

Передача информации с периферийного устройства в ядро ЭВМ называется операцией ввода, а передача из ядра ЭВМ в периферийное устройство - операцией вывода.
Связь устройств ЭВМ друг с другом осуществляется с помощью средств сопряжения - интерфейсов.
Интерфейс представляет собой совокупность линий и шин, сигналов, электронных схем и алгоритмов, предназначенную для осуществления обмена информацией между устройствами. От характеристик интерфейсов во многом зависят производительность и надежность вычислительной машины.
При разработке систем ввода-вывода должны быть решены следующие проблемы: 1) Должна быть обеспечена возможность реализации машин с переменным составом оборудования. 2) Для эффективного использования оборудования ЭВМ должны реализовываться параллельная во времени работа процессора над программой и выполнение периферийными устройствами процедур ввода-вывода. 3) Необходимо стандартизировать программирование операций ввода-вывода для обеспечения их независимости от особенностей периферийного устройства. 4) Необходимо обеспечить автоматическое распознавание и реакцию ядра ЭВМ на многообразие ситуаций, возникающих в ПУ (готовность устройства, различные неисправности и т.п.).
В системах ввода-вывода ЭВМ используются два основных способа организации передачи данных между памятью и периферийными устройствами: программно-управляемая передача и прямой доступ к памяти.
Программно-управляемая передача данных осуществляется при непосредственном участии и под управлением процессора, который при этом выполняет специальную подпрограмму процедуры ввода-вывода. Данные между памятью и периферийным устройством пересылаются через процессор.
Операция ввода - вывода инициируется текущей командой программы или запросом прерывания от периферийного устройства. При этом процессор на все время выполнения операции ввода-вывода отвлекается от выполнения основной программы.
Кроме того при пересылке блока данных процессору приходится для каждой единицы передаваемых данных выполнять несколько команд, чтобы обеспечить буферизацию, преобразование форматов данных, подсчет количества переданных данных, формирование адресов в памяти и т.п. Это сильно снижает скорость передачи данных (не выше 100 Кб/сек), что недопустимо при работе с высокоскоростными ПУ. Между тем потенциально возможная скорость обмена данными при вводе-выводе определяется пропускной способностью памяти.
Для быстрого ввода-вывода блоков данных используется прямой доступ к памяти.
Прямым доступом к памяти называется способ обмена данными, обеспечивающий независимую от процессора передачу данных между памятью и периферийным устройством.
Прямым доступом к памяти управляет контроллер ПДП, который выполняет следующие функции:
1) управление инициируемой процессором или ПУ передачей данных между ОП и ПУ;
2) задание размера блока данных, который подлежит передаче, и области памяти, используемой при передаче;
3) формирование адресов ячеек ОП, участвующих в передаче;
4) подсчет числа переданных единиц данных (байт или слов) и определение момента завершения операции ввода-вывода.
Указанные функции реализуются контроллером ПДП с помощью одного или нескольких буферных регистров, регистра - счетчика текущего адреса данных и регистра-счетчика подлежащих передаче данных. При инициировании операции ввода-вывода в счетчик подлежащих передаче данных заносится размер передаваемого блока (число байт или слов), а в счетчик текущего адреса - начальный адрес области памяти, используемой при передаче. При передаче каждого байта содержимое счетчика адреса увеличивается на 1, при этом формируется адрес очередной ячейки памяти, участвующей в передаче.
Одновременно уменьшается на 1 содержимое счетчика подлежащих передаче данных; обнуление этого счетчика указывает на завершение передачи.
Контроллер ПДП обычно имеет более высокий приоритет в занятии цикла обращения к памяти по сравнению с процессором. Управление памятью переходит к контроллеру ПДП, как только завершается цикл обращения к памяти для текущей команды процессора. Прямой доступ к памяти обеспечивает высокую скорость обмена данными за счет того, что управление обменом производится не программными, а аппаратными средствами. Можно выделить два характерных принципа построения систем ввода-вывода: ЭВМ с одним общим интерфейсом и ЭВМ с множеством интерфейсов и процессорами (каналами) ввода-вывода.
Интерфейсы межмашинного обмена обычно последовательные, в которых обмен информацией производится по одному биту последовательно.
Для параллельного и последовательно-параллельного интерфейса необходимо, чтобы участники общения были связаны многожильным интерфейсным кабелем (количество жил не меньше числа одновременно передаваемых разрядов - битов). В последовательных интерфейсах участники общения связываются друг с другом одно-двухпроводной линией связи, световодом, коаксиальным кабелем, радиоканалом.
В зависимости от используемых при обмене программно-технических средств интерфейсы ввода-вывода делятся на два уровня: физический и логический (рис.6.2).
