

1. Линейные
![]()
![]() весовой
вектор,
весовой
вектор,
Простейшее решение в случаях двух классов выглядит так:
![]()
![]()
![]()
![]()
Многоклассовая задача. Пусть есть Mклассов. Строим
 - попарные разделяющие функции.
- попарные разделяющие функции.
К
Попарное разделение





![]()
![]()



![]()
![]() Для Рис2.1 имеем:
Для Рис2.1 имеем:
1:
![]() 2 :
2 :
![]() 3:
3:
![]() Рис 2.1
Рис 2.1
Оптимальное решение: функции типа “один от всех”
![]()

Такое разделение сделать гораздо проще,
Хотя не всегда можно, так как появляются
области неопределенности.
Например, область O вообще никуда не
относится. Это область неопределенности. d3;1,2
2. Нелинейные решающие функции
Введем понятие обобщенной линейная
решающей функция
![]() .
.
Пусть размерность пространства равна n, тогда можно построить:
![]() ,
,
kможет быть любым:![]() ,
но обычно берут
,
но обычно берут![]()
![]() -
некоторые функции: это полный набор
ортогональных функций (сложно)
-
некоторые функции: это полный набор
ортогональных функций (сложно)![]() часто сводят к параметрической задаче:
часто сводят к параметрической задаче:
![]() , то есть
, то есть
![]() - это нелинейная функция
- это нелинейная функция
 =
= ,n=k
,n=k
![]() - обобщенная линейная функция.
- обобщенная линейная функция.
Возьмем
![]() - это обобщенная квадратичная форма;
- это обобщенная квадратичная форма;
A– Некоторая симметрическая матрица.
![]() можно
разложить по компонентам, тогда:
можно
разложить по компонентам, тогда:
![]() .
.
Можно
![]() как новую переменную
как новую переменную
В пространстве с координатами
![]() решающая функция будет линейной
функцией.
решающая функция будет линейной
функцией.

Рис. 2.3
На рис 2.3 показаны классы, которые в исходном пространстве не делятся линейными решающими функциями, но можно сделать линейное разделение обобщенными линейными функциями, в пространстве с координатами , определяемыми коэффициентами квадратичной формы.
Таким образом, если в исходном n-мерном пространстве построить линейные решающие функции нельзя, то при переходе в пространство размерностиk>nвероятность построения линейных решающих функций увеличивается.
2.2. Статистические методы классификации
Исходные позиции: наши данные могут быть описаны с помощью вероятностных методов.
Существует 2 подхода:
априорно знаем статистические распределения данных.
априорно не знаем статистические распределения, а известны таблицы данных и выборки из этих статистических распределений.
2.2.1. Постановка задачи классификации как статистической задачи при известных вероятностных распределениях.
Пусть имеется генеральная совокупность
![]() ,
соответствующая 1-ому и 2-ому классу.
,
соответствующая 1-ому и 2-ому классу.
![]()
Вероятностные распределения заданы априорно.
Пусть
![]() (может быть такое)
(может быть такое)
Наша задача – разбиение исходного
пространства Xна области![]() так:
так:
![]()
м
![]()
 ы
требуем, чтобы
ы
требуем, чтобы![]() ,
,![]()

![]()
![]()
![]()




![]()
![]()
Цель: разбить
![]() на области так, чтобы:
на области так, чтобы:
![]()
Нам надо задать следующее:
Условные по классам функции распределения
![]()
![]()
2.
![]() -априорная
вероятность появления объекта из
соответствующего класса
-априорная
вероятность появления объекта из
соответствующего класса
![]()
Критерии качества, связанные с ошибками и стоимостями ошибок.
Генеральная совокупность
-
решения



0
C(1/2)

С(2/1)
0
Стоимости принятия решений:
![]() отнесем
к
отнесем
к![]() ,
,
тогда стоимость С(2/1)
![]() отнесем
к
отнесем
к![]() ;C(1/2)
;C(1/2)
C(1/1)=C(2/2)=0 - правильное решение;
На рис 2.4 показаны условные плотности распределения по классам и граница решения .

![]()
![]()

X


Рис. 2.4.
Вероятность принятия неправильного решения определяются таким образом:

Таким образом заданы:
![]() генеральные
совокупности;
генеральные
совокупности;
Условные плотности и априорные вероятности.

