Конечно, системы, настроенные на определенную предметную область, дают гораздо более приемлемые результаты. Однако в этом случае системы перевода получаются очень узко ориентированными, и попытка использовать их даже в смежных предметных областях дает совершенно непредсказуемые результаты.
Возникают эти проблемы из-за принципиально разных подходов к переводу человека и машины. Квалифицированный переводчик понимает смысл текста и пересказывает его на другом языке словами и стилем, максимально близкими к оригиналу. Для компьютера этот путь выливается в решение двух задач:
перевод текста в некоторое внутреннее семантическое представление;
генерация по этому представлению текста на другом языке.
Поскольку не только не решена сама по себе ни одна из этих задач, и даже нет общепринятой концепции семантического представления текстов, при автоматическом переводе приходится фактически делать «подстрочник», заменяя по отдельности слова одного языка на слова другого и пытаясь после этого придать получившемуся предложению некоторую синтаксическую согласованность. Смысл при этом может быть искажен или безвозвратно утерян.