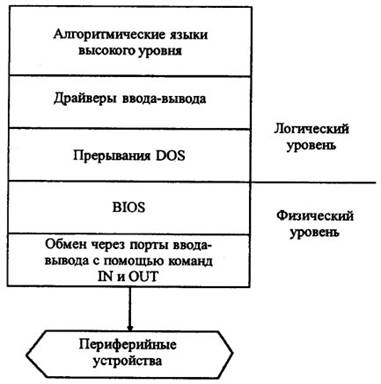
Рис. 6.2. Логический и физический уровни интерфейсов ввода-вывода
В зависимости от степени участия центрального процессора в обмене данными в интерфейсах могут использоваться три способа управления обменом:
режим сканирования (так называемый "асинхронный" обмен);
синхронный обмен;
прямой доступ к памяти.
Для внутреннего интерфейса ЭВМ режим сканирования предусматривает опрос центральным процессором периферийного устройства (ПФУ): готово ли оно к обмену, и если нет - продолжение опроса периферийного устройства (рис.6.3).
Операция пересылки данных логически слишком проста, чтобы эффективно загружать сложную быстродействующую аппаратуру процессора, в результате чего в режиме сканирования снижается производительность вычислительной машины.
Вместе с тем при пересылке блока данных процессору приходится для каждой единицы передаваемых данных (байт, слово) выполнять довольно много команд, чтобы обеспечить буферизацию данных, преобразование форматов, подсчет количества переданных данных, формирование адресов в памяти и т.п. В результате скорость передачи данных при пересылке блока данных даже через высокопроизводительный процессор может оказаться неприемлемой для систем управления, работающих в реальном масштабе времени.
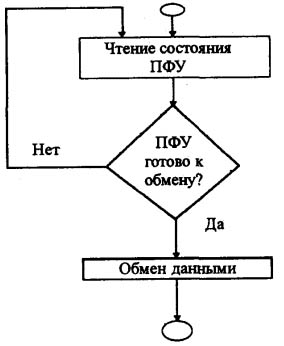
Рис. 6.3. Алгоритм сканирования
Режим сканирования упрощает подготовку к обмену, но имеет рад недостатков:
процессор постоянно задействован и не может выполнять другую работу;
при большом быстродействии периферийного устройства процессор не успевает организовать обмен данными.
В синхронном режиме центральный процессор выполняет основную роль по организации обмена, но в отличие от режима сканирования не ждет готовности устройства, а осуществляет другую работу. Когда в нем возникает нужда, внешнее устройство с помощью соответствующего прерывания обращает на себя внимание центрального процессора.
Для быстрого ввода-вывода блоков данных и разгрузки процессора от управления операциями ввода-вывода используют прямой доступ к памяти (DMA - Direct Memory Access).
Прямым доступом к памяти называется способ обмена данными, обеспечивающий автономно от процессора установление связи и передачу данных между основной памятью и внешним устройством.
В режиме прямого доступа к памяти используется специализированное устройство - контроллер прямого доступа к памяти, который перед началом обмена программируется с помощью центрального процессора: в него передаются адреса основной памяти и количество передаваемых данных. Затем центральный процессор от контроллера прямого доступа к памяти отключается, разрешив ему работать, и до окончания обмена может выполнять другую работу. Об окончании обмена контроллер прямого доступа к памяти сообщает процессору. В этом случае участие центрального процессора косвенное. Обмен ведет контроллер прямого доступа к памяти.
Прямой доступ к памяти (ПДП):
освобождает процессор от управления операциями ввода-вывода;
позволяет осуществлять параллельно во времени выполнение процессором программы с обменом данными между внешним устройством и основной памятью;
производит обмен данными со скоростью, ограничиваемой только пропускной способностью основной памяти и внешним устройством.
ПДП разгружает процессор от обслуживания операций ввода-вывода, способствует увеличению общей производительности ЭВМ, дает возможность машине более приспособление работать в системах реального времени.
Основной функцией системной шины является передача информации между процессором и остальными устройствами ЭВМ.
Системная шина состоит из трех шин: шины управления, шины данных и адресной шины. По этим шинам циркулируют управляющие сигналы, данные (числа, символы), адреса ячеек памяти и номера устройств ввода-вывода.
Основная задача шин - объединить в единую систему разнообразную номенклатуру модулей, обеспечив их высокопроизводительную надлежащую работу. Под надлежащей работой следует понимать выполнение условий открытости (extensibility), совместимости (compatibility), однотипности (repeatability), гибкости flexibility), надежности (reliability), ремонтопригодности (repairability), эффективности и других, общесистемных требований.
