

8. Интервальные оценки неизвестных параметров(для dx)
Опр. Случайные величины н= н( ) и , являющиеся функциями от выборочных значений, называются соответственно нижним и верхним двусторонними доверительными пределами для неизвестного параметра с надежностью (коэффициентом доверия, доверительной вероятностью) P (0,5<P<1) (или с уровнем значимости ), если для доверительного интервала вероятность . (1) При этом интервал называется двусторонним доверительным интервалом для параметра .
Замечание 2. В соотношение (1) случайными являются и , - число. Замечание 3. Пусть - точечная оценка параметра . Если - доверительный интервал. Тогда - точность интервальной оценки. Предположим, что - выборка из нормального распределения генеральной совокупности с параметрами .
1.Пусть
- известно. Построить интервальную
оценку для
.
![]() - неисправленная выборочная дисперсия.
- неисправленная выборочная дисперсия.
![]() .
.
9.Проверка статистических гипотез.
Предположим, что
x1,…,xn
– выборка из генеральной совокупности
с функцией распределения F(x).
F(x)
может быть полностью неизвестна, тогда
можно поставить следующую гипотезу:
H0:
F(x)=F0(x),
где F0(x)
– конкретная функция распределения.
Если вид функции распределения
![]() известен с точностью до каких-то m
неизвестных параметров. Тогда гипотеза
известен с точностью до каких-то m
неизвестных параметров. Тогда гипотеза
![]() - заданные числа. Пусть x1,…,xn
- берется из нормальной генеральной
совокупности.
- заданные числа. Пусть x1,…,xn
- берется из нормальной генеральной
совокупности.
Допустим
-известно
и оно равно 1, т.е. ГС ~ N(a,1).
Тогда
![]() или
или
![]() .
.
Пусть известно
a=0,
т.е. выборка берется из
![]() .
.
![]() или
или
![]() .
Пусть a
и
.
Пусть a
и
![]() неизвестны:
неизвестны:
![]() или
или
![]() Подчеркнутые
гипотезы называются простыми, поскольку
задают единственную точку в пространстве
параметров. Если гипотеза задает 2 и
большее число точек в пространстве, то
такая гипотеза называется сложной. H0
– основная или нулевая гипотеза. H1
– конкурирующая гипотеза или альтернативна.
Подчеркнутые
гипотезы называются простыми, поскольку
задают единственную точку в пространстве
параметров. Если гипотеза задает 2 и
большее число точек в пространстве, то
такая гипотеза называется сложной. H0
– основная или нулевая гипотеза. H1
– конкурирующая гипотеза или альтернативна.
Пусть X-
выборочное пространство,
т.е. это множество возможных значений
вектора
![]() .
Для построения критерия проверки
гипотезы в выборочном пространстве
выбирается критическая область
.
Для построения критерия проверки
гипотезы в выборочном пространстве
выбирается критическая область
10. Гипотезы сравнения о равенстве мх при неизвестной дисперсии
Предположим, что
x1,x2,…,xn1
и y1,y2,…,yn2
– две независимые выборки из нормальной
генеральной совокупности с параметрами
![]() соответственно.
соответственно.
2.
![]() -неизвестно
H0:
a1=a2.
-неизвестно
H0:
a1=a2.
![]() По
лемме Фишера:
По
лемме Фишера:
![]()
![]() -независимы
и имеют стандартное нормальное
распределение.
-независимы
и имеют стандартное нормальное
распределение.
![]() ;
;
![]() .
.
![]() -отношение
Стьюдента. В качестве статистики возьмем:
-отношение
Стьюдента. В качестве статистики возьмем:
![]()
![]() -
отношение Стьюдента.
-
отношение Стьюдента.
16.Критерий Колмогорова.
Имеется выборка
x1,…,xn
и H0:
F(x)=F0(x).
В качестве меры отклонения теоретической
функции распределения F(x)
берется
![]() .
.
Теорема (Колмогорова).
Если F(x)
непрерывна, то
![]() .
Имеются таблицы процентных точек
распределения Колмогорова.
.
Имеются таблицы процентных точек
распределения Колмогорова.
![]() -
процентная точка распределения
Колмогорова, соответствующая уровню
значимости
-
процентная точка распределения
Колмогорова, соответствующая уровню
значимости
![]() или
или
![]() .
