

Задачи обобщения
Так же как и в случае экспериментов по различению, что математически может быть сформулированно каккластеризация, при обобщении понятий можно исследовать спонтанное обобщение, при котором критерии подобия не вводятся извне или не навязываются экспериментатором.
При этом в эксперименте по «чистому обобщению» от модели мозгаилиперцептронатребуется перейти от избирательной реакции на один стимул (допустим, квадрат, находящийся в левой части сетчатки) к подобному ему стимулу, который не активизирует ни одного из тех же сенсорных окончаний (квадрат в правой части сетчатки).К обобщению более слабого вида относится, например, требование, чтобы реакции системы распространялись на элементы класса подобных стимулов, которые не обязательно отделены от уже показанного ранее (или услышанного, или воспринятого на ощупь) стимула.
Задачи поиска правил ассоциации
Исходная информация представляется в виде признаковых описаний. Задача состоит в том, чтобы найти такие наборы признаков, и такие значения этих признаков, которые особенно часто (неслучайно часто) встречаются в признаковых описаниях объектов.
Задачи сокращения размерности
Исходная информация представляется в виде признаковых описаний, причём число признаков может быть достаточно большим. Задача состоит в том, чтобы представить эти данные в пространстве меньшей размерности, по возможности, минимизировав потери информации.
Методы решения
Метод главных компонент
Метод независимых компонент
Многомерное шкалирование
Задачи визуализации данных
Некоторые методы кластеризации и снижения размерности строят представления выборки в пространстве размерности два. Это позволяет отображать многомерные данные в виде плоских графиков и анализировать их визуально, что способствует лучшему пониманию данныхи самой сути решаемой задачи.
Методы решения
Дендрограмма
Самоорганизующаяся карта Кохонена
Generative topographic map
Карта сходства
Какие существуют алгоритмы поиска ассоциативных правил?
Алгоритм AIS. Первый алгоритм поиска ассоциативных правил, называвшийся AIS , (предложенный Agrawal, Imielinski and Swami) был разработан сотрудниками исследовательского центра IBM Almaden в 1993 году. С этой работы начался интерес к ассоциативным правилам ; на середину 90-х годов прошлого века пришелся пик исследовательских работ в этой области, и с тех пор каждый год появляется несколько новых алгоритмов.В алгоритме AIS кандидаты множества наборов генерируются и подсчитываются "на лету", во время сканирования базы данных.
Алгоритм SETM. Создание этого алгоритма было мотивировано желанием использовать язык SQL для вычисления часто встречающихся наборов товаров. Как и алгоритм AIS, SETM также формирует кандидатов "на лету", основываясь на преобразованиях базы данных. Чтобы использовать стандартную операцию объединения языка SQL для формирования кандидата, SETM отделяет формирование кандидата от их подсчета.
Неудобство алгоритмов AIS и SETM - излишнее генерирование и подсчет слишком многих кандидатов, которые в результате не оказываются часто встречающимися. Для улучшения их работы был предложен алгоритм Apriori.
Работа данного алгоритма состоит из нескольких этапов, каждый из этапов состоит из следующих шагов:
формирование кандидатов;
подсчет кандидатов.
Формирование кандидатов (candidate generation) - этап, на котором алгоритм, сканируя базу данных, создает множество i-элементных кандидатов (i - номер этапа). На этом этапе поддержка кандидатов не рассчитывается.
Подсчет кандидатов (candidate counting) - этап, на котором вычисляется поддержка каждого i-элементного кандидата. Здесь же осуществляется отсечение кандидатов, поддержка которых меньше минимума, установленного пользователем (min_sup). Оставшиеся i-элементные наборы называем часто встречающимися.
Какие существуют алгоритмы сиквенциального анализа?
В чем идея алгоритма KMeans?
Метод k-средних (англ. k-means) — наиболее популярный метод кластеризации. Был изобретён в 1950-х годах математикомГуго Штейнгаузоми почти одновременно Стюартом Ллойдом.Особую популярность приобрёл после работы Маккуина.
Действие алгоритма таково, что он стремится минимизировать суммарное квадратичное отклонение точек кластеров от центров этих кластеров:
V
= ∑ i = 1 k ∑ x j ∈
S i ( x j − μ i ) 2 {\displaystyle V=\sum _{i=1}^{k}\sum
_{x_{j}\in S_{i}}(x_{j}-\mu _{i})^{2}}
где
k {\displaystyle k}
— число кластеров, S i
{\displaystyle S_{i}}
— полученные кластеры, i =
1 , 2 , … , k {\displaystyle i=1,2,\dots ,k}
и μ i {\displaystyle \mu _{i}}
— центры масс векторов x j∈
S i {\displaystyle x_{j}\in S_{i}}
.
По аналогии с методом главных компонентцентры кластеров называются также главными точками, а сам метод называется методом главных точек и включается в общую теорию главных объектов, обеспечивающих наилучшуюаппроксимациюданных.
