

2. Информационное моделирование экономических процессов
Наибольшие трудности в обработке информации на компьютере встречаются на начальном этапе, предназначенном для приведения неформального описания экономических процессов (бизнес-процессов) к формальному. Нужная степень формализации достигается путем последовательной смены одного описания другим. Первое описание, как правило, выполняется в виде информационной модели, видов которых существует достаточно много, а последнее - на языке программирования. Информационные модели отражают информационные потоки между различными объектами, отношения между ними, содержат идентификаторы объектов, объемные, временные, частотные и другие характеристики, как самих объектов, так и входящих и исходящих потоков данных, а также последовательность выполнения расчетов.
Цель информационного моделирования состоит в отражении в наглядной форме процесса формирования и движения управленческих документов (входных и результирующих), потоков внешней и внутренней информации на машинных носителях. Частным случаем информационных моделей являются модели баз данных – реляционные, сетевые, иерархические и т.д., и модели баз знаний – деревья вывода, семантические сети, деревья целей, фреймы и т.д.
Остановимся на двух типах информационных моделей, получивших наибольшее распространение в практике управления экономическими объектами:
-
диаграммы потоков данных (ДПД);
-
графовые модели.
Графовые модели, как правило, дополняют ДПД, но в ряде случаев могут выступать и в качестве самостоятельного средства моделирования.
Диаграммы потоков данных (DFD – Data Flow Diagrams) создаются для адекватного отражения информационных потоков, составляющих содержание экономических процессов (бизнес-процессов). Для их построения используется всего четыре элемента: объекты, потоки данных, процессы и накопители данных.
Объекты – это источники и преемники данных (информационных сообщений: заказчики, поставщики, персонал, склад, цех, бухгалтерия и т.д.). Обозначаются они в виде квадрата или прямоугольника, левая сторона которого имеет утолщение (см. рис. 7.2). Прямоугольники, обозначающие одинаковые объекты, имеют перечеркнутый правый нижний угол.
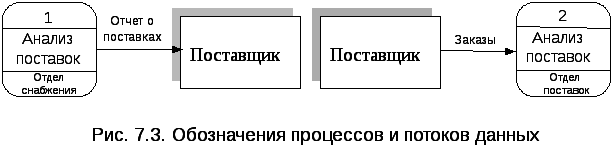
Поток данных изображается стрелкой (горизонтальной или вертикальной). Направление стрелки указывает направление потока. Если поток идет в двух направлениях, то используется двойная стрелка. Поток данных всегда должен быть идентифицирован, т.е. иметь надпись, отражающую его содержание.
Процессы воспроизводятся в виде прямоугольника с закругленными углами, в котором указываются: идентификатор процесса, его имя и место реализации. В нижнем секторе указывается исполнитель данного процесса.
На рис. 7.3 приведены примеры наименований потоков данных и процессов.
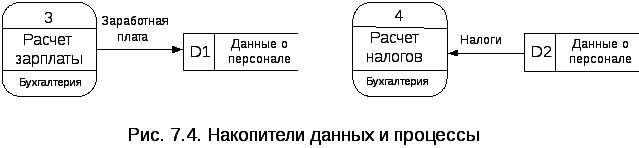
Накопители данных – это центры возникновения и хранения данных, каждый из которых идентифицируется буквой D. Если процесс сохраняет данные, то стрелка потока данных направлена от процесса к накопителю, а если считывает данные, то из накопителя к процессу (см. рис. 7.4).
Реальные экономические процессы сложны и поэтому их воспроизведение осуществляется поэтапно. Вначале создают общие диаграммы, называемые контекстными, которые затем детализируются. Для примера приведем общую диаграмму потоков данных, отражающую деятельность посреднической фирмы. Цель фирмы заключается в обработке заказов и передаче их производителю, если в наличии нет заказываемой готовой продукции. Диаграмма потоков данных, приведенная на рис. 7.5, дает общую информацию о деятельности фирмы.

На приведенной общей диаграмме показаны два накопителя данных (в данном случае справочников): первый (D1) – необходим для выяснения того, что имеется ли на складе готовой продукции заказываемая продукция, а второй (D2) – для определения финансового состояния заказчика (его платежеспособность).