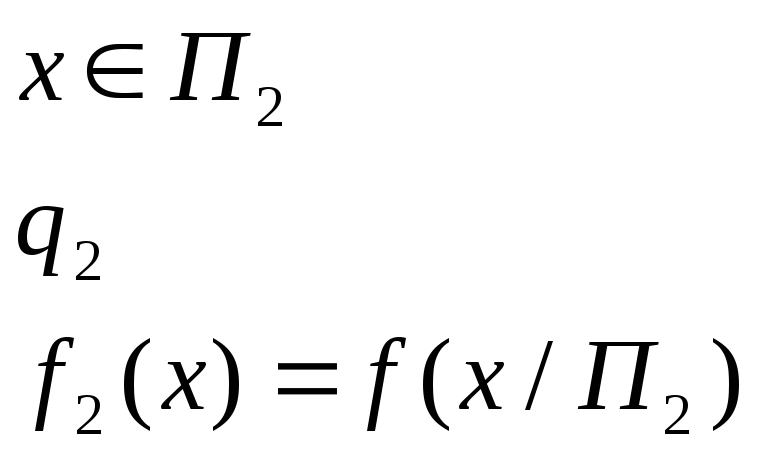
Стоимости ошибок:
С(1/2) и С(2/1)
![]() Задача
состоит в разбиении пространства X
на классы
множества X1
и X2,
соответствующие
заданным классам. Рассмотрим эту задачу
как оптимизационную с точки зрения
минимизации среднего риска принятия
неправильного решения.
Задача
состоит в разбиении пространства X
на классы
множества X1
и X2,
соответствующие
заданным классам. Рассмотрим эту задачу
как оптимизационную с точки зрения
минимизации среднего риска принятия
неправильного решения.
Введем функционал качества как оценку среднего риска:
![]() -
это общие средние потери при принятии
решения.
-
это общие средние потери при принятии
решения.
![]() Требуется
найти такое разбиение пространства ,
которое дает
Требуется
найти такое разбиение пространства ,
которое дает
![]() - эту величину нужно определить для
решения нашей задачи.
- эту величину нужно определить для
решения нашей задачи.
![]()
Заменим
![]()
![]() (на интеграл по областиX1)
и приведем к более простой форме:
(на интеграл по областиX1)
и приведем к более простой форме:

Обозначим
(*)=![]()
Данное
выражение необходимо минимизировать
при помощи выбора области
![]()
Область
![]() определяют
таким образом, чтобы выражение (*) было
определяют
таким образом, чтобы выражение (*) было![]() .
.
![]()
![]()
далее мы получаем следующее выражение для минимального риска:
![]()
![]()
![]()
![]() ,
то есть получаем, что
,
то есть получаем, что
![]() относится к генеральной совокупности
относится к генеральной совокупности![]()
Область
![]() имеет следующий вид:
имеет следующий вид:
![]()
![]()
![]()
![]()
Это правило для полного байесовского риска.
![]() -
эта функция называется отношением
правдоподобия.
-
эта функция называется отношением
правдоподобия.
Введем
порог:
![]() ,
тогда решающее правило принимает вид:
,
тогда решающее правило принимает вид:

![]()
Часто априорные вероятности неизвестны и их нужно как-то оценить.
Стоимость ошибки – величина субъективная.
Когда ошибки не заданы, мы можем построить более простое решающее правило на основе теоремы Байеса
![]() -
совместная функция распределения
-
совместная функция распределения
По теореме Байеса, можно разложить совместную плотность распределения:
![]()
Из данного разложения мы можем получить:
![]() -
это апостериорная вероятность того,
что
-
это апостериорная вероятность того,
что
![]() относится к
относится к![]()
![]() -
априорная вероятность
-
априорная вероятность
Чтобы
использовать данное правило необходимо
вычислить безусловную плотность
вероятности![]() . Легко показать , что она имеет вид
. Легко показать , что она имеет вид
![]() (
это результат интегрирования)
(
это результат интегрирования)
Отсюда следует, что правило принятия решения сводится к нахождению:
![]() ,
,
То есть номер класса равен:
![]()
Для
![]() (случай двух классов), правило решения
принимает вид:
(случай двух классов), правило решения
принимает вид:

![]()
![]()
Таким образом, мы получили отношение правдоподобия:
![]()
![]()
разница с предыдущим случаем в том, что из этого решения исчезла стоимость ошибок. Здесь ошибки находятся в следующем соотношении:
C(2/1) = C(1/2) - они равны.
Следовательно, нами получен метод принятия решений, основанный на вычислении апостериорных вероятностей