Выполнение данных условий означает:
открытость - возможность расширять, модернизировать одни уровни системы без нарушения других;
совместимость - системы с различным выполнением отдельных подсистем должны быть взаимозаменяемы, совместимость должна выполняться на уровне hardwareи software;
однотипности - модернизация системы не должна приводить к необходимости заменять используемые ранее типы устройств;
гибкость - возможность подключения различных подсистем, устройств без нарушения функционирования существующих систем;
надежность- любая модернизация системы не должна приводить к снижению надежности, т.е. при модернизации следует предусматривать определенную структурную избыточность;
ремонтопригодность - модернизация системы не должна приводить к конструктивным изменениям, усложняющим ее эксплуатацию;
эффективность - выполнение перечисленных выше условий должно быть экономически оправдано.
Суть всех этих требований можно сформулировать так: замена одних шин другими не должна сопровождаться появлением архитектурных ограничений. На практике такое бывает редко. Для ПК одной из существенных неприятностей является необходимость применять другую периферию при использовании других шин расширения.
Шины можно рассматривать как "позвоночник" вычислительной среды. Практически о компьютере, как об эффективной вычислительной системе, можно говорить только при наличии надлежащего согласования между микропроцессором, памятью и коммуникационными магистралями.
Характеристики шин ПК
Системные интерфейсы материнской платы (система шин), которые имеют разъемы (слоты) для подключения адаптеров периферийных устройств (интерфейсных карт), получили название шин расширения.
Системная магистраль является узким местом ЭВМ, так как все устройства, подключенные к ней, конкурируют за возможность передавать свои данные по ее шинам.
Системная магистраль - это среда передачи сигналов управления, адресов, данных, к которой параллельно и одновременно может подключаться несколько компонентов вычислительной системы. Физически системная магистраль представляет собой параллельные проводники на материнской плате, которые называются линиями. Но это еще и алгоритмы, по которым передаются сигналы, правила интерпретации сигналов, дисциплины обслуживания запросов, специальные микросхемы, обеспечивающие эту работу. Весь этот комплекс образует понятие интерфейс системной магистрали или стандарт обмена.
Исторически все интерфейсы СМ ведут свою родословную от стандарта IBM MULTGBUS, для которого фирмой был разработан комплект микросхем (chipset). Этот стандарт мог обслуживать передачу 8- и 16-битовых данных, работать в мультипроцессорном режиме с несколькими ведущими устройствами. Понятие “ведущее/ведомое устройство” могло динамически переопределяться с помощью сигналов управления (например, контроллер ПДП в режиме программирования - ведомое устройство, а в активном режиме -ведущее). Для этого стандарта характерно наличие следующих линий: 20 линий адресов, 16 линий данных, 50 управляющих и служебных линий.
Для IBM PS-2 разработанстандарт Микроканал - МСА (Micro Channel Architecture) в 1987 г. В нем 24-разрядная шина адреса. Шина данных увеличена до 32 бит. Отказались от перемычек и переключателей, определяющих конфигурацию технических средств, и ввели CMOS-память (Complementary Metal Oxyde Semicondactor), позволяющую хранить эту информацию и при отключении питания. Все оборудование, подключаемое к системной магистрали, содержит специальные регистры POS (Programmable Option Select), позволяющие конфигурировать систему программным путем. При тактовой частоте 10 МГц скорость передачи данных составляла 20 Мбайт/с.
Для IBM PC XT был разработан стандарт ISA (Industry Standart Architecture), который имеет две модификации - для XT и для АТ. В ISA XT шина данных - 8 бит, шина адресов - 20 бит, шина управления - 8 линий. В ISA АТ шина данных увеличена до 16 бит. Встречаются и 32-битовые ISA, но это - нестандартизированное расширение. Тактовая частота для работы СМ в стандарте ISA составляет 8 МГц. Производительность ISA XT - 4 Мбайт/с, ISA АТ - от 8 до 16 Мбайт/с.
Стандарт EISA (Extended ISA) - это жестко стандартизованное расширение ISA до 32 бит. Конструктивно совместима с ISA-адаптерами внешних устройств. Предназначена для многозадачных систем, файл-серверов и систем, в которых требуется высокоэффективное расширение ввода-вывода. При тактовой частоте 8.33 МГц скорость передачи данных составляла 33 Мбайт/с.
Стандарт VESA (VESA Lokal Bas или VLB) разработан Ассоциацией стандартов видеоданных (Video Electronics Standart Association) как расширение стандарта ISA для обмена видеоданными с адаптером SVGA. Обмен данными по этому стандарту ведется под управлением микросхем, расположенных на карте, устанавливаемой в специальный слот (разъем) расширения VLB и соединяемой с СМ через стандартный слот расширения. В отличие от стандартных слотов расширения слот VLB связан с микропроцессором напрямую, минуя системную магистраль. Карта VLB, работая совместно с системной магистралью, реализующей стандарт ISA, обеспечивает 32-разрядную передачу данных с тактовой частотой микропроцессора (но не более 40 - 50 МГц). В стандартные слоты материнской платы с интерфейсом VLB устанавливаются карты расширения с интерфейсом ISA. Производительность стандарта VLB достигает 132 Мбайт/с.
Стандарт PCI (Peripheral Component mterconnect) разработан фирмой Intel для ЭВМ с МП Pentium. Это не развитие предыдущих стандартов, а совершенно новая разработка. Системная магистраль в соответствии с этим стандартом работает синхронно с тактом МП и осуществляет связь между локальной шиной МП и интерфейсом ISA, EISA или МСА. Но поскольку для этого интерфейса используются микросхемы, выпускаемые другими фирмами (Satum - для 486, Mercury, Neptune, Triton - для Pentium), скорость работы СМ реально'составляет 30 - 40 Мбайт/с при теоретически возможной 132/ 264 Мбайт/с. Стандарт PCI разрабатывался как процессорно-независимый интерфейс. Помимо Pentium с этим интерфейсом могут работать и МП других фирм (Alpha корпорации DEC, MIPS R4400 и Power PC фирм Motorola, Apple и IBM). Стандарт PCI позволяет реализовать дополнительные функции: автоматическую конфигурацию периферийных устройств (которая позволяет пользователю устанавливать дополнительные платы, не задумываясь над распределением прерываний, каналов ПДП и адресного пространства); работу при пониженном напряжении питания; возможность работы с 64-разрядным интерфейсом. "Слоевая" структура интерфейса PCI снижает электрическую нагрузку на МП и позволяет одновременно управлять шестью периферийными устройствами, подключенными к СМ. Стандарт PCI позволяет использовать "мосты" (Bridges) для организации связи с другими стандартами (например, PCI to ISA Bridge).
Стандарт USB (Universal Serial Bus) - универсальный последовательный интерфейс, обеспечивающий обмен со скоростью 12 Мбайт/с и подключение до 127 устройств.
Стандарт PCMCIA (Personal Computer Memory Card International Association) - интерфейс блокнотных ПЭВМ для подключения расширителей памяти, модемов, контроллеров дисков и стриммеров, сетевых адаптеров и др. Системная магистраль, выполненная по этому стандарту, имеет минимальное энергопотребление, ШД - на 16 линий, ША - на 24 линии.
Системные и локальные шины
Основной обязанностью системной шины является передача информации между
базовым микропроцессором и остальными электронными компонентами компьютера.
По этой шине осуществляется также адресация устройств и происходит обмен
специальными служебными сигналами. Таким образом, упрощенно системную шину
можно представить как совокупность сигнальных линий, объединенных по их
назначению (данные, адреса, управление). Передачей информации по шине
управляет одно из подключенных к ней устройств или специально выделенный
для этого узел, называемый арбитром шины.
Системная шина IBM PC и IBM PC/XT была предназначена Для одновременной
передачи только 8 бит информации, так как используемый в компьютерах
микропроцессор 18088 имел 8 линий данных. Кроме того, системная шина
включала 20 адресных линий, которые ограничивали адресное пространство
пределом в 1 Мбайт. Для работы с внешними устройствами в этой шине были
предусмотрены также 4 линии аппаратных прерываний (IRQ) и 4 линии для
требования внешними устройствами прямого доступа в память (DMA, Direct
Memory Access). Для подключения плат расширения использовались специальные
62-контактные Разъемы. Заметим, что системная шина и микропроцессор
синхронизиоовались от одного тактового генератора с частотой 4,77 МГц.
Таким образом, теоретически скорость передачи данных могла достигать более
4,5 Мбайта/с.
Шина ISA
В компьютерах PC/AT, использующих микропроцессор i80286, впервые стала
применяться новая системная шина ISA (Industry Standard Architecture),
полностью реализующая возможности упомянутого микропроцессора. Она
отличалась наличием дополнительного 36-контактного разъема для
соответствующих плат расширения. За счет этого количество адресных линий
было увеличено на четыре, а данных — на восемь. Теперь можно было
передавать параллельно уже 16 разрядов данных, а благодаря 24 адресным
линиям напрямую обращаться к 16 Мбайтам системной памяти. Количество линий
аппаратных прерываний в этой шине было увеличено с 7 до 15, а каналов DMA —
с 4 до 7. Надо отметить, что новая системная шина ISA полностью включала в
себя возможности старой 8-разрядной шины, то есть все устройства,
используемые в PC/XT, могли без проблем применяться и в PC/AT 286.
Системные платы с шиной ISA уже допускали возможность синхронизации работы
самой шины и микропроцессора разными тактовыми частотами, что позволяло
устройствам, выполненным на платах расширения, работать медленнее, чем
базовый микропроцессор. Это стало особенно актуальным, когда тактовая
частота процессоров превысила 10—12 МГц. Теперь системная шина ISA стала
работать асинхронно с процессором на частоте 8 МГц. Таким образом,
максимальная скорость передачи теоретически может достигать 16 Мбайт/с.