Алгоритм представляет собой версию EM-алгоритма, применяемого также для разделения смесигауссиан. Он разбиваетмножествоэлементоввекторного пространствана заранее известное число кластеров k.
Основная идея заключается в том, что на каждой итерации перевычисляется центр массдля каждого кластера, полученного на предыдущем шаге, затем векторы разбиваются на кластеры вновь в соответствии с тем, какой из новых центров оказался ближе по выбранной метрике.
Алгоритм завершается, когда на какой-то итерации не происходит изменения внутрикластерного расстояния. Это происходит за конечное число итераций, так как количество возможных разбиений конечного множества конечно, а на каждом шаге суммарное квадратичное отклонение V уменьшается, поэтому зацикливание невозможно.
Какие существуют дивизимные алгоритмы и чем они отличаются друг от друга?
Дивизимные кластерные алгоритмы, в отличие от агломеративных, на первом шаге представляют все множество элементов I как единственный кластер. На каждом шаге алгоритма один из существующих кластеров рекурсивно делится на два дочерних. Таким образом, итерационно образуются кластеры сверху вниз. Этот подход не так подробно описывается в литературе по кластерному анализу, как агломеративные алгоритмы. Его применяют, когда необходимо разделить все множество объектов I на относительно небольшое количество кластеров. Один из первых дивизимных алгоритмов был предложен Смитом Макнаотоном в 1965 году.
На первом шаге все элементы помещаются в один кластер Сi = I
Затем выбирается элемент, у которого среднее значение расстояния от других элементов в этом кластере наибольшее. Среднее значение может быть вычислено, например, с помощью формулы
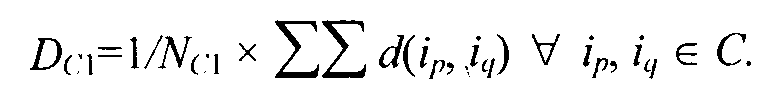
Выбранный элемент удаляется из кластера С1 и формирует первый член второго кластера С2.
На каждом последующем шаге элемент в кластере С1, для которого разница между средним расстоянием до элементов, находящихся в С2, и средним расстоянием до элементов, остающихся в С1, наибольшая, переносится в С2.
Переносы элементов из С1 в С2 продолжаются до тех пор, пока соответствующие разницы средних не станут отрицательными, т.е. пока существуют элементы, расположенные к элементам кластера С2 ближе чем к элементам кластера С1
В результате один кластер делится на два дочерних, один из которых расщепляется на следующем уровне иерархии. Каждый последующий уровень применяет процедуру разделения к одному из кластеров, полученных на предыдущем уровне. Выбор расщепляемого кластера может выполняться по-разному.
В 1990 г. Кауфман и Роузеув предложили выбирать на каждом уровне кластер для расщепления с наибольшим диаметром, который вычисляется по формуле
![]()
Рекурсивное разделение кластеров продолжается, пока все кластеры или не станут сиглетонами (т. е. состоящими из одного объекта), или пока все члены одного кластера не будут иметь нулевое отличие друг от друга.
Какие существуют аггломеративные алгоритмы и чем они отличаются друг от друга.
Иерархическая кластеризация (также графовые алгоритмы кластеризации) — совокупность алгоритмов упорядочивания данных, визуализация которых обеспечивается с помощью графов.
Алгоритмы упорядочивания данных указанного типа исходят из того, что некое множество объектов характеризуется определённой степенью связности. Предполагается наличие вложенных групп (кластеров различного порядка). Алгоритмы, в свою очередь, подразделяются на агломеративные (объединительные) и дивизивные (разделяющие). По количеству признаков иногда выделяют монотетические и политетические методы классификации. Как и большинство визуальных способов представления зависимостей графы быстро теряют наглядность при увеличении числа объектов. Существует ряд специализированных программ для построения графов.
Под дендрограммой обычно понимается дерево, то есть граф без циклов, построенный по матрице мер близости. Дендрограмма позволяет изобразить взаимные связи между объектами из заданного множества[1]. Для создания дендрограммы требуетсяматрица сходства(илиразличия), которая определяет уровень сходства между парами объектов. Чаще используются агломеративные методы.
Далее необходимо выбрать метод построения дендрограммы, который определяет способ пересчёта матрицы сходства (различия) после объединения (или разделения) очередных двух объектов в кластер.
В работах по кластерному анализу описан довольно внушительный ряд способов построения (англ.sorting strategies) дендрограмм:
Метод одиночной связи (англ.single linkage). Также известен, как «метод ближайшего соседа».
Метод полной связи(англ.complete linkage). Также известен, как «метод дальнего соседа».
Метод средней связи (англ. pair-group method using arithmetic averages).
Невзвешенный (англ.unweighted).
Взвешенный (англ.weighted).
Центроидный метод (англ. pair-group method using the centroid average).
Невзвешенный.
Взвешенный (медианный).
Метод Уорда (англ.Ward’s method).