.
Алгоритм:
Считаем
 .
.Если
 ,
то H0
отвергается.
,
то H0
отвергается.
Если
![]() ,
то H0
согласуется с экспериментальными
данными.
,
то H0
согласуется с экспериментальными
данными.
Поэтому вероятность
того, что
![]()
![]() ,
,
![]() .
.
![]() ,
где
,
где
![]() - уровень значимости.
- уровень значимости.
![]()
![]()
![]() - искомый ДИ.
- искомый ДИ.
2. Пусть
- не известно. Построить ДИ для
.
![]() . По Лемме Фишера
. По Лемме Фишера
![]() .
.
![]() ;
;
![]() ,
,
![]() ,
,
![]() .
.
![]() ,
,
![]() .
.
![]() - искомый ДИ.
- искомый ДИ.
![]() таким
образом, что если
таким
образом, что если![]() ,
то нулевая гипотеза H0
отвергается,
т.е. принимается гипотеза H1,
а если
,
то нулевая гипотеза H0
отвергается,
т.е. принимается гипотеза H1,
а если
![]() не
попадает в область K,
т.е.
не
попадает в область K,
т.е.![]() ,
то H0
– принимается. Обычно K
выбирается следующим образом:
D=D(x1,x2,…,xn)
- некоторая функция от выборочных ранных
значений, т.е. случайная величина. Обычно
критическая область K
выбирается одним из следующих 3-х
способов: 1)
,
то H0
– принимается. Обычно K
выбирается следующим образом:
D=D(x1,x2,…,xn)
- некоторая функция от выборочных ранных
значений, т.е. случайная величина. Обычно
критическая область K
выбирается одним из следующих 3-х
способов: 1)
![]() односторонние критические области. 2)
односторонние критические области. 2)
![]() .
3)
.
3)
![]() двусторонняя критическая область
двусторонняя критическая область
О. Случайная величина D=D(x1,x2,…,xn) называется статистикой критерия.
Ошибки:
1) Ошибка 1-го рода
возникает, если H0
– отвергается при условии, что H0
– верна.
-вероятность
ошибки 1-го рода.
![]()
О. Вероятность ошибки 1-го рода называется уровнем значимости критерия.
2) Ошибка 2-го рода
возникает тогда, когда H0
принимается, хотя она неверна (т.е. верна
H1).![]() -вероятность
ошибки 2-го рода.
-вероятность
ошибки 2-го рода.
![]() Одновременно
Одновременно
![]() и
и
![]() невозможно. Если
увеличивать, то
будет
уменьшаться и наоборот.
невозможно. Если
увеличивать, то
будет
уменьшаться и наоборот.
![]() ;
;
![]() .
.
Если
![]() гипотеза H0
отвергается. Если
гипотеза H0
отвергается. Если
![]() гипотеза H0
согласуется с экспериментальными
данными.
гипотеза H0
согласуется с экспериментальными
данными.
![]() ;
;
![]() .
.
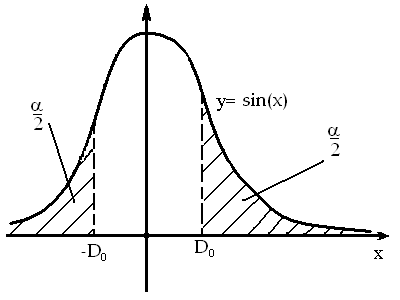
D0-%
точка распределения Стьюдента,
![]() .
.
Теорема1. 1)
Пусть случайные величины
![]() - независимы и имеют нормальное
распределение. Тогда СВ
- независимы и имеют нормальное
распределение. Тогда СВ
![]() также имеет нормальное распределение.
также имеет нормальное распределение.
2) Если случайная
величина X
имеет нормальное распределение, то при
любых действительных А и В (![]() ),
случайная величина Y=AX+B
также имеет нормальное распределение.
Предположим, что
- выборка из генеральной совокупности
с параметрами распределения
.
По теореме
),
случайная величина Y=AX+B
также имеет нормальное распределение.
Предположим, что
- выборка из генеральной совокупности
с параметрами распределения
.
По теореме
![]() имеет нормальное распределение.
имеет нормальное распределение.
Пусть
![]() ,
В=0.
,
В=0.
![]() - также имеет нормальное распределение.
- также имеет нормальное распределение.
![]() ,
т.к.
- несмещенная оценка,
,
т.к.
- несмещенная оценка,
![]() .
~
.
~![]() .
.
Следствие: Если - выборка из нормальной ГС с параметрами , то СВ ~ .
Предположим, что
имеется выборка
из нормальной генеральной совокупности
с параметрами
.
Оценками величины
-
![]()
![]()
Лемма: Если - выборка из нормальной генеральной совокупности с параметрами , то случайная величина
![]() . Лемма
Фишера: Если
- выборка из нормальной генеральной
совокупности с параметрами
,
то случайные величины
и
. Лемма
Фишера: Если
- выборка из нормальной генеральной
совокупности с параметрами
,
то случайные величины
и
![]() - независимы, причем
- независимы, причем
![]() .
.
Следовательно,
получаем искомый ДИ:
![]() ,
,
где
![]() - точность оценки.
- точность оценки.
2. Пусть - неизвестно. Надо построить ДИ для .
~N(0,1).
С другой стороны, по лемме Фишера:
.
Отсюда
![]() .
.
 - отношение Стьюдента с n-1
степенью свободы.
- отношение Стьюдента с n-1
степенью свободы.
![]()
![]() .
Здесь
.
Здесь
![]() ,
где
,
где
![]() - уровень значимости для процентных
точек.
- уровень значимости для процентных
точек.
![]() - искомый ДИ.
- искомый ДИ.
По лемме Фишера
величина
![]() ,
=>
имеет распределение
,
=>
имеет распределение
![]() с
с
![]() степенями свободы, т.к. n-r=
степенями свободы, т.к. n-r=![]() .
Можно показать, что если выполняется
гипотеза Н0,
т.е.
.
Можно показать, что если выполняется
гипотеза Н0,
т.е.
![]() ,
то
и
независимы и
,
то
и
независимы и
![]() ,
=> при выполнении гипотезы Н0
величина
,
=> при выполнении гипотезы Н0
величина
![]() (4)
имеет распределение Фишера с r-1,
n-r
степенями свободы. Величина (4) может
использоваться для проверки гипотезы
о равенстве мат. ожиданий
(4)
имеет распределение Фишера с r-1,
n-r
степенями свободы. Величина (4) может
использоваться для проверки гипотезы
о равенстве мат. ожиданий
![]() .
Если эта гипотеза верна, то
и
явл. состоятельными оценками одной и
той же СВ а и, =>, близки между собой, а
величина
мала. Если
различны, то
и
сближаются с разными мат. ожиданиями:
.
Если эта гипотеза верна, то
и
явл. состоятельными оценками одной и
той же СВ а и, =>, близки между собой, а
величина
мала. Если
различны, то
и
сближаются с разными мат. ожиданиями:
![]() ,
,
![]() и,
=>, сумма
должна принимать большие значения.
Независимо от предложения о рав-ве
,
знаменатель в (4) остается оценкой σ².
Это значит, что при увеличении расхождения
между
величина (4) в среднем должна принимать
большие значения. Статистический
критерий формулируется следующим
образом: если
и,
=>, сумма
должна принимать большие значения.
Независимо от предложения о рав-ве
,
знаменатель в (4) остается оценкой σ².
Это значит, что при увеличении расхождения
между
величина (4) в среднем должна принимать
большие значения. Статистический
критерий формулируется следующим
образом: если
![]() ,
то гипотеза
,
то гипотеза
![]() отвергается. Здесь
отвергается. Здесь
![]() нах-ся
по таблице распределения Фишера с
уровнем значимости α и числами степеней
свободы r-1,
n-r.
нах-ся
по таблице распределения Фишера с
уровнем значимости α и числами степеней
свободы r-1,
n-r.
Обычные, начальные и центральные эмпирические моменты.
Для вычисления
основных хар-к выборки удобно пользоваться
эмпирическими моментами, определения
кот. аналогичны определениям соотв.
теоретических моментов. В отличие от
теоретических, эмпирические моменты
вычисляют по данным наблюдений. Опр.:
Обычным эмпирическим моментом порядка
к наз. среднее
значение к-х степеней разностей
![]() :
:![]() где
где
![]() -
наблюдаемые варианты,
-частоты
вариант, n=
-
наблюдаемые варианты,
-частоты
вариант, n=![]() -объем выборки, С - произвольное постоянное
число( ложный нуль). Опр.:
Начальным
эмпирическим моментом порядка к
наз. обычный момент порядка к при С=0:
-объем выборки, С - произвольное постоянное
число( ложный нуль). Опр.:
Начальным
эмпирическим моментом порядка к
наз. обычный момент порядка к при С=0:
![]() В
частности
В
частности
![]() т.е. начальный эмпирический момент
первого порядка равен выборочной
средней. Опр.:
Центральным
эмпирическим моментом порядка к
наз. обычный момент порядка к при
т.е. начальный эмпирический момент
первого порядка равен выборочной
средней. Опр.:
Центральным
эмпирическим моментом порядка к
наз. обычный момент порядка к при
![]() :
:
![]() ;
;
![]() -
выборочная дисперсия.
-
выборочная дисперсия.
соседними вариантами; практически же третий столбец заполняется так: в клетке строки, содержащей выбранный ложный нуль, пишут 0 ; в клетках над 0 пишут последовательно -1, -2, -3 и т. д., а под 0 – 1,2, 3 … 4) умножают частоты на условные варианты и записывают их произведение
![]() в
4-ый столбец; сложив все полученные
числа, их сумму
в
4-ый столбец; сложив все полученные
числа, их сумму
![]() помещают
в нижнюю клетку столбца; 5) умножают
частоты на квадраты условных вариант
и записывают их произведение
помещают
в нижнюю клетку столбца; 5) умножают
частоты на квадраты условных вариант
и записывают их произведение
![]() в
5-ый столбец; сложив все полученные
числа, их суму
в
5-ый столбец; сложив все полученные
числа, их суму
![]() помещают в нижнюю клетку столбца; 6)
умножают частоты на квадраты условных
вариант, увеличенных на единицу, и
записывают произведения
помещают в нижнюю клетку столбца; 6)
умножают частоты на квадраты условных
вариант, увеличенных на единицу, и
записывают произведения
![]() в
6-ой контрольный столбец; сложив все
полученные числа, их сумму
в
6-ой контрольный столбец; сложив все
полученные числа, их сумму
![]() помещают
в нижнюю клетку столбца. Замечание1.
Целесообразно
отдельно складывать отрицат. числа 4-го
столбца (их суму
помещают
в нижнюю клетку столбца. Замечание1.
Целесообразно
отдельно складывать отрицат. числа 4-го
столбца (их суму
![]() записывают
в клетку строки, содержащей ложный нуль)
и отдельно положит. числа ( их сумму
записывают
в клетку строки, содержащей ложный нуль)
и отдельно положит. числа ( их сумму
![]() записывают
в предпоследнюю клетку столбца); тогда
записывают
в предпоследнюю клетку столбца); тогда
![]() Замечание2.
При вычислении произведений
5-го
столбца целесообразно числа
4-го
столбца умножить на 3-го столбца.
Замечание3.6-ой
столбец служит для контроля вычислений:
если сумма
=
Замечание2.
При вычислении произведений
5-го
столбца целесообразно числа
4-го
столбца умножить на 3-го столбца.
Замечание3.6-ой
столбец служит для контроля вычислений:
если сумма
=![]() ,
то вычисления проведены правильно.
После заполнения таблицы и проверки
правильности вычислений, вычисляются
условные моменты:
,
то вычисления проведены правильно.
После заполнения таблицы и проверки
правильности вычислений, вычисляются
условные моменты:
![]()
![]() И
вычисляют выборочные среднюю и дисперсию
по формулам:
И
вычисляют выборочные среднюю и дисперсию
по формулам:
![]()
![]() .
.
выборочный
коэффициент корреляции. Можно значительно
упростить расчет, если перейти к условным
вариантам (при этом
![]() не
изменяется)
не
изменяется)
![]() ;
;
![]() .
В этом случае выборочный коэффициент
корреляции вычисляют по формуле:
.
В этом случае выборочный коэффициент
корреляции вычисляют по формуле:
![]() Величины
Величины
![]() можно найти методом произведений.
Остается вычислить
можно найти методом произведений.
Остается вычислить
![]() ,
где
,
где
![]() -
частота пары условных вариант (u,
-
частота пары условных вариант (u,![]() ).
Справедливы формулы
).
Справедливы формулы
![]()
![]()