Шина EISA
С появлением новых микропроцессоров, таких, как i80386 и i486, стало
очевидно, что одним из вполне преодолимых препятствий на пути повышения
производительности компьютеров с этими микропроцессорами является системная
шина ISA. Дело в том, что возможности этой шины для построения
высокопроизводительных систем следующего поколения были практически
исчерпаны. Новая системная шина должна была обеспечить наибольший возможный
объем адресуемой памяти, 32-разрядную передачу данных, в том числе и в
режиме DMA, улучшенную систему прерываний и арбитраж DMA, автоматическую
конфигурацию системы и плат расширения. Такой шиной для IBM PC-совместимых
компьютеров стала EISA (Extended Industry Standard Architecture). Заметим,
что системные платы с шиной EISA первоначально были ориентированы на вполне
конкретную область применения новой архитектуры, а именно на компьютеры,
оснащенные высокоскоростными подсистемами внешней памяти на жестких
магнитных дисках с буферной кэш-памятью. Такие компьютеры до сих пор
используются в основном в качестве мощных файл-серверов или рабочих
станций.
В EISA-разъем на системной плате компьютера помимо, разумеется, специальных
EISA-плат может вставляться либо 8-, либо 16-разрядная плата расширения,
предназначенная для обыкновенной PC/AT с шиной ISA. Это обеспечивается
простым, но поистине гениальным конструктивным решением. EISA-разъемы имеют
два ряда контактов, один из которых (верхний) использует сигналы шины ISA,
а второй (нижний) — соответственно EISA. Контакты в соединителях EISA
расположены так, что рядом с каждым сигнальным контактом находится контакт
"Земля". Благодаря этому сводится к минимуму вероятность генерации
электромагнитных помех, а также уменьшается восприимчивость к таким
помехам.
Шина EISA позволяет адресовать 4-Гбайтное адресное пространство, доступное
микропроцессорам 180386/486. Однако доступ к этому пространству могут иметь
не только центральный процессор, но и платы управляющих устройств типа bus
master — главного абонента (то есть устройства, способные управлять
передачей данных по шине), а также устройства, имеющие возможность
организовать режим DMA. Стандарт EISA поддерживает многопроцессорную
архитектуру для "интеллектуальных" устройств (плат), оснащенных
собственными микропроцессорами. Поэтому данные, например, от контроллеров
жестких дисков, графических контроллеров и контроллеров сети могут
обрабатываться независимо, не загружая при этом основной процессор.
Теоретически максимальная скорость передачи по шине
EISA в так называемом пакетном режиме (burst mode) может достигать 33
Мбайт/с. В обычном (стандартном) режиме она не превосходит, разумеется,
известных значений для ISA.
На шине EISA предусматривается метод централизованного Управления,
организованный через специальное устройство — системный арбитр. Таким
образом поддерживается использовало ведущих устройств на шине, однако
возможно также предоставление шины запрашивающим устройствам по
циклическому принципу.
Как и для шины ISA, в системе EISA имеется 7 каналов DMA. выполнение DMA-
функций полностью совместимо с аналогич-
ными операциями на ISA-шине, хотя они могут происходить и несколько
быстрее. Контроллеры DMA имеют возможность поддерживать 8-, 16- и 32-
разрядные режимы передачи данных. В общем случае возможно выполнение одного
из четырех циклов обмена между устройством DMA и памятью системы. Это ISA-
совместимые циклы, использующие для передачи данных 8 тактов шины; циклы
типа А, исполняемые за б тактов шины; циклы типа В, выполняемые за 4 такта
шины, и циклы типа С (или burst DMA), в которых передача данных происходит
за один такт шины. Типы циклов А, В и С поддерживаются 8-, 16- и 32-
разрядными устройствами, причем возможно автоматическое изменение размера
(ширины) данных при передаче в не соответствующую размеру память.
Большинство ISA-совместимых устройств, использующих DMA, могут работать
почти в 2 раза быстрее, если они будут запрограммированы на применение
циклов А или В, а не стандартных (и сравнительно медленных) ISA-циклов.
Такая производительность достигается только путем улучшения арбитража шины,
а не в ущерб совместимости с ISA. Приоритеты DMA в системе могут быть либо
"вращающимися" (переменными), либо жестко установленными. Линии прерывания
шины ISA, по которым запросы прерывания передаются в виде перепадов уровней
напряжения (фронтов сигналов), сильно подвержены импульсным помехам.
Поэтому в дополнение к привычным сигналам прерываний на шине ISA, активным
только по своему фронту, в системе EISA предусмотрены также сигналы
прерываний, активные по уровню. Причем для каждого прерывания выбор той или
иной схемы активности может быть запрограммирован заранее. Собственно
прерывания, активные по фронту, сохранены в EISA только для совместимости
со "старыми" адаптерами ISA, обслуживание запросов на прерывание которых
производит схема, чувствительная к фронту сигнала. Понятно, что прерывания,
активные по уровню, менее подвержены шумам и помехам, нежели обычные. К
тому же (теоретически) по одной и той же физической линии можно передавать
бесконечно большое число уровней прерывания. Таким образом, одна линия
прерывания может использоваться для нескольких запросов.
