

2. Классификация данных.
2.1. Постановка задачи
Рассматриваем матрицу данных:
x
![]()



 классы
классы
Мы должны каким-то образом разбить ее на классы. Эквивалентом термина классификация является распознавание образов.
Методы классификации используются для распознавания:
изображений;
речи;
букв;
Классификация данных: предполагается, что есть объект, описанный набором признаков:

в конечномерном пространстве Rn(можно решать задачу и в бесконечно-мерном пространстве , например, используя в качестве признаков коэффициенты ряда Фурье)
![]() .
.
Множество классов D представляет собой перечень возможных классов
![]() ,
,
где:
![]() определяют совокупность классов
определяют совокупность классов![]() .
.
Возможны следующие варианты:
![]()
![]() ,
то есть все задачи будем рассматривать
в
,
то есть все задачи будем рассматривать
в![]() .
Пусть имеется разбиение на классы:
.
Пусть имеется разбиение на классы:
![]()
Можно предполагать, что
![]() при
при![]() , то есть множества классов не пересекаются,
такую задачу мы хотим иметь, но чаще
всего это не наблюдается.
, то есть множества классов не пересекаются,
такую задачу мы хотим иметь, но чаще
всего это не наблюдается.




Часто имеет место
![]() ,
-это относится скорее к детерминированной
модели, когда множество классов не
покрывает все пространство
,
-это относится скорее к детерминированной
модели, когда множество классов не
покрывает все пространство
Если
![]() - такая ситуация тоже может быть, то
есть признаки покрывают все пространство.
- такая ситуация тоже может быть, то
есть признаки покрывают все пространство.
Для каждого
![]() мы должны найти некотороеdi,
которое определяется следующим образом:
мы должны найти некотороеdi,
которое определяется следующим образом:
![]() .
Задача состоит в построении такой
функции
.
Задача состоит в построении такой
функции
![]() и определенииdi.
Решение может быть однозначным
или неоднозначным. Такая функция
называется решающей.
и определенииdi.
Решение может быть однозначным
или неоднозначным. Такая функция
называется решающей.
Можно сформулировать следующую задачу: найти обратную функцию, порождающую для каждого номера (названия) соответствующее множество:
![]() ,
,
Эта функция должна порождать множество
![]() ,
которое соответствует определению
,
которое соответствует определению
класса di..
Идеальный вариант, когда выполнено
следующее:![]() ,
то есть совпадает с истинным множеством
класса, но чаще всего это не наблюдается.
,
то есть совпадает с истинным множеством
класса, но чаще всего это не наблюдается.
Р
 ешающая
функцияx2
ешающая
функцияx2
![]()



x1
Задача состоит в построении решающих функции.
Термин обучение заключается в следующем: есть обучающие выборки
![]() ,…,
,…,![]() ,…,
,…,![]() то
есть мы располагаем некоторыми конечными
множествами. Предварительно мы знаем,
куда относится какой-либо объект, нам
нужно построить конкретную решающую
функцию из
то
есть мы располагаем некоторыми конечными
множествами. Предварительно мы знаем,
куда относится какой-либо объект, нам
нужно построить конкретную решающую
функцию из![]() ,которая
будет удовлетворять определенным
критериям и
,которая
будет удовлетворять определенным
критериям и![]() (то
есть дает определенное решение).
(то
есть дает определенное решение).
Типы решающих функций:
Разбиение на 2 класса
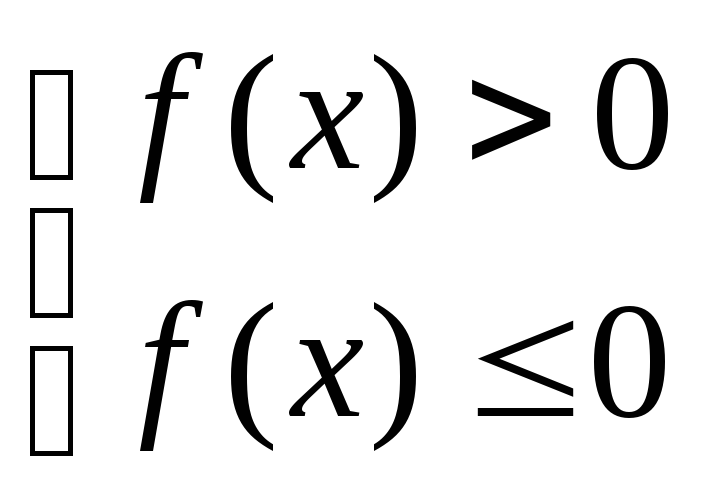
![]()
Если классов много, можно строить следующую функцию:
m– число классов
fi(x)i= 1..m
можно построить mрешающих функций и решение принимает следующий вид:















 Гауссовские функции
Гауссовские функции
То есть каждому классу сопоставляется Гауссовская функция.
![]()
Функции второго типа очень просто переходят в функции первого типа.
![]()




![]()
![]()





пустая область

![]()
![]()
Введем понятие границы между классами.
Граница между двумя классами определяется решающей функцией, разделяющей два этих класса fij(x)=0,соответственно:
f12(x)=0;
f23(x)=0;
f13(x)=0;
1-й класс может быть выбран следующим образом: очерчен на рис.(см. выше) жирной линией.
Оптимизационная задача
Наша задача заключается в том, чтобы построить класс функций, которые удовлетворяют некоторым критериям. Критериями могут быть
А) средние ошибки в результате классификации
Б) средний риск
В) получение на некотором множестве минимальное количество ошибок
Если имеется
![]() функционал
качества, то решается задача–
минимизировать функционал качества,
то есть найти
функционал
качества, то решается задача–
минимизировать функционал качества,
то есть найти![]() .
.
Пусть f– функция
определенного вида:
![]() ,
гдеai– параметры. То есть
,
гдеai– параметры. То есть
fможно задать параметрически и соответственно функционал качества имеет вид
![]() .
.
Таким образом, задача оптимизации
сводится к поиску
![]() .
Она может быть решена так:
.
Она может быть решена так:
![]() ,
где
,
где
![]() градиент
градиент
Существует много видов решения задач минимизации: градиентного спуска и т.д.
Существуют следующие виды параметрических функций f: