

7. Дані. Шкалування даних.
Да́нные— это представление фактов и идей в формализованном виде, пригодном для передачи и обработки в некотором информационном процессе. Шкалирование — метод присвоения числовых значений отдельным атрибутам некоторой системы. Шкалирование позволяет разбить описание сложного процесса на описание параметров по отдельным шкалам
8. Інтелектуальний аналіз даних. Основні стадії.
ИАД (Data Mining) - это процесс поддержки принятия решений, основанный на поиске в данных скрытых закономерностей (шаблонов информации). При этом накопленные сведения автоматически обобщаются до информации, которая может быть охарактеризована как знания. В общем случае процесс ИАД состоит из трёх стадий: 1) выявление закономерностей (свободный поиск); 2) использование выявленных закономерностей для предсказания неизвестных значений (прогностическое моделирование); 3) анализ исключений, предназначенный для выявления и толкования аномалий в найденных закономерностях.
Иногда в явном виде выделяют промежуточную стадию проверки достоверности найденных закономерностей между их нахождением и использованием (стадия валидации).

9. Задачі інтелектуального аналізу даних.
Задачи, решаемые методами Data Mining, принято разделять на описательные (англ. descriptive) и предсказательные (англ. predictive). В описательных задачах самое главное — это дать наглядное описание имеющихся скрытых закономерностей, в то время как в предсказательных задачах на первом плане стоит вопрос о предсказании для тех случаев, для которых данных ещё нет. К описательным задачам относятся:
• поиск ассоциативных правил или паттернов (образцов);
• группировка объектов, кластерный анализ;
• построение регрессионной модели.
К предсказательным задачам относятся:
• классификация объектов (для заранее заданных классов);
• регрессионный анализ, анализ временны́х рядов.
ИАД решает следующие задачи:
- Выявление паттернов, поиск скрытых закономерностей на основе анализа архивных данных и классификаторов.
- Повышение качества архивной информации - выявление закономерностей (в виде правил вывода) в архивных данных для использования в моделях прогнозирования, системах поддержки принятия решений и т.д.
- Верификация данных - система выявления ошибок в оперативно поступающих данных. Например, с помощью нейронных сетей и индуктивного вывода правил строятся приблизительные прогнозы, которые сравниваются с поступающими данными. Большие отклонения рассматриваются как возможные ошибки.
10.Задача класифікації, як задача інтелектуального аналізу даних.
Задача классифика́ции — формализованная задача, в которой имеется множество объектов (ситуаций), разделённых некоторым образом на классы. Задано конечное множество объектов, для которых известно, к каким классам они относятся. Это множество называется выборкой. Классовая принадлежность остальных объектов не известна. Требуется построить алгоритм, способный классифицировать произвольный объект из исходного множества. Классифици́ровать объект — значит, указать номер (или наименование) класса, к которому относится данный объект.
Классифика́ция
объекта — номер или наименование
класса, выдаваемый алгоритмом
классификации в результате его применения
к данному конкретному объекту. В
математической статистике задачи
классификации называются также задачами
дискриминантного анализа. В машинном
обучении задача классификации решается,
как правило, с помощью методов
искусственных нейронных сетей при
постановке эксперимента в виде обучения
с учителем. Существуют также другие
способы постановки эксперимента —
обучение без учителя, но они используются
для решения другой задачи — кластеризации
или таксономии. В этих задачах разделение
объектов обучающей выборки на классы
не задаётся, и требуется классифицировать
объекты только на основе их сходства
друг с другом. В некоторых прикладных
областях, и даже в самой математической
статистике, из-за близости задач часто
не различают задачи кластеризации от
задач классификации. Некоторые алгоритмы
для решения задач классификации
комбинируют обучение с учителем с
обучением без учителя, например, одна
из версий нейронных сетей Кохонена —
cети векторного квантования, обучаемые
с учителем. Пусть X
— множество описаний объектов, Y
— множество номеров (или наименований)
классов. Существует неизвестная целевая
зависимость — отображение
 ,
значения которой известны только на
объектах конечной обучающей выборки
,
значения которой известны только на
объектах конечной обучающей выборки
 .
Требуется построить алгоритм
.
Требуется построить алгоритм
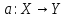 , способный классифицировать произвольный
объект
, способный классифицировать произвольный
объект
 .
.