Для компьютеров с шиной EISA предусмотрено автоматическое конфигурирование
системы. Каждый изготовитель плат расширения для компьютеров с шиной EISA
поставляет вместе этими платами и специальные файлы конфигурации.
Информация из этих файлов используется на этапе подготовки системы
работе, которая заключается в разделении ресурсов компьютера между
отдельными платами. Для "старых" плат адаптеров пользователь должен сам
подобрать правильное положение DIP-перекдючателей (рис. 25) и перемычек,
однако сервисная программа на EISA-компьютерах позволяет отображать
установленные положения соответствующих переключателей на экране монитора и
дает некоторые рекомендации по правильной их установке. Помимо этого в
архитектуре EISA предусматривается выделение определенных групп адресов
ввода-вывода для конкретных слотов шины — каждому разъему расширения
отводится адресный диапазон 4 Кбайта, что также позволяет избежать
конфликтов между отдельными платами EISA.
Заметим, что компьютеры, использующие системные платы с шиной EISA,
достаточно дорогие. К тому же шина по-прежнему тактируется частотой около
8—10 МГц, а скорость передачи увеличивается в основном благодаря увеличению
разрядности шины данных.
Локальные шины
Разработчики компьютеров, системные платы которых основывались на
микропроцессорах 180386/486, стали использовать раздельные шины для памяти
и устройств ввода-вывода, что позволило максимально задействовать
возможности оперативной памяти, так как именно в данном случае память может
работать с наивысшей для нее скоростью. Тем не менее при таком подходе вся
система не может обеспечить достаточной производительности, так как
устройства, подключенные через разъемы расширения, не могут достичь
скорости обмена, сравнимой с процессором. В основном это касается работы с
контроллерами накопителей и видеоадаптерами. Для решения возникшей проблемы
стали использовать так называемые локальные (local) шины, которые
непосредственно связывают процессор с контроллерами периферийных устройств.
Первые IBM PC-совместимые компьютеры с локальными шинами не были,
естественно, стандартизованы. Одним из ведущих изготовителей персональных
компьютеров, впервые реализовав-ишм видеоподсистему с локальной шиной, бьыа
компания NEC Technologies. Еще в 1991 году эта фирма представила свою
оригинальную разработку Image Video.
Шины VL-bus и PCI
В последнее время появились две локальные шины, признанные промышленными:
VL-bus (или VLB), предложенная ассоциацией VESA (Video Electronics
Standards Association), и PCI (Peripheral Component Interconnect),
разработанная фирмой Intel. Обе эти шины предназначены, вообще говоря, для
одного и того же — для увеличения быстродействия компьютера, позволяя таким
периферийным устройствам, как видеоадаптеры и контроллеры накопителей,
работать с тактовой частотой до 33 МГц и выше. Обе шины используют разъемы
типа МСА. На этом, впрочем, их сходство и заканчивается, поскольку
требуемая цель достигается разными средствами.
Если VL-bus является, по сути, расширением шины процессора (вспомним шину
IBM PC/XT), то PCI по своей организации более тяготеет к системным шинам,
например к EISA, и представляет собой абсолютно новую разработку. Строго
говоря, PCI относится к классу так называемых mezzanine-шин, то есть шин-
"пристроек", поскольку между локальной шиной процессора и самой PCI
находится специальная микросхема согласующего "моста" (bridge).
Так как VL-bus продолжает шину процессора без промежуточных буферов, ее
схемная реализация оказывается более дешевой и простой. Первая спецификация
VESA, в частности, предусматривает, что к шине, которая является локальной
32-разрядной шиной системного микропроцессора, может подключаться до трех
периферийных устройств. Некоторые изготовители, впрочем, убеждены, что
добиться устойчивой работы трех устройств на высоких частотах вообще
невозможно, и устанавливают на свои платы только 2 слота. Ограничение на
число устройств связано с тем, что электрическая нагрузочная способность на
сигнальные линии любого процессора весьма невелика.
В качестве устройств, подключаемых к VL-bus, в настоящее время выступают
контроллеры накопителей, видеоадаптеры и сетевые платы. Конструктивно VL-
bus выглядит как короткий соединитель типа МСА (112 контактов),
установленный, например, рядом с разъемами расширения ISA или EISA. При
этом 32 линии используются для передачи данных и 30 — для передачи адреса.
