

6.6. Способы распараллеливания
Различают два основных способа распараллеливания: по управлению и по информации.
Первый способ — представление алгоритма задачи в виде частично-упорядоченной последовательности выполняемых работ. Затем в результате диспетчирования реализуется оптимальный план выполнения работ в ВС при ограничениях на время выполнения всего алгоритма или за минимальное время.
Основой является представление алгоритма граф-схемой G, отражающей информационные связи между работами (задачами, процессами, процедурами, операторами, макрокомандами и т.д.), на которые разбит алгоритм. Граф G — взвешенный, ориентированный, без контуров.
Для исследования графа и диспетчирования используют матрицы следования S; их дополняют столбцом T весов — получают расширенные матрицы следования S* (рис. 6.12).
|
|
1 |
2 |
3 |
4 |
5 |
6 |
T |
|
1 |
|
|
|
|
|
|
2 |
|
2 |
|
|
|
|
|
|
1 |
|
3 |
|
|
|
|
|
|
2 |
|
4 |
|
|
|
|
|
|
3 |
|
5 |
|
|
|
|
|
|
2 |
|
6 |
1 |
|
1 |
|
|
|
2 |


Рис. 6.12. Исходная информация для распараллеливания
Здесь предполагаем, что ВС — однородная, с общей (разделяемой) памятью, т.е. потерями времени на обмен между работами можно пренебречь.
Пусть ВС содержит два процессора (n = 2). Тогда в результате оптимального распределения получим план (рис. 6.13).

Рис.6.13. Временная диаграмма параллельного выполнения работ
План
действительно совпадает с оптимальным,
т.к. длина расписания T = 7, что совпадает
с длиной критического пути в графе, Tкр
= 7 (путь 1
![]() 3
3![]() 4).
4).
В общей схеме организации параллельного вычислительного процесса мы не полностью раскрыли содержание блока 3 — интерпретации потока макроинструкций в виде, удобном для работы диспетчера. Сейчас мы определили, что такой вид — это матрица следования. Значит, в случае необходимости автоматического формирования матрицы следования надо определять информационную взаимосвязь макроинструкций в пределах видимости, т. е. в «окне просмотра». Таким образом, по текущему содержимому «окна просмотра» надо формировать текущий вид матрицы следования.
Вспомним, что мы уже в упрощенном виде решали подобную задачу, например, когда по формируемому потоку трехадресных команд определяли их информационную взаимосвязь и определяли возможность одновременного выполнения этих команд.
Обобщим эту задачу.
Возвращаясь
к названной схеме, представим себе, что
поток макроинструкций (блок 2) следует
через «окно просмотра» так, что для
планирования оптимальной загрузки
процессоров диспетчер может анализировать
некоторое множество этих макроинструкций
и из них выбирать вариант назначения
их на процессоры для выполнения. Каждая
макроинструкция может интерпретироваться
и как процедура, где можно выделить имя
θμ
множество {![]() μ}
входных параметров, множество {βμ}
выходных параметров. На рис. 6.14
отображено «окно просмотра», через
которое следует поток макроинструкций.
μ}
входных параметров, множество {βμ}
выходных параметров. На рис. 6.14
отображено «окно просмотра», через
которое следует поток макроинструкций.

«окно
просмотра»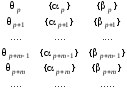
Рис. 6.14. Обработка «окна просмотра»
Составим по его содержимому соответствующую матрицу следования размерности m × m:


По матрице следования S диспетчер производит назначение.
После выполнения макроинструкций они исключаются из "окна прросмотра", оставшиеся макроинструкции уплотняются вверх, а снизу "окно просмотра" пополняется новыми макроинструкциями. С учетом вновь поступившихмакроинструкций уточняется текущий вид матрицы следования S и процесс диспетчирования продолжается.
По такой же схеме, а именно, на основе первого способа распараллеливания — по управлению — решается другая важная задача распараллеливания: компоновки длинных командных слов в оптимизирующем трансляторе. Назначение работы на ИУ осуществляется здесь в виде записи соответствующей инструкции в позицию длинного командного слова, соответствующую ИУ. т.е. план параллельного выполнения работ (команд, операций) фиксируется в длинных командных словах, в которых предусмотрены инструкции каждому ИУ, которые они должны начать выполнять с данного такта.
Второй способ распараллеливания — по информации — используется тогда, когда можно распределить обрабатываемую информацию между процессорами для обработки по идентичным алгоритмам (по одному алгоритму)