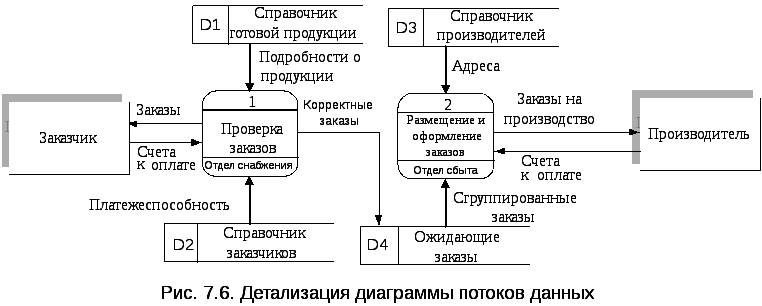
Процесс “Обработка заказов” достаточно общий для того, чтобы его можно было алгоритмизировать, поэтому требуется детализация, то есть деление на два „Проверка заказов” и ”Размещение и содержание заказов”. В результате на рис. 7.6 появится новый процесс и два новых накопителя данных: D3 - справочник производителей и D4 – ожидаемые заказы. Первый необходим для поиска нужного производителя, а второй – для временного содержания проверенных заказов, до тех пор, пока не будет выполнено соответствующее размещение заказа, т.е. найден соответствующий производитель и не собрана для него соответствующая группа заказов. Каждый из процессов, в случае необходимости, может детализироваться далее.
Накопители данных в ДПД используются как места хранения данных при переходе от одной транзакции к другой (сведения о заказчиках, поставщиках, новых поступлениях продукции и т.д.). В результате изучения содержания входных и исходящих информационных потоков на уровне документов и экономических показателей можно установить:
-состав накопителей и содержание их элементов;
-структуру накопителей и основные операции по обработке данных.
Накопители данных в ДПД приобретают различные формы. Если организована оперативная обработка данных (OLTP-технология), то такой формой служит база данных, если аналитическая (OLAP-технология), то хранилища данных.
Процессы, отраженные ДПД в виде закругленных прямоугольников, рано или поздно на некотором уровне детализации, должны содержать формулы для расчета экономических показателей. Если таковых много, и, при этом, расчет с помощью одних показателей требует предварительного расчета других, то для правильной ориентации в последовательности расчетов можно использовать ориентированные графы.
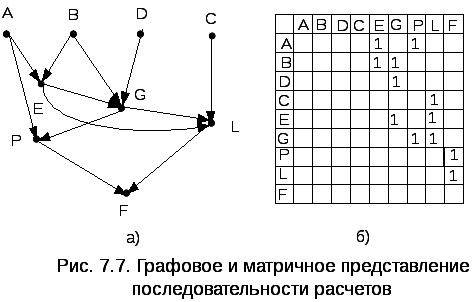
Под графом понимается множество точек, над которыми заданы отношения. Отношения могут задаваться графически с помощью связывающих точки линий или матриц смежности. Точки называют узлами или вершинами, а линии – дугами. Дуги могут быть ориентированными, или нет. В информационных графовых моделях, как правило, используются ориентированные дуги (стрелки), отражающие либо направление расчетов, либо направление движения информационного потока, либо исходную и результирующую информацию. На рис. 7.7а представлен граф, предназначенный для указания последовательности расчетов. Формулы расчетов следующие:
![]() ,
,
![]() ;
;
![]() ;
;
![]() ;
;
![]() ;
;
На рис. 7.7б представлена матрица смежности графа.
Матрица
смежности строится следующим образом:
элемент (i,j),
стоящий на пересечении i-й
строки и j-го
столбца, равен единице, если из вершины
![]() в вершину
в вершину
![]() идет дуга, и равен нулю в противном
случае. Матрица смежности с помощью
несложных манипуляций позволяет
проверить следующее: все ли исходные
данные задействованы, для всех ли
расчетов имеются исходные данные и т.д.
идет дуга, и равен нулю в противном
случае. Матрица смежности с помощью
несложных манипуляций позволяет
проверить следующее: все ли исходные
данные задействованы, для всех ли
расчетов имеются исходные данные и т.д.
Дуги могут нести также и дополнительную нагрузку. Если на них указать число, то тем самым можно количественно характеризовать связь. Например, количество документов, передаваемых в период, количество объектов, перемещающихся в пространстве и т. д.
Одним из вариантов информационной модели, наглядно отображающей взаимосвязь между входной и результирующей информацией, служит схема, приведенная на рис. 7.8.
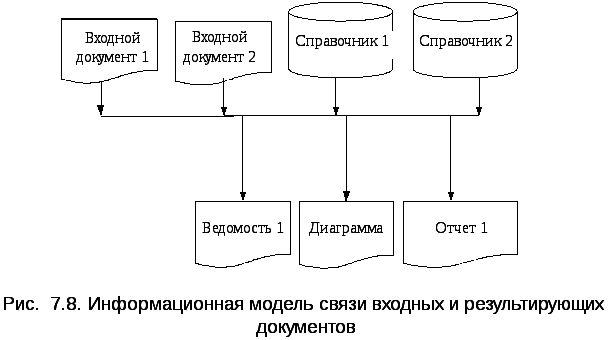
В верхней части модели находятся входные документы, а в нижней – результирующие. Стрелки указывают направление информационных потоков.