Максимальная скорость передачи по шине VL-bus теоретически может составлять
около 130 Мбайт/с. Стоит отметить, что на VL-bus не предусмотрен арбитр
шины. К счастью, большинство подключаемых к ней устройств являются
"пассивными", то есть сами не инициируют передачу данных. Тем не менее во
избежание возможных конфликтов между подключенными к шине устройствами в
спецификации выделяются "управляющие" (master) и "управляемые" (slave)
адаптеры. Для "управляющих" устройств на системных платах обычно определены
свои "мастерные" слоты. По замыслу разработчиков, подобные "управляющие"
устройства могли осуществлять арбитраж на шине.
После появления процессора Pentium ассоциация VESA приступила к работе над
новым стандартом VL-bus (версия 2). Он предусматривает, в частности,
использование 64-разрядной шины данных и увеличение количества разъемов
расширения (предположительно три разъема на 40 МГц и два на 50 Мгц).
Ожидаемая скорость передачи теоретически должна возрасти до 400 Мбайт/с.
Заметим, что в настоящее время шина VL-bus представляет из себя
сравнительно недорогое дополнение для компьютеров на базе 486-х процессоров
с шиной ISA, причем с обеспечением обратной совместимости.
Спецификация шины PCI обладает несколькими преимуществами перед основной
версией VL-bus. Так, использовать PCI можно вне зависимости от типа
процессора. Специальный контроллер заботится о разделении управляющих
сигналов локальной шины процессора и PCI-шины и, кроме того, осуществляет
арбитраж на PCI. Именно поэтому данная шина может использоваться и в иных
компьютерных платформах. Следует отметить, что гибкость и быстродействие
этой шины предполагают и большие аппаратные затраты, чем для VL-bus. Тем не
менее шина PCI стала практическим стандартом для систем на базе Pentium и
не менее успешно используется в 486-х компьютерах.
В соответствии со спецификацией PCI к шине могут подключаться до 10
устройств. Это, однако, не означает использования такого же числа разъемов
расширения — ограничение относится к общему числу компонентов, в том числе
расположенных на системной плате. Поскольку каждая плата расширения PCI
может разделяться между двумя периферийными устройствами, то уменьшается
общее число устанавливаемых разъемов. В отличие от VL-bus шина PCI работает
на фиксированной тактовой частоте 33 МГц и предусматривает напряжение
питания для контроллеров как 5, так и 3,3 В, а также обеспечивает режим их
автоконфигурации (plug and play — "включай и работай"). Заметим, что,
например, PCI-карты, рассчитанные на напряжение 5 В, могут вставляться
только в соответствующие слоты, которые конструктивно отличаются от слотов
для напряжения 3,3 В. Впрочем,
имеются и так называемые универсальные PCI-адаптеры, кото рые работают в
любом из слотов. Шина PCI может использовать 124-контактный (32-разрядная)
или 188-контактный разъем (64-разрядная иередача данных), при этом
теоретически возможна скорость обмена составляет соответственно 132 и 264
Мбаита/с Спецификация PCI 2.1 в расчете на микропроцессор Pentium (100 МГц)
определяет работу с частотой 33—66 МГц и скоростью обмена до 520 Мбайт/с.
На системных платах устанавливается обычно не более трех-четырех разъемов
PCI.
Отдельно хотелось бы сказать о так называемых разделяемы (shared) слотах
Isa/pci. Поскольку слоты для шины pci распо латаются параллельно разъемам
системной шины, то на систем ной плате из-за ее ограниченного размера
достаточно трудно раз местить требуемое количество тех и других. Именно
поэтому не которые производители и используют разделяемую, или shared
конфигурацию. В этом случае один из слотов PCI располагается настолько
близко к разъему системной шины, что можно исполь зовать только один из
них, то есть подключить либо ISA-, либо PCI-устройство, но, разумеется, в
соответствующий разъем.
Вообще говоря, многие изготовители системных плат часто предусматривают в
своих изделиях разнообразные комбинации системных и локальных шин от ISA
плюс VL-bus для сравнитель но дешевых систем до EISA плюс PCI для систем
высокого ypoв ня. Нередко встречаются сочетания ISA плюс EISA плюс VL-bus
Isa плюс eisa плюс pci и даже все четыре шины одновременно что обеспечивает
определенную гибкость при вы боре адаптеров особенно с учетом высокого
уровня цен к продукцию для шин EISA и PC. Тем не менее "войне" локальных
шин несомненную пoбeду одержала PCI.
Стандарт PCMCIA
Устройства, соответствующие первой версии стандарта PCMCIA, задумывались
как альтернатива относительно тяжелым и энергоемким приводам флоппи-дисков
в портативных компьютерах. Напомним, что "загадочная" аббревиатура PCMCIA
означает не что иное, как Personal Computer Memory Card International
Association. Кстати, принятая этой ассоциацией спецификация была сразу
поддержана такими фирмами, как IBM, AT&T, Intel, NCR и Toshiba. Сегодня
данный стандарт поддерживают уже около 300 производителей. PCMCIA-
устройства размером с обычную кредитную карточку являются альтернативой
обычным платам расширения, подключаемым к системной шине. Сегодня в этом
стандарте выпускаются модули памяти, модемы и факс-модемы, SCSI-адаптеры,
сетевые карты, звуковые карты, винчестеры и т.д. Особой популярностью
пользуются PCMCIA-карты флэш-памяти, которые не теряют информацию при
выключении питания, обладают высоким быстродействием и могут быть
использованы в качестве винчестера без движущихся частей.
Кстати, и для настольных компьютеров разработаны уже адаптеры для PCMCIA-
устройств. Под адаптером PCMCIA понимается плата расширения, которая
вставляется обычно в слот системной шины и соединяется с разъемом PCMCIA
ленточным кабелем. Сам разъем PCMCIA размещается в стандартном отсеке с
форм-фактором 3,5 или 5,25 дюйма.
Первая версия стандарта PCMCIA (release 1.0) была введена в августе 1990
года и поддерживала все типы памяти, исключая динамическую память DRAM.
Таким образом, в спецификацию были включены: статическая память SRAM;
псевдостатическая память PSRAM; постоянная (масочная) память ROM;
однократно программируемая постоянная память PROM (или OTPROM — One-Time
Programmable ROM); стираемая ультрафиолетом перепрограммируемая память UV-
EPROM (Ultraviolet Erasable PROM); электрически стираемая
перепрограммируемая память EEPROM (Electrically Erasable PROM) и флэш-
память (Hash). Работа ассоциации PCMCIA над одноименной спецификацией
проходила в тесном контакте с организацией JEIDA (Japan Electronic Industry
Development Association) в Японии. Поэтому стандарт часто называют
PCMCIA/JEIDA.
Уже в сентябре 1991 года появилась вторая версия спецификации (release
2.0), которая включала в себя новые особенности, такие, как поддержка
устройств ввода-вывода, дополнительный сервис для модулей флэш-памяти.
поддержка модулей с двойным" напряжением питания (5 и 3 В) и так называемый
XIP механизм (eXecute-In-Place). Заметим, что XIP-механизм обес почивает
выполнение программ непосредственно в пространстве PCMCIA-модуля памяти,
экономя тем самым системную память компьютера.
Надо отметить, что вместе с версией 2.0 ассоциация PCMCIA разработала новую
спецификацию SSIS (Socket Services Interface Specification), которая
устанавливает стандартный набор системных вызовов для работы с PCMCIA-
модулями. SSIS выполнена в виде BIOS, что позволяет сохранить независимость
используемых аппаратных средств, но гарантировать при этом программную
совместимость. Первая версия SSIS была принята ассоциацией PCMCIA в августе
1991 года, а через месяц появилась уже слегка модифицированная версия SSIS
— release 1.01. В последней версии SSIS были улучшены некоторые ранее
определенные функции и введена поддержка защищенного режима процессоров.
Более высокий уровень программных операций (так называемый Card Services) с
PCMCIA-модулями бьы предложен только в начале 1992 года.
Новая версия спецификации позволяет называть PCMCIA-модули просто PC
Card(s). Итак, стандарт PCMCIA для связи между PC Card и соответствующим
устройством (адаптером или портом) компьютера определяет 68-контактный
механический соединитель. На нем выделены 16 разрядов под данные и 26
разрядов под адрес, что позволяет непосредственно адресовать 64 Мбайта
памяти. Хотя некоторые выводные контакты предназначены для сигналов,
необходимых при работе с памятью, эти же контакты могут использоваться и
для иных сигналов, рассчитанных на работу с устройствами ввода-вывода.
Разумеется, перед этим происходит так называемая переконфигурация выводов.
Например, контакт для сигнала RDY/BSY (готов/занят), необходимый при работе
с определенными типами памяти, может использоваться для сигнала IREQ
(запрос прерывания).
На стороне модуля PC Card расположен соединитель-розетка (female), а на
стороне компьютера — соединитель-вилка (male). Кроме того, стандарт
определяет три различные длины контактов соединителя-вилки. Такое решение
легко объяснимо. Поскольку подключение и отключение PC Card может
происходить при работающем компьютере (так называемое горячее), то для
того, чтобы на модуль сначала подавалось напряжение питания, а лишь затем
напряжение сигнальных линий, соответствующие контакты выполнены более
длинными. Понятно, что при отключении PCMCIA-модуля все происходит в
обратном порядке. Вторая версия спецификации PCMCIA определяет только три
типа габаритньк размеров для PC Card (Type I, Type II и Type III), к ним
должен быть добавлен и четвертый — Type IV. Два первых типа ограничивают
размеры PC Card до 54 мм (2,12 дюйма) в ширину и 85,6 мм (3,37 дюйма) в
длину. PCMCIA-модули, соответствующие размерам Type I, должны иметь толщину